 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHaibin Lin
LLM-PQ: Serving LLM on Heterogeneous Clusters with Phase-Aware Partition and Adaptive Quantization
Mar 02, 2024
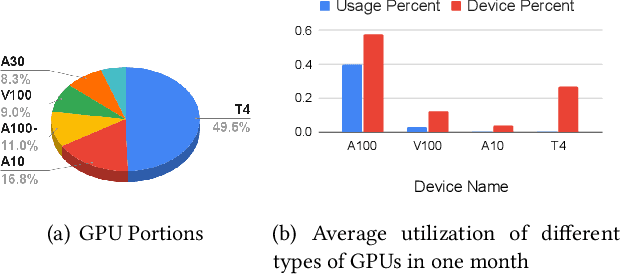

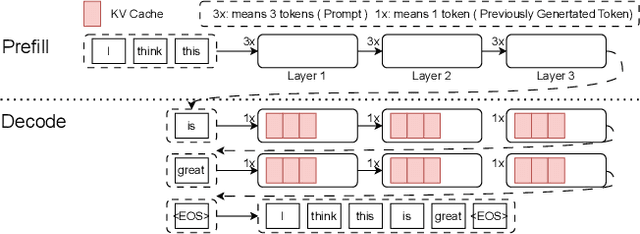

Recent breakthroughs in Large-scale language models (LLMs) have demonstrated impressive performance on various tasks. The immense sizes of LLMs have led to very high resource demand and cost for running the models. Though the models are largely served using uniform high-caliber GPUs nowadays, utilizing a heterogeneous cluster with a mix of available high- and low-capacity GPUs can potentially substantially reduce the serving cost. There is a lack of designs to support efficient LLM serving using a heterogeneous cluster, while the current solutions focus on model partition and uniform compression among homogeneous devices. This paper proposes LLM-PQ, a system that advocates adaptive model quantization and phase-aware partition to improve LLM serving efficiency on heterogeneous GPU clusters. We carefully decide on mixed-precision model quantization together with phase-aware model partition and micro-batch sizing in distributed LLM serving with an efficient algorithm, to greatly enhance inference throughput while fulfilling user-specified model quality targets. Extensive experiments on production inference workloads in 11 different clusters demonstrate that LLM-PQ achieves up to 2.88x (2.26x on average) throughput improvement in inference, showing great advantages over state-of-the-art works.
MegaScale: Scaling Large Language Model Training to More Than 10,000 GPUs
Feb 23, 2024We present the design, implementation and engineering experience in building and deploying MegaScale, a production system for training large language models (LLMs) at the scale of more than 10,000 GPUs. Training LLMs at this scale brings unprecedented challenges to training efficiency and stability. We take a full-stack approach that co-designs the algorithmic and system components across model block and optimizer design, computation and communication overlapping, operator optimization, data pipeline, and network performance tuning. Maintaining high efficiency throughout the training process (i.e., stability) is an important consideration in production given the long extent of LLM training jobs. Many hard stability issues only emerge at large scale, and in-depth observability is the key to address them. We develop a set of diagnosis tools to monitor system components and events deep in the stack, identify root causes, and derive effective techniques to achieve fault tolerance and mitigate stragglers. MegaScale achieves 55.2% Model FLOPs Utilization (MFU) when training a 175B LLM model on 12,288 GPUs, improving the MFU by 1.34x compared to Megatron-LM. We share our operational experience in identifying and fixing failures and stragglers. We hope by articulating the problems and sharing our experience from a systems perspective, this work can inspire future LLM systems research.
CDMPP: A Device-Model Agnostic Framework for Latency Prediction of Tensor Programs
Nov 17, 2023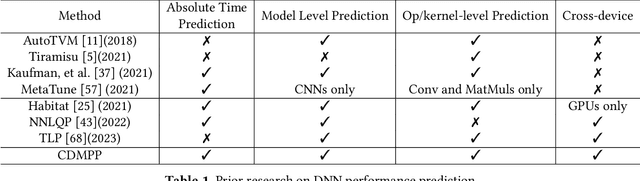
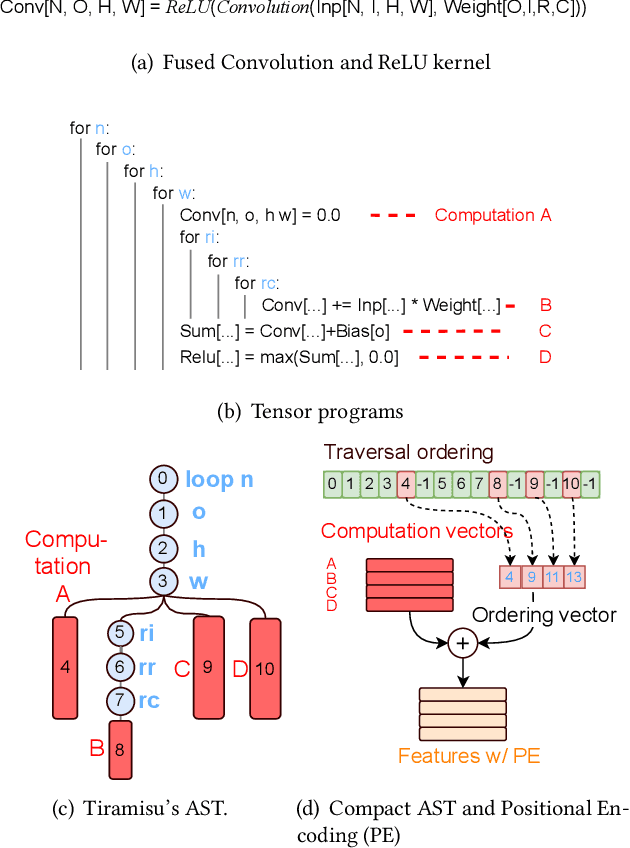
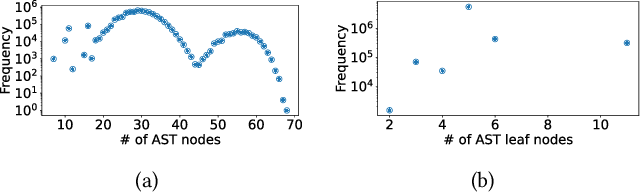

Deep Neural Networks (DNNs) have shown excellent performance in a wide range of machine learning applications. Knowing the latency of running a DNN model or tensor program on a specific device is useful in various tasks, such as DNN graph- or tensor-level optimization and device selection. Considering the large space of DNN models and devices that impede direct profiling of all combinations, recent efforts focus on building a predictor to model the performance of DNN models on different devices. However, none of the existing attempts have achieved a cost model that can accurately predict the performance of various tensor programs while supporting both training and inference accelerators. We propose CDMPP, an efficient tensor program latency prediction framework for both cross-model and cross-device prediction. We design an informative but efficient representation of tensor programs, called compact ASTs, and a pre-order-based positional encoding method, to capture the internal structure of tensor programs. We develop a domain-adaption-inspired method to learn domain-invariant representations and devise a KMeans-based sampling algorithm, for the predictor to learn from different domains (i.e., different DNN operators and devices). Our extensive experiments on a diverse range of DNN models and devices demonstrate that CDMPP significantly outperforms state-of-the-art baselines with 14.03% and 10.85% prediction error for cross-model and cross-device prediction, respectively, and one order of magnitude higher training efficiency. The implementation and the expanded dataset are available at https://github.com/joapolarbear/cdmpp.
* Accepted by EuroSys 2024
LEMON: Lossless model expansion
Oct 12, 2023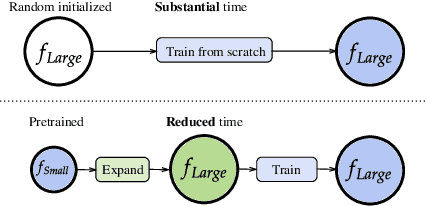


Scaling of deep neural networks, especially Transformers, is pivotal for their surging performance and has further led to the emergence of sophisticated reasoning capabilities in foundation models. Such scaling generally requires training large models from scratch with random initialization, failing to leverage the knowledge acquired by their smaller counterparts, which are already resource-intensive to obtain. To tackle this inefficiency, we present $\textbf{L}$ossl$\textbf{E}$ss $\textbf{MO}$del Expansio$\textbf{N}$ (LEMON), a recipe to initialize scaled models using the weights of their smaller but pre-trained counterparts. This is followed by model training with an optimized learning rate scheduler tailored explicitly for the scaled models, substantially reducing the training time compared to training from scratch. Notably, LEMON is versatile, ensuring compatibility with various network structures, including models like Vision Transformers and BERT. Our empirical results demonstrate that LEMON reduces computational costs by 56.7% for Vision Transformers and 33.2% for BERT when compared to training from scratch.
ByteComp: Revisiting Gradient Compression in Distributed Training
Jun 06, 2022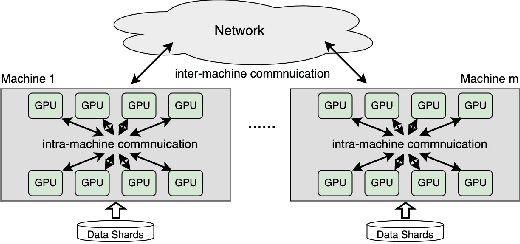



Gradient compression (GC) is a promising approach to addressing the communication bottleneck in distributed deep learning (DDL). However, it is challenging to find the optimal compression strategy for applying GC to DDL because of the intricate interactions among tensors. To fully unleash the benefits of GC, two questions must be addressed: 1) How to express all compression strategies and the corresponding interactions among tensors of any DDL training job? 2) How to quickly select a near-optimal compression strategy? In this paper, we propose ByteComp to answer these questions. It first designs a decision tree abstraction to express all the compression strategies and develops empirical models to timeline tensor computation, communication, and compression to enable ByteComp to derive the intricate interactions among tensors. It then designs a compression decision algorithm that analyzes tensor interactions to eliminate and prioritize strategies and optimally offloads compression to CPUs. Experimental evaluations show that ByteComp can improve the training throughput over the start-of-the-art compression-enabled system by up to 77% for representative DDL training jobs. Moreover, the computational time needed to select the compression strategy is measured in milliseconds, and the selected strategy is only a few percent from optimal.
dPRO: A Generic Profiling and Optimization System for Expediting Distributed DNN Training
May 18, 2022



Distributed training using multiple devices (e.g., GPUs) has been widely adopted for learning DNN models over large datasets. However, the performance of large-scale distributed training tends to be far from linear speed-up in practice. Given the complexity of distributed systems, it is challenging to identify the root cause(s) of inefficiency and exercise effective performance optimizations when unexpected low training speed occurs. To date, there exists no software tool which diagnoses performance issues and helps expedite distributed DNN training, while the training can be run using different deep learning frameworks. This paper proposes dPRO, a toolkit that includes: (1) an efficient profiler that collects runtime traces of distributed DNN training across multiple frameworks, especially fine-grained communication traces, and constructs global data flow graphs including detailed communication operations for accurate replay; (2) an optimizer that effectively identifies performance bottlenecks and explores optimization strategies (from computation, communication, and memory aspects) for training acceleration. We implement dPRO on multiple deep learning frameworks (TensorFlow, MXNet) and representative communication schemes (AllReduce and Parameter Server). Extensive experiments show that dPRO predicts the performance of distributed training in various settings with < 5% errors in most cases and finds optimization strategies with up to 3.48x speed-up over the baselines.
Compressed Communication for Distributed Training: Adaptive Methods and System
May 17, 2021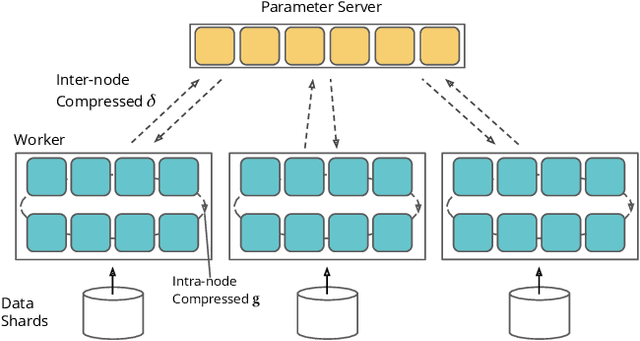

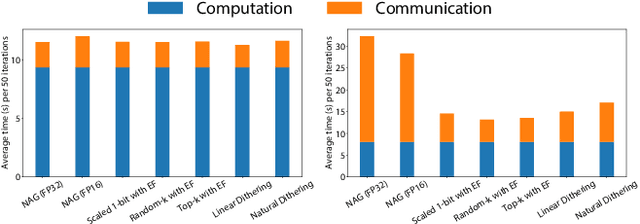
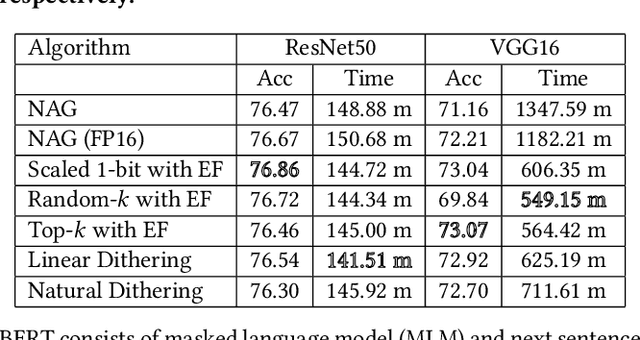
Communication overhead severely hinders the scalability of distributed machine learning systems. Recently, there has been a growing interest in using gradient compression to reduce the communication overhead of the distributed training. However, there is little understanding of applying gradient compression to adaptive gradient methods. Moreover, its performance benefits are often limited by the non-negligible compression overhead. In this paper, we first introduce a novel adaptive gradient method with gradient compression. We show that the proposed method has a convergence rate of $\mathcal{O}(1/\sqrt{T})$ for non-convex problems. In addition, we develop a scalable system called BytePS-Compress for two-way compression, where the gradients are compressed in both directions between workers and parameter servers. BytePS-Compress pipelines the compression and decompression on CPUs and achieves a high degree of parallelism. Empirical evaluations show that we improve the training time of ResNet50, VGG16, and BERT-base by 5.0%, 58.1%, 23.3%, respectively, without any accuracy loss with 25 Gb/s networking. Furthermore, for training the BERT models, we achieve a compression rate of 333x compared to the mixed-precision training.
CSER: Communication-efficient SGD with Error Reset
Jul 29, 2020
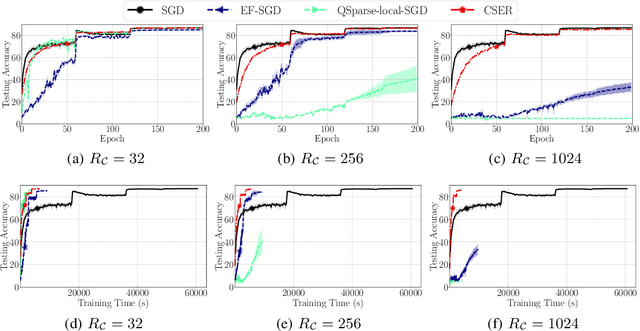

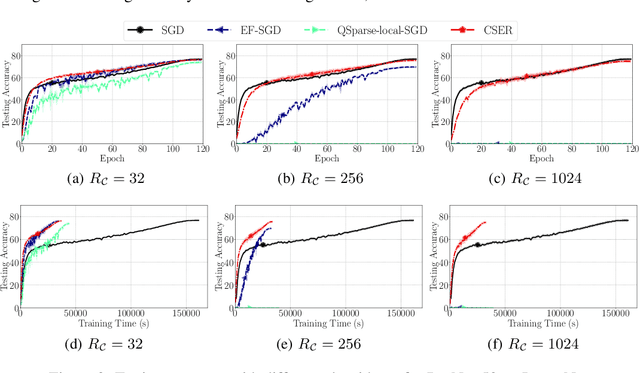
The scalability of Distributed Stochastic Gradient Descent (SGD) is today limited by communication bottlenecks. We propose a novel SGD variant: Communication-efficient SGD with Error Reset, or CSER. The key idea in CSER is first a new technique called "error reset" that adapts arbitrary compressors for SGD, producing bifurcated local models with periodic reset of resulting local residual errors. Second we introduce partial synchronization for both the gradients and the models, leveraging advantages from them. We prove the convergence of CSER for smooth non-convex problems. Empirical results show that when combined with highly aggressive compressors, the CSER algorithms: i) cause no loss of accuracy, and ii) accelerate the training by nearly $10\times$ for CIFAR-100, and by $4.5\times$ for ImageNet.
Is Network the Bottleneck of Distributed Training?
Jun 24, 2020

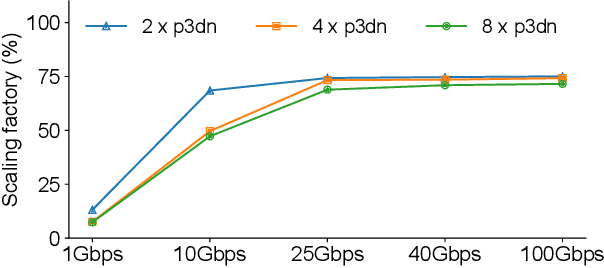
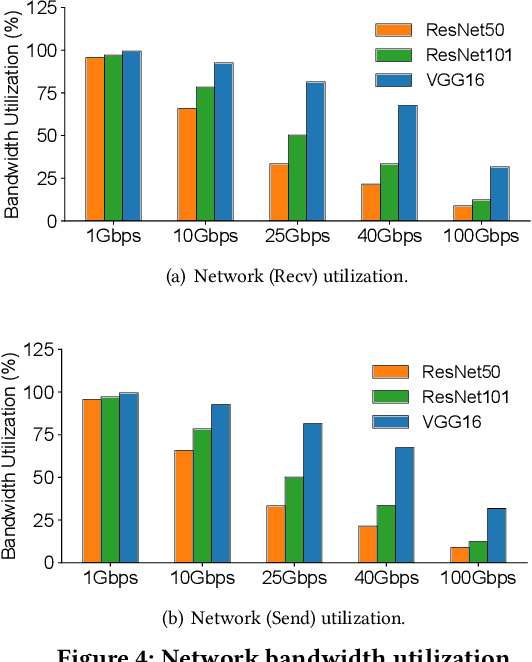
Recently there has been a surge of research on improving the communication efficiency of distributed training. However, little work has been done to systematically understand whether the network is the bottleneck and to what extent. In this paper, we take a first-principles approach to measure and analyze the network performance of distributed training. As expected, our measurement confirms that communication is the component that blocks distributed training from linear scale-out. However, contrary to the common belief, we find that the network is running at low utilization and that if the network can be fully utilized, distributed training can achieve a scaling factor of close to one. Moreover, while many recent proposals on gradient compression advocate over 100x compression ratio, we show that under full network utilization, there is no need for gradient compression in 100 Gbps network. On the other hand, a lower speed network like 10 Gbps requires only 2x--5x gradients compression ratio to achieve almost linear scale-out. Compared to application-level techniques like gradient compression, network-level optimizations do not require changes to applications and do not hurt the performance of trained models. As such, we advocate that the real challenge of distributed training is for the network community to develop high-performance network transport to fully utilize the network capacity and achieve linear scale-out.
Accelerated Large Batch Optimization of BERT Pretraining in 54 minutes
Jun 24, 2020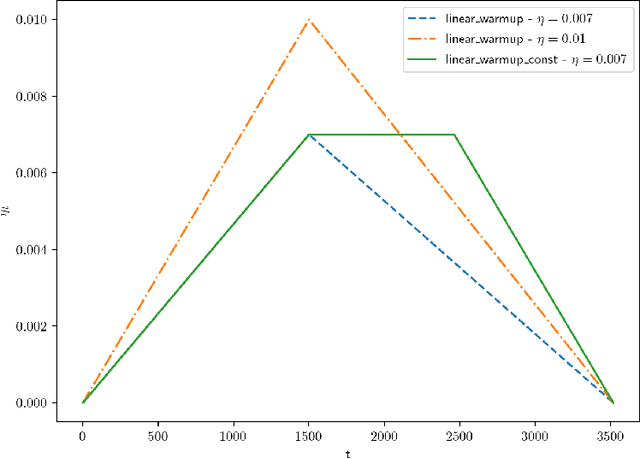


BERT has recently attracted a lot of attention in natural language understanding (NLU) and achieved state-of-the-art results in various NLU tasks. However, its success requires large deep neural networks and huge amount of data, which result in long training time and impede development progress. Using stochastic gradient methods with large mini-batch has been advocated as an efficient tool to reduce the training time. Along this line of research, LAMB is a prominent example that reduces the training time of BERT from 3 days to 76 minutes on a TPUv3 Pod. In this paper, we propose an accelerated gradient method called LANS to improve the efficiency of using large mini-batches for training. As the learning rate is theoretically upper bounded by the inverse of the Lipschitz constant of the function, one cannot always reduce the number of optimization iterations by selecting a larger learning rate. In order to use larger mini-batch size without accuracy loss, we develop a new learning rate scheduler that overcomes the difficulty of using large learning rate. Using the proposed LANS method and the learning rate scheme, we scaled up the mini-batch sizes to 96K and 33K in phases 1 and 2 of BERT pretraining, respectively. It takes 54 minutes on 192 AWS EC2 P3dn.24xlarge instances to achieve a target F1 score of 90.5 or higher on SQuAD v1.1, achieving the fastest BERT training time in the cloud.