 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZheng Ge
Self-Supervised Visual Preference Alignment
Apr 16, 2024
This paper makes the first attempt towards unsupervised preference alignment in Vision-Language Models (VLMs). We generate chosen and rejected responses with regard to the original and augmented image pairs, and conduct preference alignment with direct preference optimization. It is based on a core idea: properly designed augmentation to the image input will induce VLM to generate false but hard negative responses, which helps the model to learn from and produce more robust and powerful answers. The whole pipeline no longer hinges on supervision from GPT4 or human involvement during alignment, and is highly efficient with few lines of code. With only 8k randomly sampled unsupervised data, it achieves 90\% relative score to GPT-4 on complex reasoning in LLaVA-Bench, and improves LLaVA-7B/13B by 6.7\%/5.6\% score on complex multi-modal benchmark MM-Vet. Visualizations shows its improved ability to align with user-intentions. A series of ablations are firmly conducted to reveal the latent mechanism of the approach, which also indicates its potential towards further scaling. Code will be available.
OneChart: Purify the Chart Structural Extraction via One Auxiliary Token
Apr 15, 2024



Chart parsing poses a significant challenge due to the diversity of styles, values, texts, and so forth. Even advanced large vision-language models (LVLMs) with billions of parameters struggle to handle such tasks satisfactorily. To address this, we propose OneChart: a reliable agent specifically devised for the structural extraction of chart information. Similar to popular LVLMs, OneChart incorporates an autoregressive main body. Uniquely, to enhance the reliability of the numerical parts of the output, we introduce an auxiliary token placed at the beginning of the total tokens along with an additional decoder. The numerically optimized (auxiliary) token allows subsequent tokens for chart parsing to capture enhanced numerical features through causal attention. Furthermore, with the aid of the auxiliary token, we have devised a self-evaluation mechanism that enables the model to gauge the reliability of its chart parsing results by providing confidence scores for the generated content. Compared to current state-of-the-art (SOTA) chart parsing models, e.g., DePlot, ChartVLM, ChartAst, OneChart significantly outperforms in Average Precision (AP) for chart structural extraction across multiple public benchmarks, despite enjoying only 0.2 billion parameters. Moreover, as a chart parsing agent, it also brings 10%+ accuracy gains for the popular LVLM (LLaVA-1.6) in the downstream ChartQA benchmark.
ShapeLLM: Universal 3D Object Understanding for Embodied Interaction
Mar 06, 2024



This paper presents ShapeLLM, the first 3D Multimodal Large Language Model (LLM) designed for embodied interaction, exploring a universal 3D object understanding with 3D point clouds and languages. ShapeLLM is built upon an improved 3D encoder by extending ReCon to ReCon++ that benefits from multi-view image distillation for enhanced geometry understanding. By utilizing ReCon++ as the 3D point cloud input encoder for LLMs, ShapeLLM is trained on constructed instruction-following data and tested on our newly human-curated evaluation benchmark, 3D MM-Vet. ReCon++ and ShapeLLM achieve state-of-the-art performance in 3D geometry understanding and language-unified 3D interaction tasks, such as embodied visual grounding.
Small Language Model Meets with Reinforced Vision Vocabulary
Jan 23, 2024Playing Large Vision Language Models (LVLMs) in 2023 is trendy among the AI community. However, the relatively large number of parameters (more than 7B) of popular LVLMs makes it difficult to train and deploy on consumer GPUs, discouraging many researchers with limited resources. Imagine how cool it would be to experience all the features of current LVLMs on an old GTX1080ti (our only game card). Accordingly, we present Vary-toy in this report, a small-size Vary along with Qwen-1.8B as the base ``large'' language model. In Vary-toy, we introduce an improved vision vocabulary, allowing the model to not only possess all features of Vary but also gather more generality. Specifically, we replace negative samples of natural images with positive sample data driven by object detection in the procedure of generating vision vocabulary, more sufficiently utilizing the capacity of the vocabulary network and enabling it to efficiently encode visual information corresponding to natural objects. For experiments, Vary-toy can achieve 65.6% ANLS on DocVQA, 59.1% accuracy on ChartQA, 88.1% accuracy on RefCOCO, and 29% on MMVet. The code will be publicly available on the homepage.
Vary: Scaling up the Vision Vocabulary for Large Vision-Language Models
Dec 11, 2023



Modern Large Vision-Language Models (LVLMs) enjoy the same vision vocabulary -- CLIP, which can cover most common vision tasks. However, for some special vision task that needs dense and fine-grained vision perception, e.g., document-level OCR or chart understanding, especially in non-English scenarios, the CLIP-style vocabulary may encounter low efficiency in tokenizing the vision knowledge and even suffer out-of-vocabulary problem. Accordingly, we propose Vary, an efficient and effective method to scale up the vision vocabulary of LVLMs. The procedures of Vary are naturally divided into two folds: the generation and integration of a new vision vocabulary. In the first phase, we devise a vocabulary network along with a tiny decoder-only transformer to produce the desired vocabulary via autoregression. In the next, we scale up the vanilla vision vocabulary by merging the new one with the original one (CLIP), enabling the LVLMs can quickly garner new features. Compared to the popular BLIP-2, MiniGPT4, and LLaVA, Vary can maintain its vanilla capabilities while enjoying more excellent fine-grained perception and understanding ability. Specifically, Vary is competent in new document parsing features (OCR or markdown conversion) while achieving 78.2% ANLS in DocVQA and 36.2% in MMVet. Our code will be publicly available on the homepage.
Merlin:Empowering Multimodal LLMs with Foresight Minds
Nov 30, 2023Humans possess the remarkable ability to foresee the future to a certain extent based on present observations, a skill we term as foresight minds. However, this capability remains largely under explored within existing Multimodal Large Language Models (MLLMs), hindering their capacity to learn the fundamental principles of how things operate and the intentions behind the observed subjects. To address this issue, we introduce the integration of future modeling into the existing learning frameworks of MLLMs. By utilizing the subject trajectory, a highly structured representation of a consecutive frame sequence, as a learning objective, we aim to bridge the gap between the past and the future. We propose two innovative methods to empower MLLMs with foresight minds, Foresight Pre-Training (FPT) and Foresight Instruction-Tuning (FIT), which are inspired by the modern learning paradigm of LLMs. Specifically, FPT jointly training various tasks centered on trajectories, enabling MLLMs to learn how to attend and predict entire trajectories from a given initial observation. Then, FIT requires MLLMs to first predict trajectories of related objects and then reason about potential future events based on them. Aided by FPT and FIT, we build a novel and unified MLLM named Merlin that supports multi-images input and analysis about potential actions of multiple objects for the future reasoning. Experimental results show Merlin powerful foresight minds with impressive performance on both future reasoning and visual comprehension tasks.
DreamLLM: Synergistic Multimodal Comprehension and Creation
Sep 20, 2023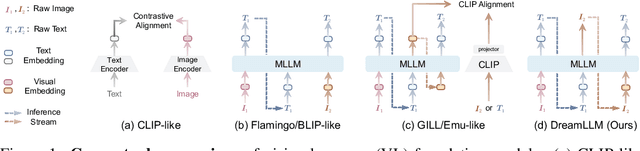
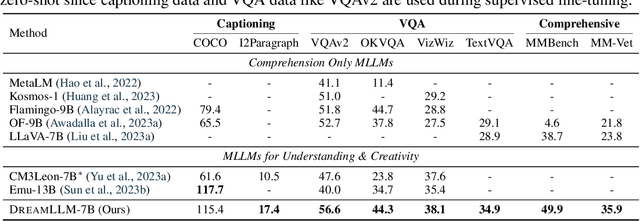
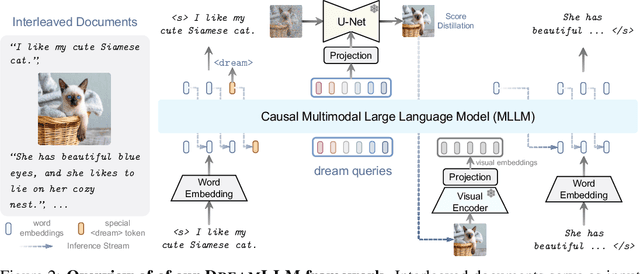
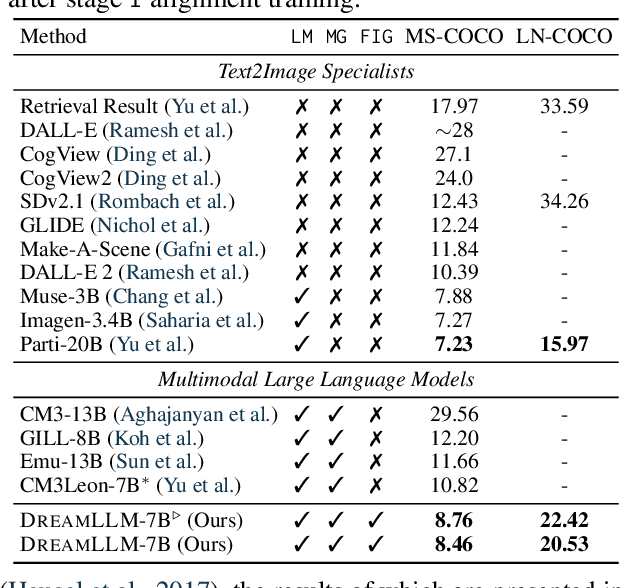
This paper presents DreamLLM, a learning framework that first achieves versatile Multimodal Large Language Models (MLLMs) empowered with frequently overlooked synergy between multimodal comprehension and creation. DreamLLM operates on two fundamental principles. The first focuses on the generative modeling of both language and image posteriors by direct sampling in the raw multimodal space. This approach circumvents the limitations and information loss inherent to external feature extractors like CLIP, and a more thorough multimodal understanding is obtained. Second, DreamLLM fosters the generation of raw, interleaved documents, modeling both text and image contents, along with unstructured layouts. This allows DreamLLM to learn all conditional, marginal, and joint multimodal distributions effectively. As a result, DreamLLM is the first MLLM capable of generating free-form interleaved content. Comprehensive experiments highlight DreamLLM's superior performance as a zero-shot multimodal generalist, reaping from the enhanced learning synergy.
GroupLane: End-to-End 3D Lane Detection with Channel-wise Grouping
Jul 18, 2023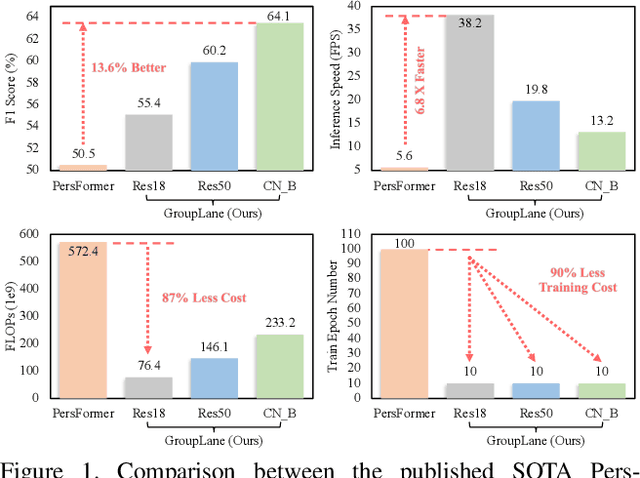
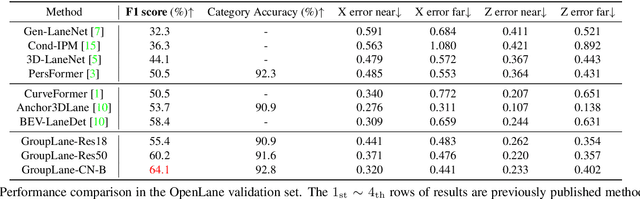

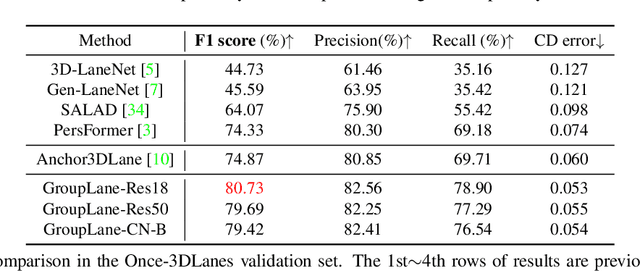
Efficiency is quite important for 3D lane detection due to practical deployment demand. In this work, we propose a simple, fast, and end-to-end detector that still maintains high detection precision. Specifically, we devise a set of fully convolutional heads based on row-wise classification. In contrast to previous counterparts, ours supports recognizing both vertical and horizontal lanes. Besides, our method is the first one to perform row-wise classification in bird-eye-view. In the heads, we split feature into multiple groups and every group of feature corresponds to a lane instance. During training, the predictions are associated with lane labels using the proposed single-win one-to-one matching to compute loss, and no post-processing operation is demanded for inference. In this way, our proposed fully convolutional detector, GroupLane, realizes end-to-end detection like DETR. Evaluated on 3 real world 3D lane benchmarks, OpenLane, Once-3DLanes, and OpenLane-Huawei, GroupLane adopting ConvNext-Base as the backbone outperforms the published state-of-the-art PersFormer by 13.6% F1 score in the OpenLane validation set. Besides, GroupLane with ResNet18 still surpasses PersFormer by 4.9% F1 score, while the inference speed is nearly 7x faster and the FLOPs is only 13.3% of it.
ChatSpot: Bootstrapping Multimodal LLMs via Precise Referring Instruction Tuning
Jul 18, 2023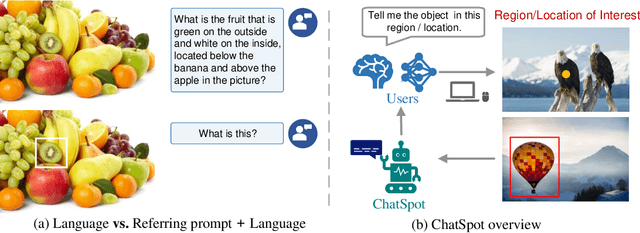

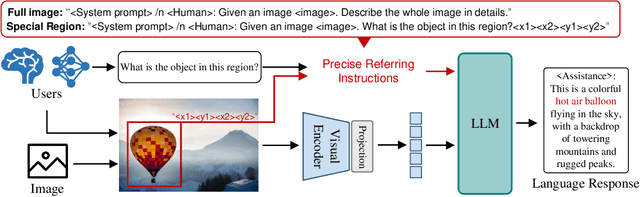

Human-AI interactivity is a critical aspect that reflects the usability of multimodal large language models (MLLMs). However, existing end-to-end MLLMs only allow users to interact with them through language instructions, leading to the limitation of the interactive accuracy and efficiency. In this study, we present precise referring instructions that utilize diverse reference representations such as points and boxes as referring prompts to refer to the special region. This enables MLLMs to focus on the region of interest and achieve finer-grained interaction. Based on precise referring instruction, we propose ChatSpot, a unified end-to-end multimodal large language model that supports diverse forms of interactivity including mouse clicks, drag-and-drop, and drawing boxes, which provides a more flexible and seamless interactive experience. We also construct a multi-grained vision-language instruction-following dataset based on existing datasets and GPT-4 generating. Furthermore, we design a series of evaluation tasks to assess the effectiveness of region recognition and interaction. Experimental results showcase ChatSpot's promising performance.
GMM: Delving into Gradient Aware and Model Perceive Depth Mining for Monocular 3D Detection
Jun 30, 2023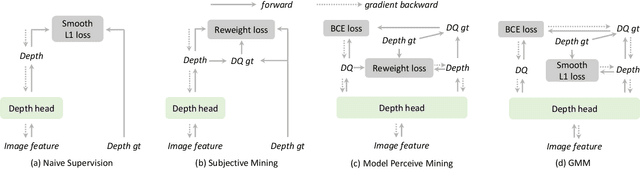
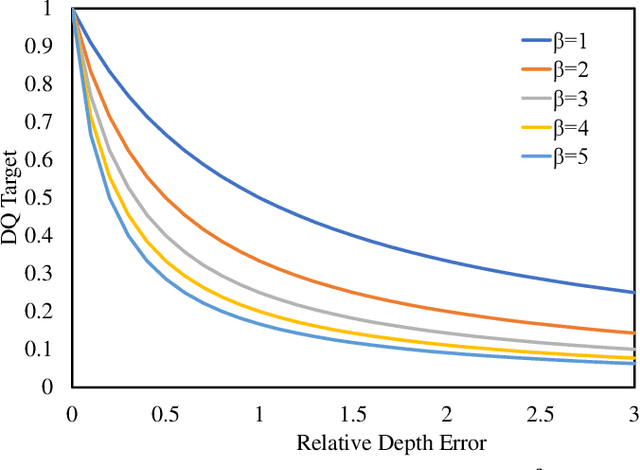

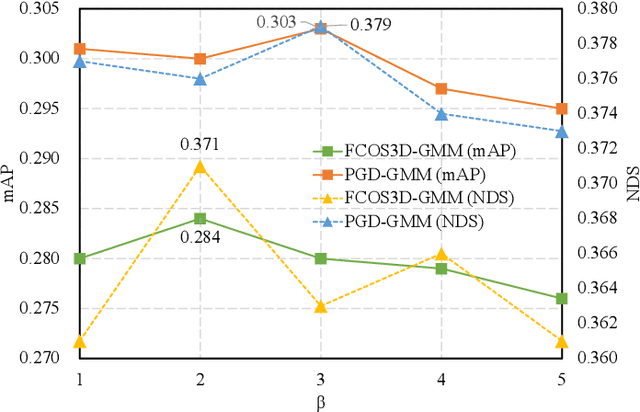
Depth perception is a crucial component of monoc-ular 3D detection tasks that typically involve ill-posed problems. In light of the success of sample mining techniques in 2D object detection, we propose a simple yet effective mining strategy for improving depth perception in 3D object detection. Concretely, we introduce a plain metric to evaluate the quality of depth predictions, which chooses the mined sample for the model. Moreover, we propose a Gradient-aware and Model-perceive Mining strategy (GMM) for depth learning, which exploits the predicted depth quality for better depth learning through easy mining. GMM is a general strategy that can be readily applied to several state-of-the-art monocular 3D detectors, improving the accuracy of depth prediction. Extensive experiments on the nuScenes dataset demonstrate that the proposed methods significantly improve the performance of 3D object detection while outperforming other state-of-the-art sample mining techniques by a considerable margin. On the nuScenes benchmark, GMM achieved the state-of-the-art (42.1% mAP and 47.3% NDS) performance in monocular object detection.