 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHanlin Lu
LEMON: Lossless model expansion
Oct 12, 2023
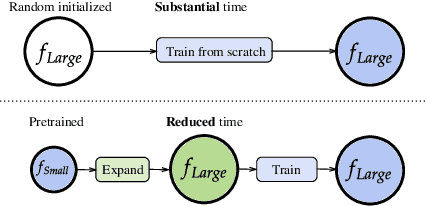

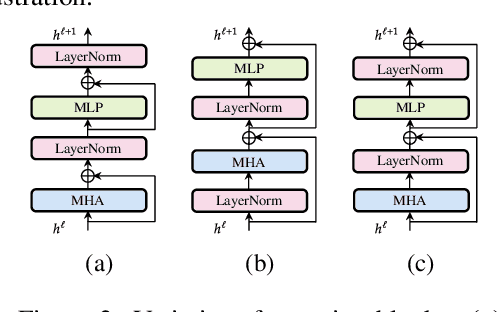

Scaling of deep neural networks, especially Transformers, is pivotal for their surging performance and has further led to the emergence of sophisticated reasoning capabilities in foundation models. Such scaling generally requires training large models from scratch with random initialization, failing to leverage the knowledge acquired by their smaller counterparts, which are already resource-intensive to obtain. To tackle this inefficiency, we present $\textbf{L}$ossl$\textbf{E}$ss $\textbf{MO}$del Expansio$\textbf{N}$ (LEMON), a recipe to initialize scaled models using the weights of their smaller but pre-trained counterparts. This is followed by model training with an optimized learning rate scheduler tailored explicitly for the scaled models, substantially reducing the training time compared to training from scratch. Notably, LEMON is versatile, ensuring compatibility with various network structures, including models like Vision Transformers and BERT. Our empirical results demonstrate that LEMON reduces computational costs by 56.7% for Vision Transformers and 33.2% for BERT when compared to training from scratch.
CAT: Causal Audio Transformer for Audio Classification
Mar 14, 2023


The attention-based Transformers have been increasingly applied to audio classification because of their global receptive field and ability to handle long-term dependency. However, the existing frameworks which are mainly extended from the Vision Transformers are not perfectly compatible with audio signals. In this paper, we introduce a Causal Audio Transformer (CAT) consisting of a Multi-Resolution Multi-Feature (MRMF) feature extraction with an acoustic attention block for more optimized audio modeling. In addition, we propose a causal module that alleviates over-fitting, helps with knowledge transfer, and improves interpretability. CAT obtains higher or comparable state-of-the-art classification performance on ESC50, AudioSet and UrbanSound8K datasets, and can be easily generalized to other Transformer-based models.
Joint Coreset Construction and Quantization for Distributed Machine Learning
Apr 13, 2022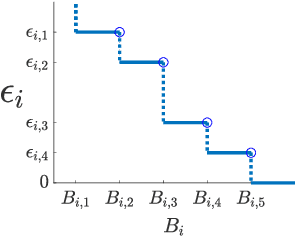
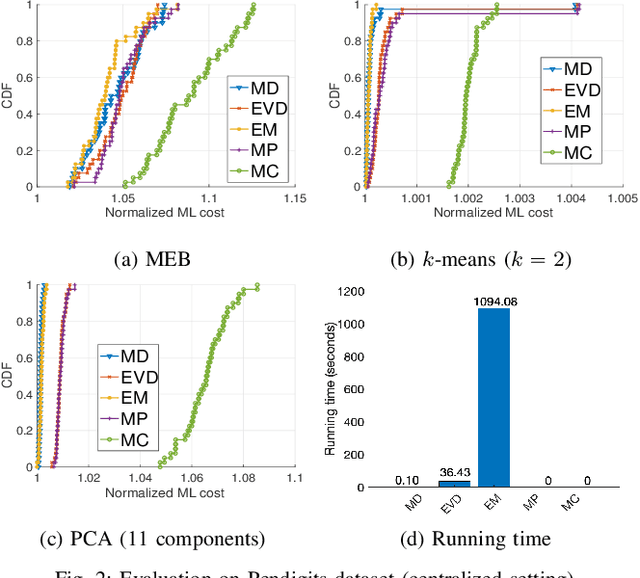
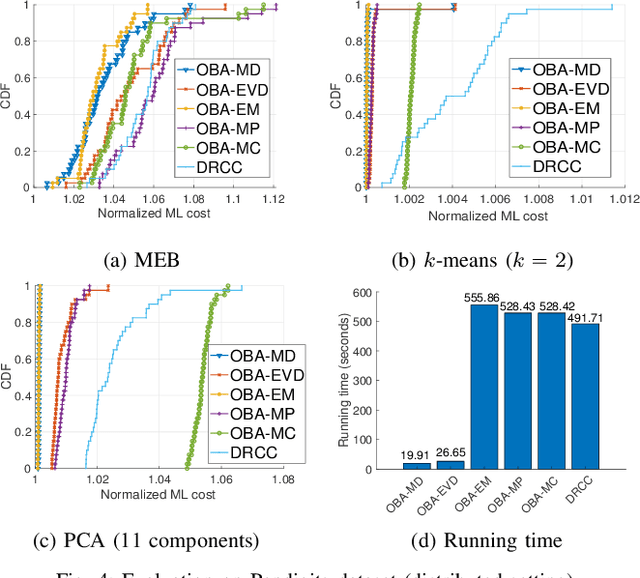
Coresets are small, weighted summaries of larger datasets, aiming at providing provable error bounds for machine learning (ML) tasks while significantly reducing the communication and computation costs. To achieve a better trade-off between ML error bounds and costs, we propose the first framework to incorporate quantization techniques into the process of coreset construction. Specifically, we theoretically analyze the ML error bounds caused by a combination of coreset construction and quantization. Based on that, we formulate an optimization problem to minimize the ML error under a fixed budget of communication cost. To improve the scalability for large datasets, we identify two proxies of the original objective function, for which efficient algorithms are developed. For the case of data on multiple nodes, we further design a novel algorithm to allocate the communication budget to the nodes while minimizing the overall ML error. Through extensive experiments on multiple real-world datasets, we demonstrate the effectiveness and efficiency of our proposed algorithms for a variety of ML tasks. In particular, our algorithms have achieved more than 90% data reduction with less than 10% degradation in ML performance in most cases.
Communication-efficient k-Means for Edge-based Machine Learning
Feb 08, 2021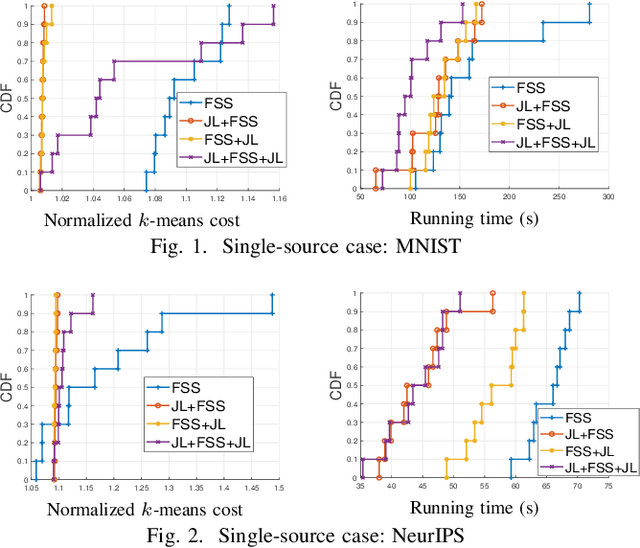
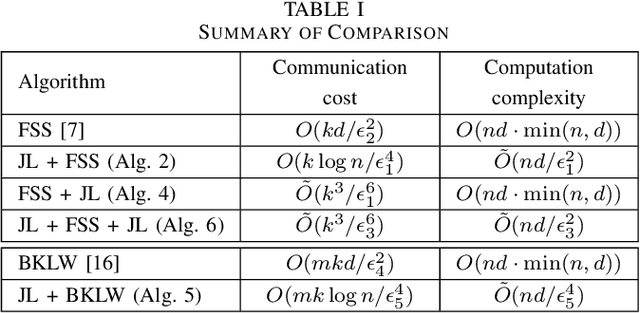
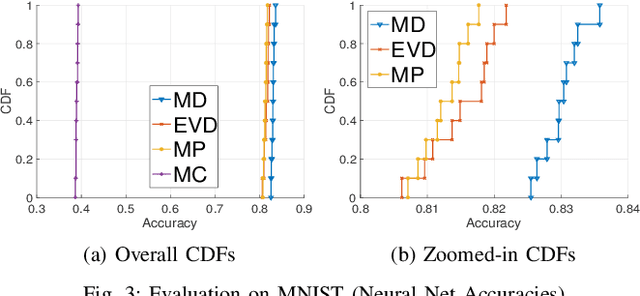
We consider the problem of computing the k-means centers for a large high-dimensional dataset in the context of edge-based machine learning, where data sources offload machine learning computation to nearby edge servers. k-Means computation is fundamental to many data analytics, and the capability of computing provably accurate k-means centers by leveraging the computation power of the edge servers, at a low communication and computation cost to the data sources, will greatly improve the performance of these analytics. We propose to let the data sources send small summaries, generated by joint dimensionality reduction (DR) and cardinality reduction (CR), to support approximate k-means computation at reduced complexity and communication cost. By analyzing the complexity, the communication cost, and the approximation error of k-means algorithms based on state-of-the-art DR/CR methods, we show that: (i) it is possible to achieve a near-optimal approximation at a near-linear complexity and a constant or logarithmic communication cost, (ii) the order of applying DR and CR significantly affects the complexity and the communication cost, and (iii) combining DR/CR methods with a properly configured quantizer can further reduce the communication cost without compromising the other performance metrics. Our findings are validated through experiments based on real datasets.
Sharing Models or Coresets: A Study based on Membership Inference Attack
Jul 06, 2020



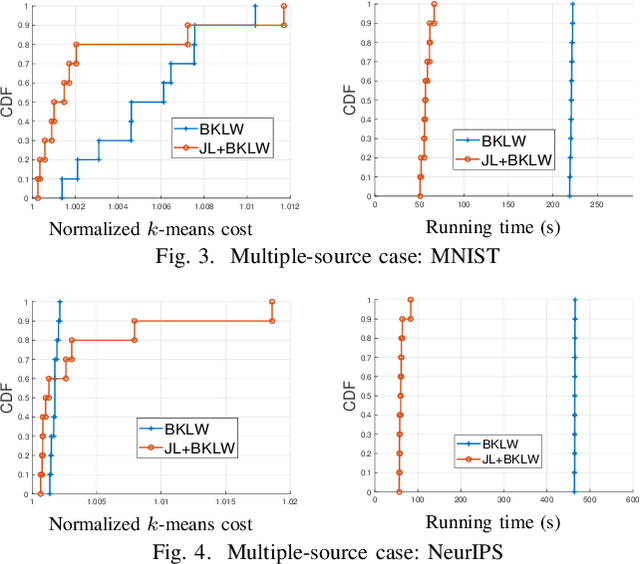
Distributed machine learning generally aims at training a global model based on distributed data without collecting all the data to a centralized location, where two different approaches have been proposed: collecting and aggregating local models (federated learning) and collecting and training over representative data summaries (coreset). While each approach preserves data privacy to some extent thanks to not sharing the raw data, the exact extent of protection is unclear under sophisticated attacks that try to infer the raw data from the shared information. We present the first comparison between the two approaches in terms of target model accuracy, communication cost, and data privacy, where the last is measured by the accuracy of a state-of-the-art attack strategy called the membership inference attack. Our experiments quantify the accuracy-privacy-cost tradeoff of each approach, and reveal a nontrivial comparison that can be used to guide the design of model training processes.
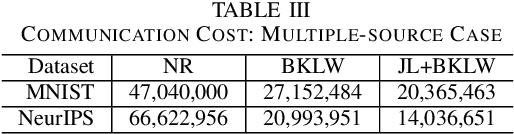
Robust Coreset Construction for Distributed Machine Learning
Apr 11, 2019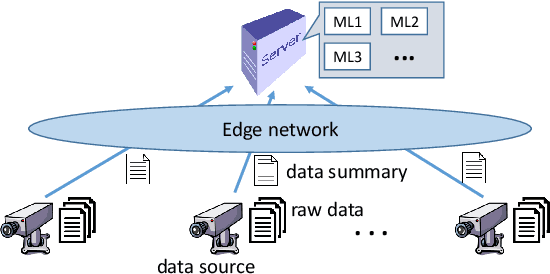
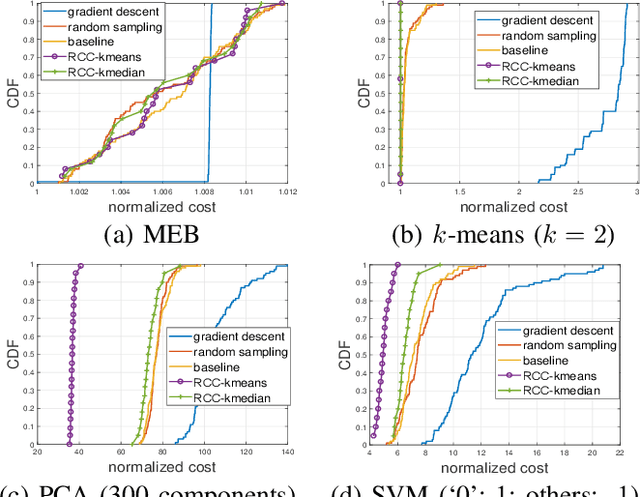
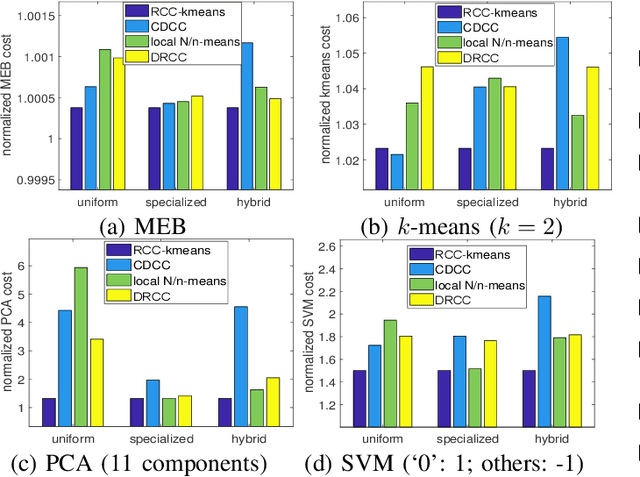
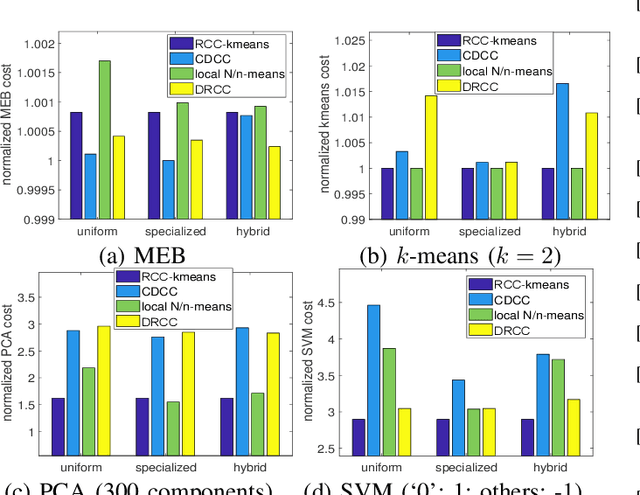
Motivated by the need of solving machine learning problems over distributed datasets, we explore the use of coreset to reduce the communication overhead. Coreset is a summary of the original dataset in the form of a small weighted set in the same sample space. Compared to other data summaries, coreset has the advantage that it can be used as a proxy of the original dataset, potentially for different applications. However, existing coreset construction algorithms are each tailor-made for a specific machine learning problem. Thus, to solve different machine learning problems, one has to collect coresets of different types, defeating the purpose of saving communication overhead. We resolve this dilemma by developing coreset construction algorithms based on k-means/median clustering, that give a provably good approximation for a broad range of machine learning problems with sufficiently continuous cost functions. Through evaluations on diverse datasets and machine learning problems, we verify the robust performance of the proposed algorithms.