 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShiqiang Wang
Adaptive Heterogeneous Client Sampling for Federated Learning over Wireless Networks
Apr 22, 2024
Federated learning (FL) algorithms usually sample a fraction of clients in each round (partial participation) when the number of participants is large and the server's communication bandwidth is limited. Recent works on the convergence analysis of FL have focused on unbiased client sampling, e.g., sampling uniformly at random, which suffers from slow wall-clock time for convergence due to high degrees of system heterogeneity and statistical heterogeneity. This paper aims to design an adaptive client sampling algorithm for FL over wireless networks that tackles both system and statistical heterogeneity to minimize the wall-clock convergence time. We obtain a new tractable convergence bound for FL algorithms with arbitrary client sampling probability. Based on the bound, we analytically establish the relationship between the total learning time and sampling probability with an adaptive bandwidth allocation scheme, which results in a non-convex optimization problem. We design an efficient algorithm for learning the unknown parameters in the convergence bound and develop a low-complexity algorithm to approximately solve the non-convex problem. Our solution reveals the impact of system and statistical heterogeneity parameters on the optimal client sampling design. Moreover, our solution shows that as the number of sampled clients increases, the total convergence time first decreases and then increases because a larger sampling number reduces the number of rounds for convergence but results in a longer expected time per-round due to limited wireless bandwidth. Experimental results from both hardware prototype and simulation demonstrate that our proposed sampling scheme significantly reduces the convergence time compared to several baseline sampling schemes.
Communication-Efficient Hybrid Federated Learning for E-health with Horizontal and Vertical Data Partitioning
Apr 15, 2024E-health allows smart devices and medical institutions to collaboratively collect patients' data, which is trained by Artificial Intelligence (AI) technologies to help doctors make diagnosis. By allowing multiple devices to train models collaboratively, federated learning is a promising solution to address the communication and privacy issues in e-health. However, applying federated learning in e-health faces many challenges. First, medical data is both horizontally and vertically partitioned. Since single Horizontal Federated Learning (HFL) or Vertical Federated Learning (VFL) techniques cannot deal with both types of data partitioning, directly applying them may consume excessive communication cost due to transmitting a part of raw data when requiring high modeling accuracy. Second, a naive combination of HFL and VFL has limitations including low training efficiency, unsound convergence analysis, and lack of parameter tuning strategies. In this paper, we provide a thorough study on an effective integration of HFL and VFL, to achieve communication efficiency and overcome the above limitations when data is both horizontally and vertically partitioned. Specifically, we propose a hybrid federated learning framework with one intermediate result exchange and two aggregation phases. Based on this framework, we develop a Hybrid Stochastic Gradient Descent (HSGD) algorithm to train models. Then, we theoretically analyze the convergence upper bound of the proposed algorithm. Using the convergence results, we design adaptive strategies to adjust the training parameters and shrink the size of transmitted data. Experimental results validate that the proposed HSGD algorithm can achieve the desired accuracy while reducing communication cost, and they also verify the effectiveness of the adaptive strategies.
FedFisher: Leveraging Fisher Information for One-Shot Federated Learning
Mar 19, 2024



Standard federated learning (FL) algorithms typically require multiple rounds of communication between the server and the clients, which has several drawbacks, including requiring constant network connectivity, repeated investment of computational resources, and susceptibility to privacy attacks. One-Shot FL is a new paradigm that aims to address this challenge by enabling the server to train a global model in a single round of communication. In this work, we present FedFisher, a novel algorithm for one-shot FL that makes use of Fisher information matrices computed on local client models, motivated by a Bayesian perspective of FL. First, we theoretically analyze FedFisher for two-layer over-parameterized ReLU neural networks and show that the error of our one-shot FedFisher global model becomes vanishingly small as the width of the neural networks and amount of local training at clients increases. Next, we propose practical variants of FedFisher using the diagonal Fisher and K-FAC approximation for the full Fisher and highlight their communication and compute efficiency for FL. Finally, we conduct extensive experiments on various datasets, which show that these variants of FedFisher consistently improve over competing baselines.
Federated Learning Priorities Under the European Union Artificial Intelligence Act
Feb 05, 2024The age of AI regulation is upon us, with the European Union Artificial Intelligence Act (AI Act) leading the way. Our key inquiry is how this will affect Federated Learning (FL), whose starting point of prioritizing data privacy while performing ML fundamentally differs from that of centralized learning. We believe the AI Act and future regulations could be the missing catalyst that pushes FL toward mainstream adoption. However, this can only occur if the FL community reprioritizes its research focus. In our position paper, we perform a first-of-its-kind interdisciplinary analysis (legal and ML) of the impact the AI Act may have on FL and make a series of observations supporting our primary position through quantitative and qualitative analysis. We explore data governance issues and the concern for privacy. We establish new challenges regarding performance and energy efficiency within lifecycle monitoring. Taken together, our analysis suggests there is a sizable opportunity for FL to become a crucial component of AI Act-compliant ML systems and for the new regulation to drive the adoption of FL techniques in general. Most noteworthy are the opportunities to defend against data bias and enhance private and secure computation
A Survey on Efficient Federated Learning Methods for Foundation Model Training
Jan 09, 2024Federated Learning (FL) has become an established technique to facilitate privacy-preserving collaborative training. However, new approaches to FL often discuss their contributions involving small deep-learning models only. With the tremendous success of transformer models, the following question arises: What is necessary to operationalize foundation models in an FL application? Knowing that computation and communication often take up similar amounts of time in FL, we introduce a novel taxonomy focused on computational and communication efficiency methods in FL applications. This said, these methods aim to optimize the training time and reduce communication between clients and the server. We also look at the current state of widely used FL frameworks and discuss future research potentials based on existing approaches in FL research and beyond.
Federated Learning While Providing Model as a Service: Joint Training and Inference Optimization
Dec 21, 2023While providing machine learning model as a service to process users' inference requests, online applications can periodically upgrade the model utilizing newly collected data. Federated learning (FL) is beneficial for enabling the training of models across distributed clients while keeping the data locally. However, existing work has overlooked the coexistence of model training and inference under clients' limited resources. This paper focuses on the joint optimization of model training and inference to maximize inference performance at clients. Such an optimization faces several challenges. The first challenge is to characterize the clients' inference performance when clients may partially participate in FL. To resolve this challenge, we introduce a new notion of age of model (AoM) to quantify client-side model freshness, based on which we use FL's global model convergence error as an approximate measure of inference performance. The second challenge is the tight coupling among clients' decisions, including participation probability in FL, model download probability, and service rates. Toward the challenges, we propose an online problem approximation to reduce the problem complexity and optimize the resources to balance the needs of model training and inference. Experimental results demonstrate that the proposed algorithm improves the average inference accuracy by up to 12%.
DePRL: Achieving Linear Convergence Speedup in Personalized Decentralized Learning with Shared Representations
Dec 17, 2023Decentralized learning has emerged as an alternative method to the popular parameter-server framework which suffers from high communication burden, single-point failure and scalability issues due to the need of a central server. However, most existing works focus on a single shared model for all workers regardless of the data heterogeneity problem, rendering the resulting model performing poorly on individual workers. In this work, we propose a novel personalized decentralized learning algorithm named DePRL via shared representations. Our algorithm relies on ideas from representation learning theory to learn a low-dimensional global representation collaboratively among all workers in a fully decentralized manner, and a user-specific low-dimensional local head leading to a personalized solution for each worker. We show that DePRL achieves, for the first time, a provable linear speedup for convergence with general non-linear representations (i.e., the convergence rate is improved linearly with respect to the number of workers). Experimental results support our theoretical findings showing the superiority of our method in data heterogeneous environments.
StableFDG: Style and Attention Based Learning for Federated Domain Generalization
Nov 01, 2023Traditional federated learning (FL) algorithms operate under the assumption that the data distributions at training (source domains) and testing (target domain) are the same. The fact that domain shifts often occur in practice necessitates equipping FL methods with a domain generalization (DG) capability. However, existing DG algorithms face fundamental challenges in FL setups due to the lack of samples/domains in each client's local dataset. In this paper, we propose StableFDG, a style and attention based learning strategy for accomplishing federated domain generalization, introducing two key contributions. The first is style-based learning, which enables each client to explore novel styles beyond the original source domains in its local dataset, improving domain diversity based on the proposed style sharing, shifting, and exploration strategies. Our second contribution is an attention-based feature highlighter, which captures the similarities between the features of data samples in the same class, and emphasizes the important/common characteristics to better learn the domain-invariant characteristics of each class in data-poor FL scenarios. Experimental results show that StableFDG outperforms existing baselines on various DG benchmark datasets, demonstrating its efficacy.
Federated Fine-Tuning of LLMs on the Very Edge: The Good, the Bad, the Ugly
Oct 04, 2023Large Language Models (LLM) and foundation models are popular as they offer new opportunities for individuals and businesses to improve natural language processing, interact with data, and retrieve information faster. However, training or fine-tuning LLMs requires a vast amount of data, which can be challenging to access due to legal or technical restrictions and may require private computing resources. Federated Learning (FL) is a solution designed to overcome these challenges and expand data access for deep learning applications. This paper takes a hardware-centric approach to explore how LLMs can be brought to modern edge computing systems. Our study fine-tunes the FLAN-T5 model family, ranging from 80M to 3B parameters, using FL for a text summarization task. We provide a micro-level hardware benchmark, compare the model FLOP utilization to a state-of-the-art data center GPU, and study the network utilization in realistic conditions. Our contribution is twofold: First, we evaluate the current capabilities of edge computing systems and their potential for LLM FL workloads. Second, by comparing these systems with a data-center GPU, we demonstrate the potential for improvement and the next steps toward achieving greater computational efficiency at the edge.
Straggler-Resilient Decentralized Learning via Adaptive Asynchronous Updates
Jun 11, 2023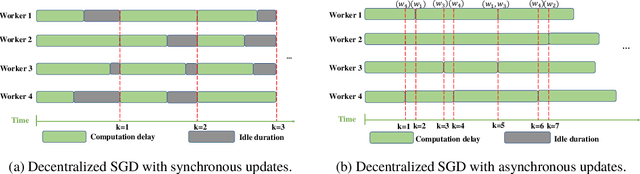
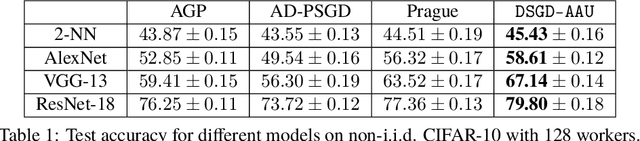
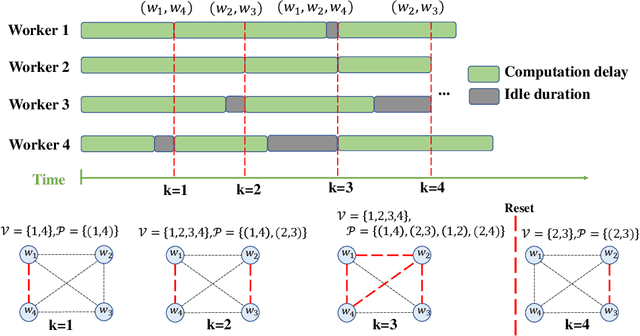

With the increasing demand for large-scale training of machine learning models, fully decentralized optimization methods have recently been advocated as alternatives to the popular parameter server framework. In this paradigm, each worker maintains a local estimate of the optimal parameter vector, and iteratively updates it by waiting and averaging all estimates obtained from its neighbors, and then corrects it on the basis of its local dataset. However, the synchronization phase is sensitive to stragglers. An efficient way to mitigate this effect is to consider asynchronous updates, where each worker computes stochastic gradients and communicates with other workers at its own pace. Unfortunately, fully asynchronous updates suffer from staleness of the stragglers' parameters. To address these limitations, we propose a fully decentralized algorithm DSGD-AAU with adaptive asynchronous updates via adaptively determining the number of neighbor workers for each worker to communicate with. We show that DSGD-AAU achieves a linear speedup for convergence (i.e., convergence performance increases linearly with respect to the number of workers). Experimental results on a suite of datasets and deep neural network models are provided to verify our theoretical results.