 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhiheng Ma
Few-shot Online Anomaly Detection and Segmentation
Mar 27, 2024
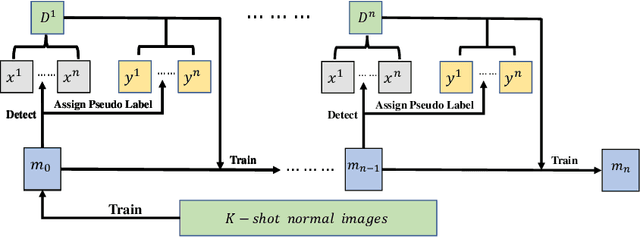


Detecting anomaly patterns from images is a crucial artificial intelligence technique in industrial applications. Recent research in this domain has emphasized the necessity of a large volume of training data, overlooking the practical scenario where, post-deployment of the model, unlabeled data containing both normal and abnormal samples can be utilized to enhance the model's performance. Consequently, this paper focuses on addressing the challenging yet practical few-shot online anomaly detection and segmentation (FOADS) task. Under the FOADS framework, models are trained on a few-shot normal dataset, followed by inspection and improvement of their capabilities by leveraging unlabeled streaming data containing both normal and abnormal samples simultaneously. To tackle this issue, we propose modeling the feature distribution of normal images using a Neural Gas network, which offers the flexibility to adapt the topology structure to identify outliers in the data flow. In order to achieve improved performance with limited training samples, we employ multi-scale feature embedding extracted from a CNN pre-trained on ImageNet to obtain a robust representation. Furthermore, we introduce an algorithm that can incrementally update parameters without the need to store previous samples. Comprehensive experimental results demonstrate that our method can achieve substantial performance under the FOADS setting, while ensuring that the time complexity remains within an acceptable range on MVTec AD and BTAD datasets.
Semi-supervised Counting via Pixel-by-pixel Density Distribution Modelling
Feb 23, 2024This paper focuses on semi-supervised crowd counting, where only a small portion of the training data are labeled. We formulate the pixel-wise density value to regress as a probability distribution, instead of a single deterministic value. On this basis, we propose a semi-supervised crowd-counting model. Firstly, we design a pixel-wise distribution matching loss to measure the differences in the pixel-wise density distributions between the prediction and the ground truth; Secondly, we enhance the transformer decoder by using density tokens to specialize the forwards of decoders w.r.t. different density intervals; Thirdly, we design the interleaving consistency self-supervised learning mechanism to learn from unlabeled data efficiently. Extensive experiments on four datasets are performed to show that our method clearly outperforms the competitors by a large margin under various labeled ratio settings. Code will be released at https://github.com/LoraLinH/Semi-supervised-Counting-via-Pixel-by-pixel-Density-Distribution-Modelling.
Gramformer: Learning Crowd Counting via Graph-Modulated Transformer
Jan 08, 2024Transformer has been popular in recent crowd counting work since it breaks the limited receptive field of traditional CNNs. However, since crowd images always contain a large number of similar patches, the self-attention mechanism in Transformer tends to find a homogenized solution where the attention maps of almost all patches are identical. In this paper, we address this problem by proposing Gramformer: a graph-modulated transformer to enhance the network by adjusting the attention and input node features respectively on the basis of two different types of graphs. Firstly, an attention graph is proposed to diverse attention maps to attend to complementary information. The graph is building upon the dissimilarities between patches, modulating the attention in an anti-similarity fashion. Secondly, a feature-based centrality encoding is proposed to discover the centrality positions or importance of nodes. We encode them with a proposed centrality indices scheme to modulate the node features and similarity relationships. Extensive experiments on four challenging crowd counting datasets have validated the competitiveness of the proposed method. Code is available at {https://github.com/LoraLinH/Gramformer}.
Linguistic Profiling of Deepfakes: An Open Database for Next-Generation Deepfake Detection
Jan 04, 2024The emergence of text-to-image generative models has revolutionized the field of deepfakes, enabling the creation of realistic and convincing visual content directly from textual descriptions. However, this advancement presents considerably greater challenges in detecting the authenticity of such content. Existing deepfake detection datasets and methods often fall short in effectively capturing the extensive range of emerging deepfakes and offering satisfactory explanatory information for detection. To address the significant issue, this paper introduces a deepfake database (DFLIP-3K) for the development of convincing and explainable deepfake detection. It encompasses about 300K diverse deepfake samples from approximately 3K generative models, which boasts the largest number of deepfake models in the literature. Moreover, it collects around 190K linguistic footprints of these deepfakes. The two distinguished features enable DFLIP-3K to develop a benchmark that promotes progress in linguistic profiling of deepfakes, which includes three sub-tasks namely deepfake detection, model identification, and prompt prediction. The deepfake model and prompt are two essential components of each deepfake, and thus dissecting them linguistically allows for an invaluable exploration of trustworthy and interpretable evidence in deepfake detection, which we believe is the key for the next-generation deepfake detection. Furthermore, DFLIP-3K is envisioned as an open database that fosters transparency and encourages collaborative efforts to further enhance its growth. Our extensive experiments on the developed benchmark verify that our DFLIP-3K database is capable of serving as a standardized resource for evaluating and comparing linguistic-based deepfake detection, identification, and prompt prediction techniques.
Can SAM Count Anything? An Empirical Study on SAM Counting
Apr 21, 2023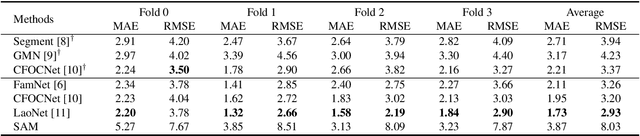

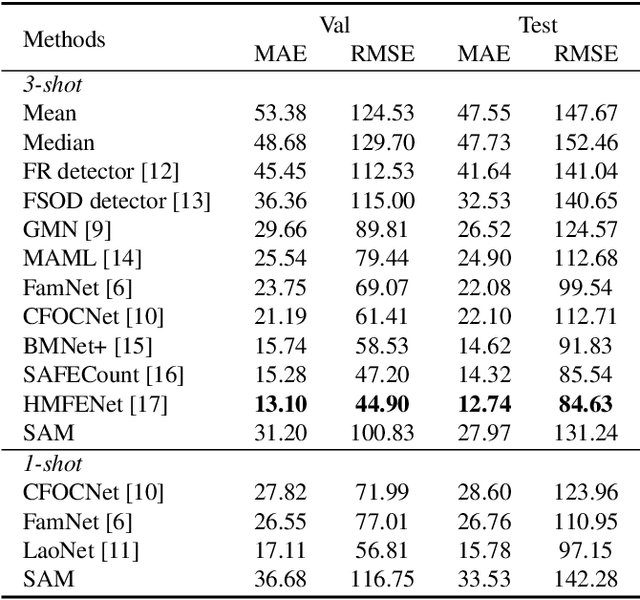
Meta AI recently released the Segment Anything model (SAM), which has garnered attention due to its impressive performance in class-agnostic segmenting. In this study, we explore the use of SAM for the challenging task of few-shot object counting, which involves counting objects of an unseen category by providing a few bounding boxes of examples. We compare SAM's performance with other few-shot counting methods and find that it is currently unsatisfactory without further fine-tuning, particularly for small and crowded objects. Code can be found at \url{https://github.com/Vision-Intelligence-and-Robots-Group/count-anything}.
Towards Practical Multi-Robot Hybrid Tasks Allocation for Autonomous Cleaning
Apr 04, 2023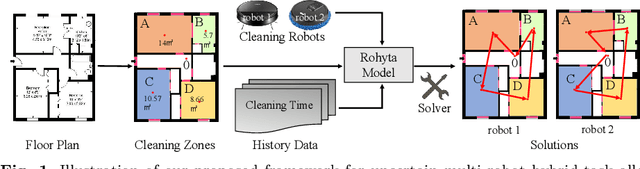

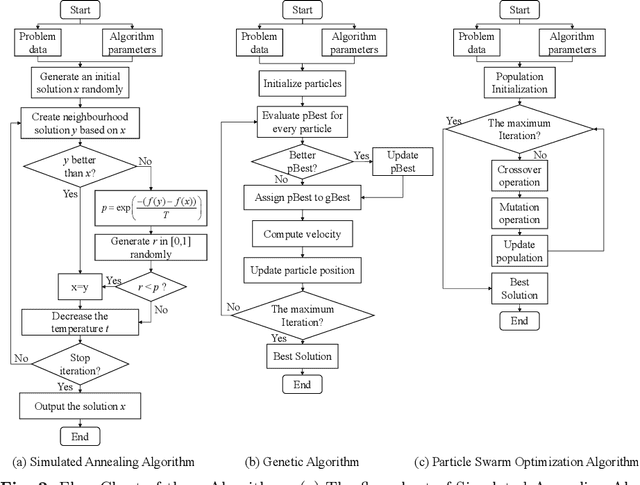
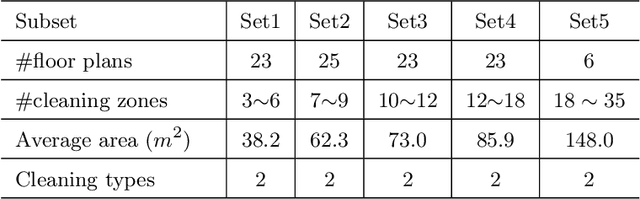
Task allocation plays a vital role in multi-robot autonomous cleaning systems, where multiple robots work together to clean a large area. However, most current studies mainly focus on deterministic, single-task allocation for cleaning robots, without considering hybrid tasks in uncertain working environments. Moreover, there is a lack of datasets and benchmarks for relevant research. In this paper, to address these problems, we formulate multi-robot hybrid-task allocation under the uncertain cleaning environment as a robust optimization problem. Firstly, we propose a novel robust mixed-integer linear programming model with practical constraints including the task order constraint for different tasks and the ability constraints of hybrid robots. Secondly, we establish a dataset of \emph{100} instances made from floor plans, each of which has 2D manually-labeled images and a 3D model. Thirdly, we provide comprehensive results on the collected dataset using three traditional optimization approaches and a deep reinforcement learning-based solver. The evaluation results show that our solution meets the needs of multi-robot cleaning task allocation and the robust solver can protect the system from worst-case scenarios with little additional cost. The benchmark will be available at {https://github.com/iamwangyabin/Multi-robot-Cleaning-Task-Allocation}.
Remind of the Past: Incremental Learning with Analogical Prompts
Mar 24, 2023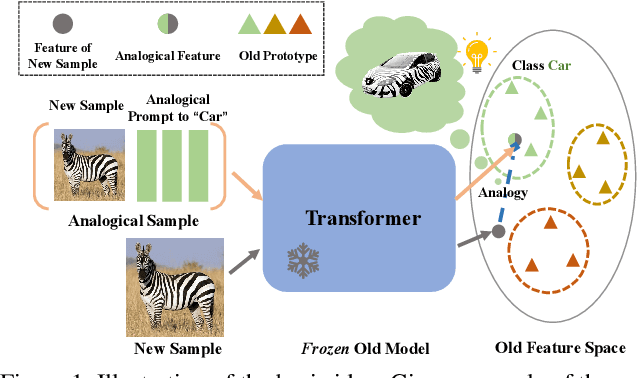
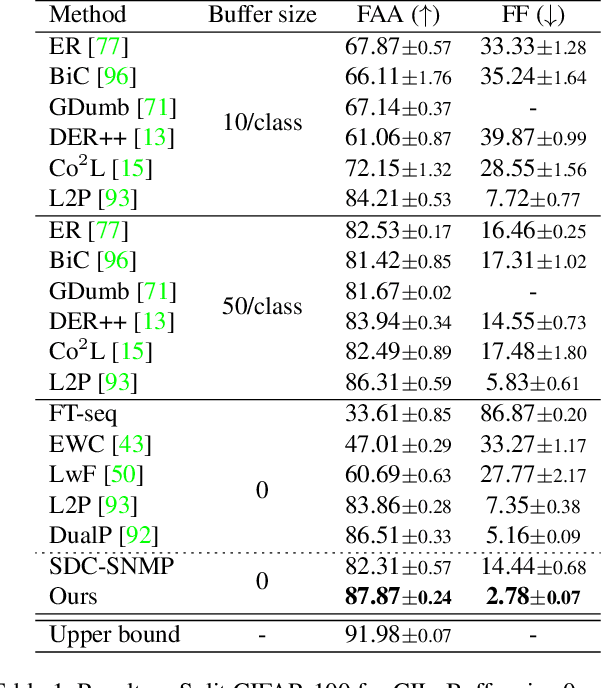
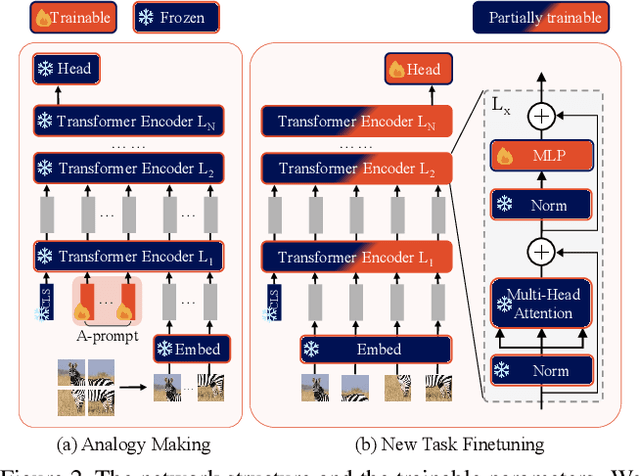
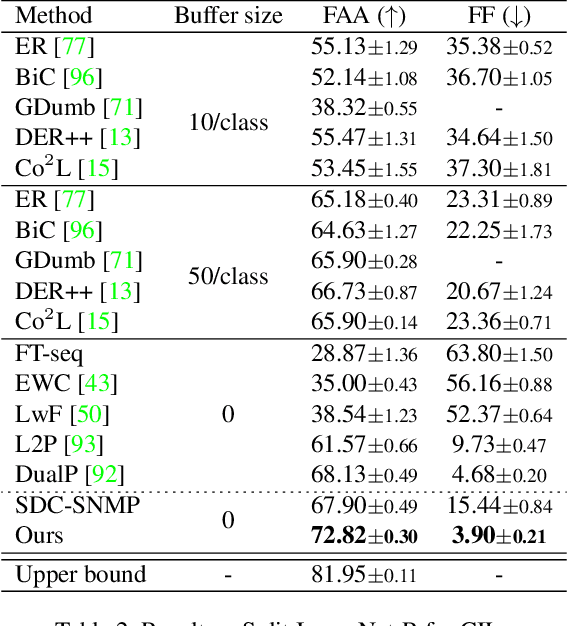
Although data-free incremental learning methods are memory-friendly, accurately estimating and counteracting representation shifts is challenging in the absence of historical data. This paper addresses this thorny problem by proposing a novel incremental learning method inspired by human analogy capabilities. Specifically, we design an analogy-making mechanism to remap the new data into the old class by prompt tuning. It mimics the feature distribution of the target old class on the old model using only samples of new classes. The learnt prompts are further used to estimate and counteract the representation shift caused by fine-tuning for the historical prototypes. The proposed method sets up new state-of-the-art performance on four incremental learning benchmarks under both the class and domain incremental learning settings. It consistently outperforms data-replay methods by only saving feature prototypes for each class. It has almost hit the empirical upper bound by joint training on the Core50 benchmark. The code will be released at \url{https://github.com/ZhihengCV/A-Prompts}.
Isolation and Impartial Aggregation: A Paradigm of Incremental Learning without Interference
Nov 29, 2022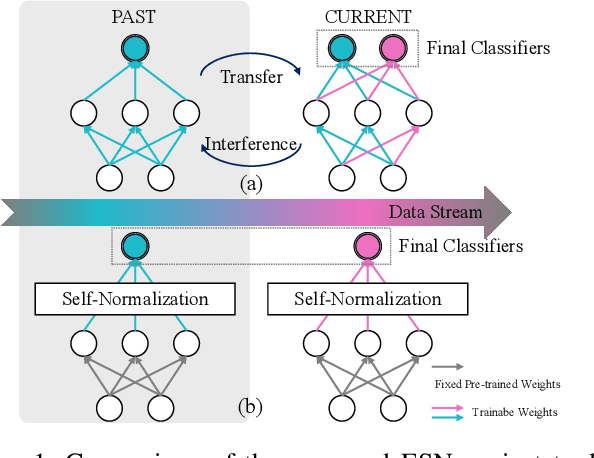
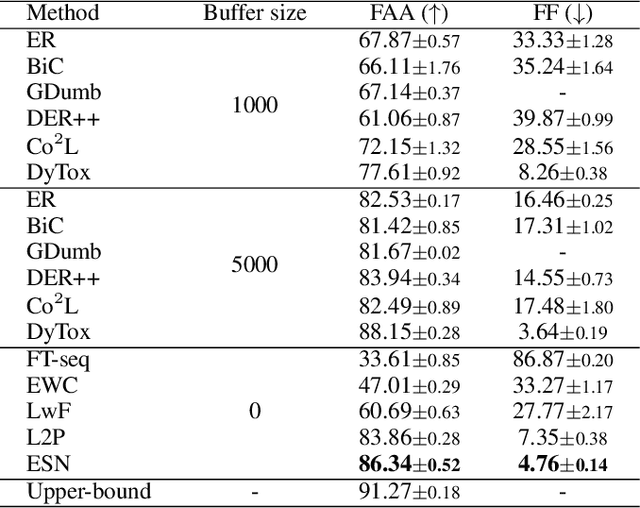
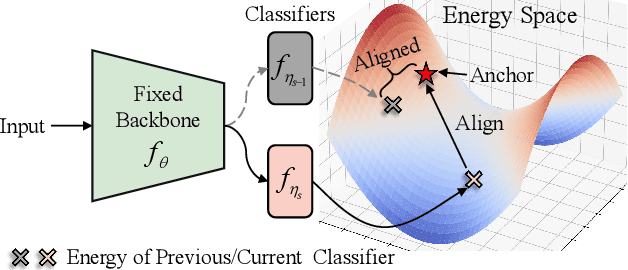
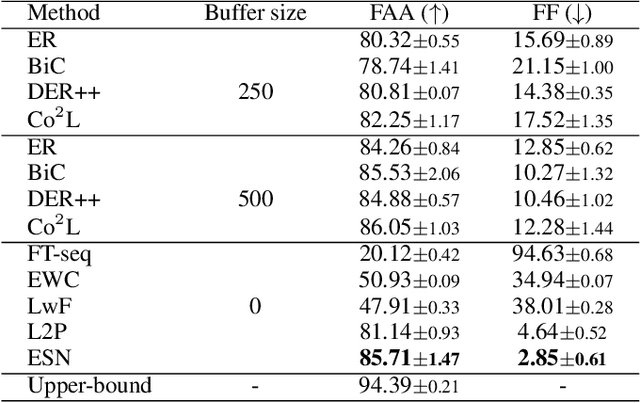
This paper focuses on the prevalent performance imbalance in the stages of incremental learning. To avoid obvious stage learning bottlenecks, we propose a brand-new stage-isolation based incremental learning framework, which leverages a series of stage-isolated classifiers to perform the learning task of each stage without the interference of others. To be concrete, to aggregate multiple stage classifiers as a uniform one impartially, we first introduce a temperature-controlled energy metric for indicating the confidence score levels of the stage classifiers. We then propose an anchor-based energy self-normalization strategy to ensure the stage classifiers work at the same energy level. Finally, we design a voting-based inference augmentation strategy for robust inference. The proposed method is rehearsal free and can work for almost all continual learning scenarios. We evaluate the proposed method on four large benchmarks. Extensive results demonstrate the superiority of the proposed method in setting up new state-of-the-art overall performance. \emph{Code is available at} \url{https://github.com/iamwangyabin/ESN}.
Semi-supervised Crowd Counting via Density Agency
Sep 07, 2022
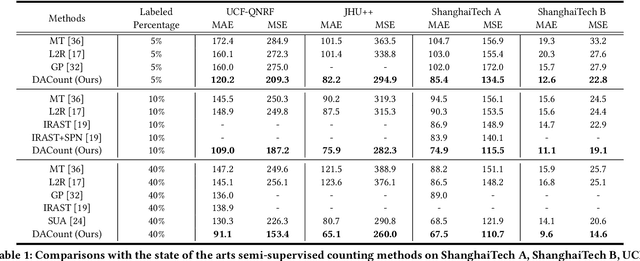
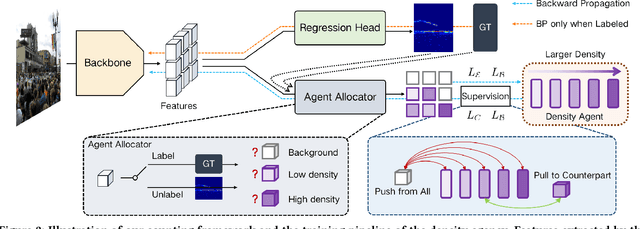
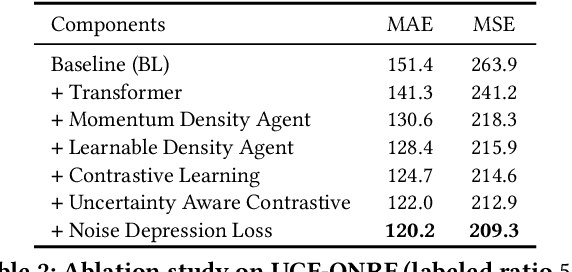
In this paper, we propose a new agency-guided semi-supervised counting approach. First, we build a learnable auxiliary structure, namely the density agency to bring the recognized foreground regional features close to corresponding density sub-classes (agents) and push away background ones. Second, we propose a density-guided contrastive learning loss to consolidate the backbone feature extractor. Third, we build a regression head by using a transformer structure to refine the foreground features further. Finally, an efficient noise depression loss is provided to minimize the negative influence of annotation noises. Extensive experiments on four challenging crowd counting datasets demonstrate that our method achieves superior performance to the state-of-the-art semi-supervised counting methods by a large margin. Code is available.
Boosting Crowd Counting via Multifaceted Attention
Mar 05, 2022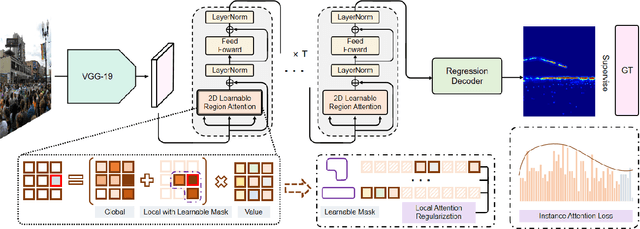
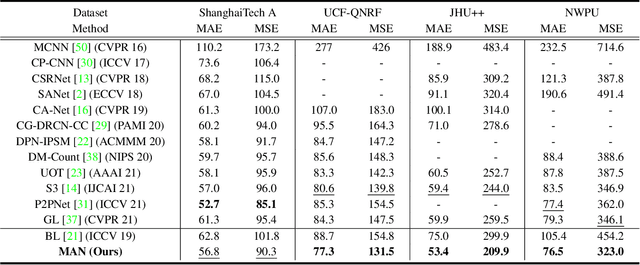


This paper focuses on the challenging crowd counting task. As large-scale variations often exist within crowd images, neither fixed-size convolution kernel of CNN nor fixed-size attention of recent vision transformers can well handle this kind of variation. To address this problem, we propose a Multifaceted Attention Network (MAN) to improve transformer models in local spatial relation encoding. MAN incorporates global attention from a vanilla transformer, learnable local attention, and instance attention into a counting model. Firstly, the local Learnable Region Attention (LRA) is proposed to assign attention exclusively for each feature location dynamically. Secondly, we design the Local Attention Regularization to supervise the training of LRA by minimizing the deviation among the attention for different feature locations. Finally, we provide an Instance Attention mechanism to focus on the most important instances dynamically during training. Extensive experiments on four challenging crowd counting datasets namely ShanghaiTech, UCF-QNRF, JHU++, and NWPU have validated the proposed method. Codes: https://github.com/LoraLinH/Boosting-Crowd-Counting-via-Multifaceted-Attention.