 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHaoran Wei
OneChart: Purify the Chart Structural Extraction via One Auxiliary Token
Apr 15, 2024
Chart parsing poses a significant challenge due to the diversity of styles, values, texts, and so forth. Even advanced large vision-language models (LVLMs) with billions of parameters struggle to handle such tasks satisfactorily. To address this, we propose OneChart: a reliable agent specifically devised for the structural extraction of chart information. Similar to popular LVLMs, OneChart incorporates an autoregressive main body. Uniquely, to enhance the reliability of the numerical parts of the output, we introduce an auxiliary token placed at the beginning of the total tokens along with an additional decoder. The numerically optimized (auxiliary) token allows subsequent tokens for chart parsing to capture enhanced numerical features through causal attention. Furthermore, with the aid of the auxiliary token, we have devised a self-evaluation mechanism that enables the model to gauge the reliability of its chart parsing results by providing confidence scores for the generated content. Compared to current state-of-the-art (SOTA) chart parsing models, e.g., DePlot, ChartVLM, ChartAst, OneChart significantly outperforms in Average Precision (AP) for chart structural extraction across multiple public benchmarks, despite enjoying only 0.2 billion parameters. Moreover, as a chart parsing agent, it also brings 10%+ accuracy gains for the popular LVLM (LLaVA-1.6) in the downstream ChartQA benchmark.
MegaScale: Scaling Large Language Model Training to More Than 10,000 GPUs
Feb 23, 2024We present the design, implementation and engineering experience in building and deploying MegaScale, a production system for training large language models (LLMs) at the scale of more than 10,000 GPUs. Training LLMs at this scale brings unprecedented challenges to training efficiency and stability. We take a full-stack approach that co-designs the algorithmic and system components across model block and optimizer design, computation and communication overlapping, operator optimization, data pipeline, and network performance tuning. Maintaining high efficiency throughout the training process (i.e., stability) is an important consideration in production given the long extent of LLM training jobs. Many hard stability issues only emerge at large scale, and in-depth observability is the key to address them. We develop a set of diagnosis tools to monitor system components and events deep in the stack, identify root causes, and derive effective techniques to achieve fault tolerance and mitigate stragglers. MegaScale achieves 55.2% Model FLOPs Utilization (MFU) when training a 175B LLM model on 12,288 GPUs, improving the MFU by 1.34x compared to Megatron-LM. We share our operational experience in identifying and fixing failures and stragglers. We hope by articulating the problems and sharing our experience from a systems perspective, this work can inspire future LLM systems research.
Small Language Model Meets with Reinforced Vision Vocabulary
Jan 23, 2024Playing Large Vision Language Models (LVLMs) in 2023 is trendy among the AI community. However, the relatively large number of parameters (more than 7B) of popular LVLMs makes it difficult to train and deploy on consumer GPUs, discouraging many researchers with limited resources. Imagine how cool it would be to experience all the features of current LVLMs on an old GTX1080ti (our only game card). Accordingly, we present Vary-toy in this report, a small-size Vary along with Qwen-1.8B as the base ``large'' language model. In Vary-toy, we introduce an improved vision vocabulary, allowing the model to not only possess all features of Vary but also gather more generality. Specifically, we replace negative samples of natural images with positive sample data driven by object detection in the procedure of generating vision vocabulary, more sufficiently utilizing the capacity of the vocabulary network and enabling it to efficiently encode visual information corresponding to natural objects. For experiments, Vary-toy can achieve 65.6% ANLS on DocVQA, 59.1% accuracy on ChartQA, 88.1% accuracy on RefCOCO, and 29% on MMVet. The code will be publicly available on the homepage.
Vary: Scaling up the Vision Vocabulary for Large Vision-Language Models
Dec 11, 2023Modern Large Vision-Language Models (LVLMs) enjoy the same vision vocabulary -- CLIP, which can cover most common vision tasks. However, for some special vision task that needs dense and fine-grained vision perception, e.g., document-level OCR or chart understanding, especially in non-English scenarios, the CLIP-style vocabulary may encounter low efficiency in tokenizing the vision knowledge and even suffer out-of-vocabulary problem. Accordingly, we propose Vary, an efficient and effective method to scale up the vision vocabulary of LVLMs. The procedures of Vary are naturally divided into two folds: the generation and integration of a new vision vocabulary. In the first phase, we devise a vocabulary network along with a tiny decoder-only transformer to produce the desired vocabulary via autoregression. In the next, we scale up the vanilla vision vocabulary by merging the new one with the original one (CLIP), enabling the LVLMs can quickly garner new features. Compared to the popular BLIP-2, MiniGPT4, and LLaVA, Vary can maintain its vanilla capabilities while enjoying more excellent fine-grained perception and understanding ability. Specifically, Vary is competent in new document parsing features (OCR or markdown conversion) while achieving 78.2% ANLS in DocVQA and 36.2% in MMVet. Our code will be publicly available on the homepage.
Merlin:Empowering Multimodal LLMs with Foresight Minds
Nov 30, 2023Humans possess the remarkable ability to foresee the future to a certain extent based on present observations, a skill we term as foresight minds. However, this capability remains largely under explored within existing Multimodal Large Language Models (MLLMs), hindering their capacity to learn the fundamental principles of how things operate and the intentions behind the observed subjects. To address this issue, we introduce the integration of future modeling into the existing learning frameworks of MLLMs. By utilizing the subject trajectory, a highly structured representation of a consecutive frame sequence, as a learning objective, we aim to bridge the gap between the past and the future. We propose two innovative methods to empower MLLMs with foresight minds, Foresight Pre-Training (FPT) and Foresight Instruction-Tuning (FIT), which are inspired by the modern learning paradigm of LLMs. Specifically, FPT jointly training various tasks centered on trajectories, enabling MLLMs to learn how to attend and predict entire trajectories from a given initial observation. Then, FIT requires MLLMs to first predict trajectories of related objects and then reason about potential future events based on them. Aided by FPT and FIT, we build a novel and unified MLLM named Merlin that supports multi-images input and analysis about potential actions of multiple objects for the future reasoning. Experimental results show Merlin powerful foresight minds with impressive performance on both future reasoning and visual comprehension tasks.
Autoencoder with Group-based Decoder and Multi-task Optimization for Anomalous Sound Detection
Nov 15, 2023In industry, machine anomalous sound detection (ASD) is in great demand. However, collecting enough abnormal samples is difficult due to the high cost, which boosts the rapid development of unsupervised ASD algorithms. Autoencoder (AE) based methods have been widely used for unsupervised ASD, but suffer from problems including 'shortcut', poor anti-noise ability and sub-optimal quality of features. To address these challenges, we propose a new AE-based framework termed AEGM. Specifically, we first insert an auxiliary classifier into AE to enhance ASD in a multi-task learning manner. Then, we design a group-based decoder structure, accompanied by an adaptive loss function, to endow the model with domain-specific knowledge. Results on the DCASE 2021 Task 2 development set show that our methods achieve a relative improvement of 13.11% and 15.20% respectively in average AUC over the official AE and MobileNetV2 across test sets of seven machines.
DreamLLM: Synergistic Multimodal Comprehension and Creation
Sep 20, 2023
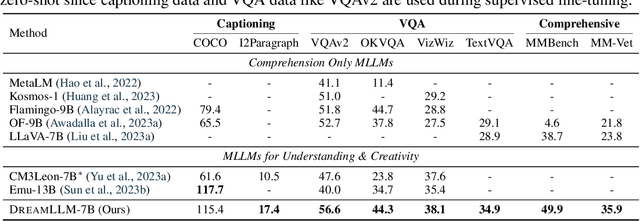
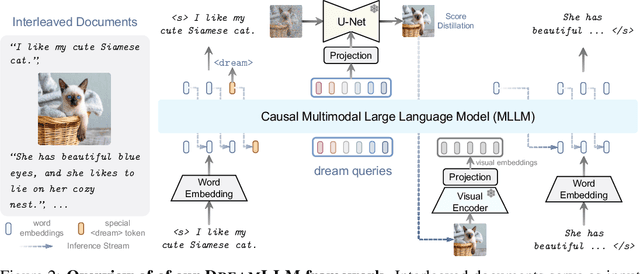
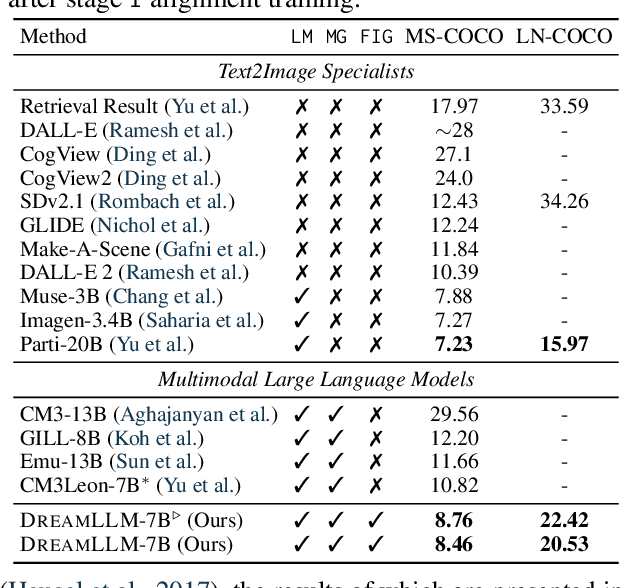
This paper presents DreamLLM, a learning framework that first achieves versatile Multimodal Large Language Models (MLLMs) empowered with frequently overlooked synergy between multimodal comprehension and creation. DreamLLM operates on two fundamental principles. The first focuses on the generative modeling of both language and image posteriors by direct sampling in the raw multimodal space. This approach circumvents the limitations and information loss inherent to external feature extractors like CLIP, and a more thorough multimodal understanding is obtained. Second, DreamLLM fosters the generation of raw, interleaved documents, modeling both text and image contents, along with unstructured layouts. This allows DreamLLM to learn all conditional, marginal, and joint multimodal distributions effectively. As a result, DreamLLM is the first MLLM capable of generating free-form interleaved content. Comprehensive experiments highlight DreamLLM's superior performance as a zero-shot multimodal generalist, reaping from the enhanced learning synergy.
ChatSpot: Bootstrapping Multimodal LLMs via Precise Referring Instruction Tuning
Jul 18, 2023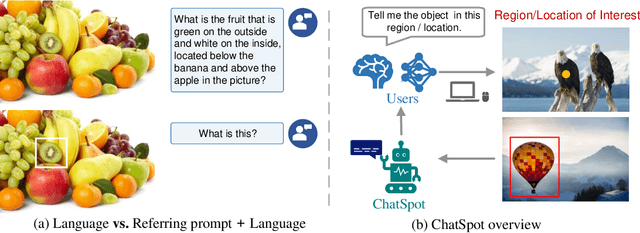

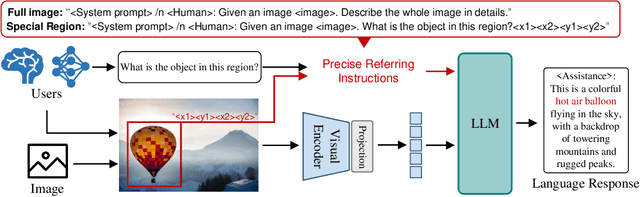

Human-AI interactivity is a critical aspect that reflects the usability of multimodal large language models (MLLMs). However, existing end-to-end MLLMs only allow users to interact with them through language instructions, leading to the limitation of the interactive accuracy and efficiency. In this study, we present precise referring instructions that utilize diverse reference representations such as points and boxes as referring prompts to refer to the special region. This enables MLLMs to focus on the region of interest and achieve finer-grained interaction. Based on precise referring instruction, we propose ChatSpot, a unified end-to-end multimodal large language model that supports diverse forms of interactivity including mouse clicks, drag-and-drop, and drawing boxes, which provides a more flexible and seamless interactive experience. We also construct a multi-grained vision-language instruction-following dataset based on existing datasets and GPT-4 generating. Furthermore, we design a series of evaluation tasks to assess the effectiveness of region recognition and interaction. Experimental results showcase ChatSpot's promising performance.
PolyLM: An Open Source Polyglot Large Language Model
Jul 12, 2023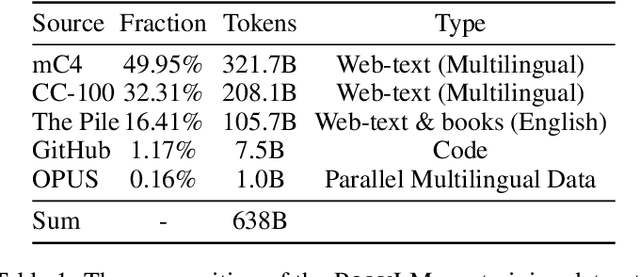

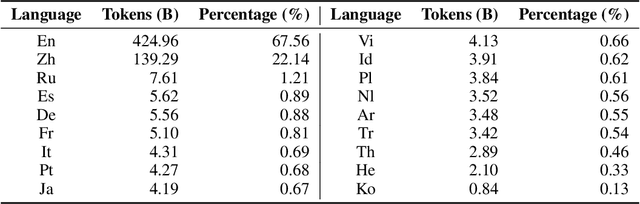
Large language models (LLMs) demonstrate remarkable ability to comprehend, reason, and generate following nature language instructions. However, the development of LLMs has been primarily focused on high-resource languages, such as English, thereby limiting their applicability and research in other languages. Consequently, we present PolyLM, a multilingual LLM trained on 640 billion (B) tokens, avaliable in two model sizes: 1.7B and 13B. To enhance its multilingual capabilities, we 1) integrate bilingual data into training data; and 2) adopt a curriculum learning strategy that increases the proportion of non-English data from 30% in the first stage to 60% in the final stage during pre-training. Further, we propose a multilingual self-instruct method which automatically generates 132.7K diverse multilingual instructions for model fine-tuning. To assess the model's performance, we collect several existing multilingual tasks, including multilingual understanding, question answering, generation, and translation. Extensive experiments show that PolyLM surpasses other open-source models such as LLaMA and BLOOM on multilingual tasks while maintaining comparable performance in English. Our models, alone with the instruction data and multilingual benchmark, are available at: \url{https://modelscope.cn/models/damo/nlp_polylm_13b_text_generation}.
Multi-pass Training and Cross-information Fusion for Low-resource End-to-end Accented Speech Recognition
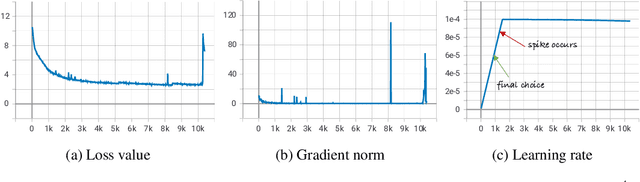
Jun 20, 2023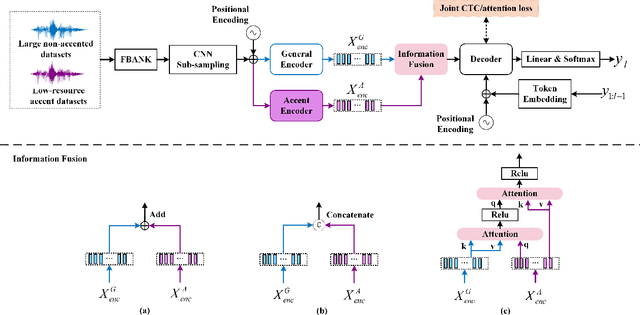
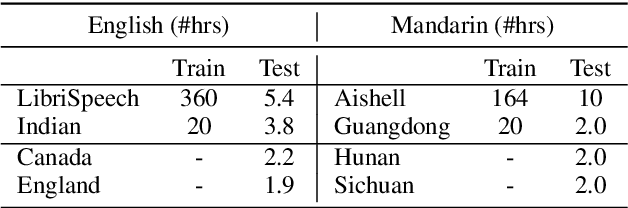

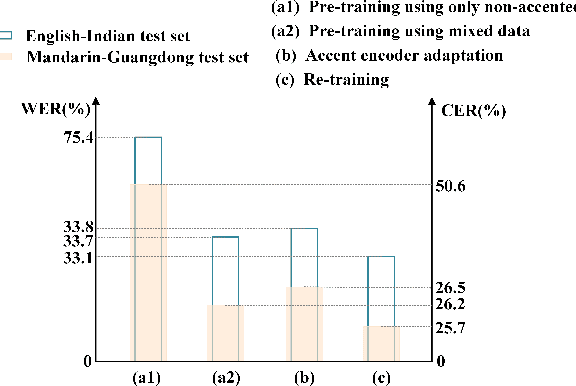
Low-resource accented speech recognition is one of the important challenges faced by current ASR technology in practical applications. In this study, we propose a Conformer-based architecture, called Aformer, to leverage both the acoustic information from large non-accented and limited accented training data. Specifically, a general encoder and an accent encoder are designed in the Aformer to extract complementary acoustic information. Moreover, we propose to train the Aformer in a multi-pass manner, and investigate three cross-information fusion methods to effectively combine the information from both general and accent encoders. All experiments are conducted on both the accented English and Mandarin ASR tasks. Results show that our proposed methods outperform the strong Conformer baseline by relative 10.2% to 24.5% word/character error rate reduction on six in-domain and out-of-domain accented test sets.