 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShaochen Zhang
Few-shot Online Anomaly Detection and Segmentation
Mar 27, 2024
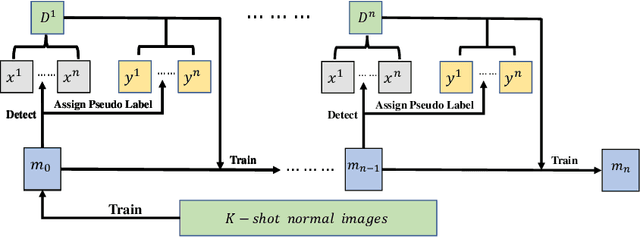
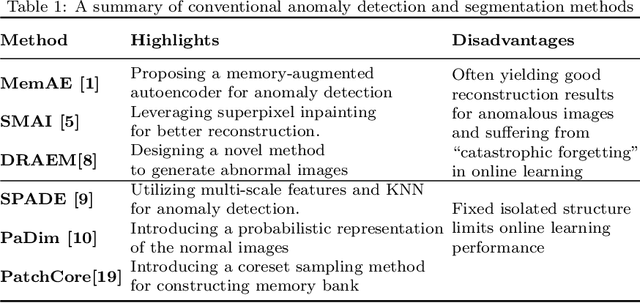


Detecting anomaly patterns from images is a crucial artificial intelligence technique in industrial applications. Recent research in this domain has emphasized the necessity of a large volume of training data, overlooking the practical scenario where, post-deployment of the model, unlabeled data containing both normal and abnormal samples can be utilized to enhance the model's performance. Consequently, this paper focuses on addressing the challenging yet practical few-shot online anomaly detection and segmentation (FOADS) task. Under the FOADS framework, models are trained on a few-shot normal dataset, followed by inspection and improvement of their capabilities by leveraging unlabeled streaming data containing both normal and abnormal samples simultaneously. To tackle this issue, we propose modeling the feature distribution of normal images using a Neural Gas network, which offers the flexibility to adapt the topology structure to identify outliers in the data flow. In order to achieve improved performance with limited training samples, we employ multi-scale feature embedding extracted from a CNN pre-trained on ImageNet to obtain a robust representation. Furthermore, we introduce an algorithm that can incrementally update parameters without the need to store previous samples. Comprehensive experimental results demonstrate that our method can achieve substantial performance under the FOADS setting, while ensuring that the time complexity remains within an acceptable range on MVTec AD and BTAD datasets.
ShapeLLM: Universal 3D Object Understanding for Embodied Interaction
Mar 06, 2024



This paper presents ShapeLLM, the first 3D Multimodal Large Language Model (LLM) designed for embodied interaction, exploring a universal 3D object understanding with 3D point clouds and languages. ShapeLLM is built upon an improved 3D encoder by extending ReCon to ReCon++ that benefits from multi-view image distillation for enhanced geometry understanding. By utilizing ReCon++ as the 3D point cloud input encoder for LLMs, ShapeLLM is trained on constructed instruction-following data and tested on our newly human-curated evaluation benchmark, 3D MM-Vet. ReCon++ and ShapeLLM achieve state-of-the-art performance in 3D geometry understanding and language-unified 3D interaction tasks, such as embodied visual grounding.