 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeandros Tassiulas
Adaptive Heterogeneous Client Sampling for Federated Learning over Wireless Networks
Apr 22, 2024
Federated learning (FL) algorithms usually sample a fraction of clients in each round (partial participation) when the number of participants is large and the server's communication bandwidth is limited. Recent works on the convergence analysis of FL have focused on unbiased client sampling, e.g., sampling uniformly at random, which suffers from slow wall-clock time for convergence due to high degrees of system heterogeneity and statistical heterogeneity. This paper aims to design an adaptive client sampling algorithm for FL over wireless networks that tackles both system and statistical heterogeneity to minimize the wall-clock convergence time. We obtain a new tractable convergence bound for FL algorithms with arbitrary client sampling probability. Based on the bound, we analytically establish the relationship between the total learning time and sampling probability with an adaptive bandwidth allocation scheme, which results in a non-convex optimization problem. We design an efficient algorithm for learning the unknown parameters in the convergence bound and develop a low-complexity algorithm to approximately solve the non-convex problem. Our solution reveals the impact of system and statistical heterogeneity parameters on the optimal client sampling design. Moreover, our solution shows that as the number of sampled clients increases, the total convergence time first decreases and then increases because a larger sampling number reduces the number of rounds for convergence but results in a longer expected time per-round due to limited wireless bandwidth. Experimental results from both hardware prototype and simulation demonstrate that our proposed sampling scheme significantly reduces the convergence time compared to several baseline sampling schemes.
Predictive Handover Strategy in 6G and Beyond: A Deep and Transfer Learning Approach
Apr 11, 2024Next-generation cellular networks will evolve into more complex and virtualized systems, employing machine learning for enhanced optimization and leveraging higher frequency bands and denser deployments to meet varied service demands. This evolution, while bringing numerous advantages, will also pose challenges, especially in mobility management, as it will increase the overall number of handovers due to smaller coverage areas and the higher signal attenuation. To address these challenges, we propose a deep learning based algorithm for predicting the future serving cell utilizing sequential user equipment measurements to minimize the handover failures and interruption time. Our algorithm enables network operators to dynamically adjust handover triggering events or incorporate UAV base stations for enhanced coverage and capacity, optimizing network objectives like load balancing and energy efficiency through transfer learning techniques. Our framework complies with the O-RAN specifications and can be deployed in a Near-Real-Time RAN Intelligent Controller as an xApp leveraging the E2SM-KPM service model. The evaluation results demonstrate that our algorithm achieves a 92% accuracy in predicting future serving cells with high probability. Finally, by utilizing transfer learning, our algorithm significantly reduces the retraining time by 91% and 77% when new handover trigger decisions or UAV base stations are introduced to the network dynamically.
From Similarity to Superiority: Channel Clustering for Time Series Forecasting
Mar 31, 2024Time series forecasting has attracted significant attention in recent decades. Previous studies have demonstrated that the Channel-Independent (CI) strategy improves forecasting performance by treating different channels individually, while it leads to poor generalization on unseen instances and ignores potentially necessary interactions between channels. Conversely, the Channel-Dependent (CD) strategy mixes all channels with even irrelevant and indiscriminate information, which, however, results in oversmoothing issues and limits forecasting accuracy. There is a lack of channel strategy that effectively balances individual channel treatment for improved forecasting performance without overlooking essential interactions between channels. Motivated by our observation of a correlation between the time series model's performance boost against channel mixing and the intrinsic similarity on a pair of channels, we developed a novel and adaptable Channel Clustering Module (CCM). CCM dynamically groups channels characterized by intrinsic similarities and leverages cluster identity instead of channel identity, combining the best of CD and CI worlds. Extensive experiments on real-world datasets demonstrate that CCM can (1) boost the performance of CI and CD models by an average margin of 2.4% and 7.2% on long-term and short-term forecasting, respectively; (2) enable zero-shot forecasting with mainstream time series forecasting models; (3) uncover intrinsic time series patterns among channels and improve interpretability of complex time series models.
Machine Learning on Blockchain Data: A Systematic Mapping Study
Mar 25, 2024Context: Blockchain technology has drawn growing attention in the literature and in practice. Blockchain technology generates considerable amounts of data and has thus been a topic of interest for Machine Learning (ML). Objective: The objective of this paper is to provide a comprehensive review of the state of the art on machine learning applied to blockchain data. This work aims to systematically identify, analyze, and classify the literature on ML applied to blockchain data. This will allow us to discover the fields where more effort should be placed in future research. Method: A systematic mapping study has been conducted to identify the relevant literature. Ultimately, 159 articles were selected and classified according to various dimensions, specifically, the domain use case, the blockchain, the data, and the machine learning models. Results: The majority of the papers (49.7%) fall within the Anomaly use case. Bitcoin (47.2%) was the blockchain that drew the most attention. A dataset consisting of more than 1.000.000 data points was used by 31.4% of the papers. And Classification (46.5%) was the ML task most applied to blockchain data. Conclusion: The results confirm that ML applied to blockchain data is a relevant and a growing topic of interest both in the literature and in practice. Nevertheless, some open challenges and gaps remain, which can lead to future research directions. Specifically, we identify novel machine learning algorithms, the lack of a standardization framework, blockchain scalability issues and cross-chain interactions as areas worth exploring in the future.
Efficient High-Resolution Time Series Classification via Attention Kronecker Decomposition
Mar 07, 2024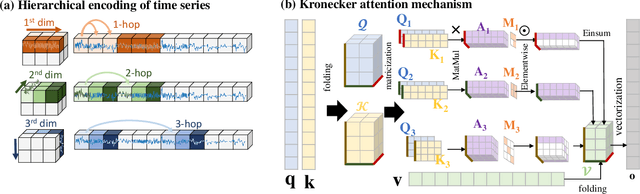
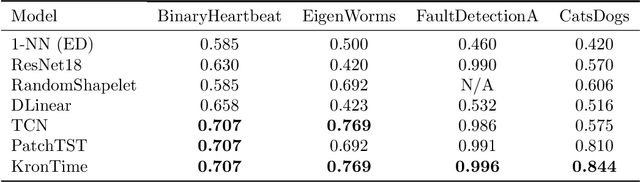
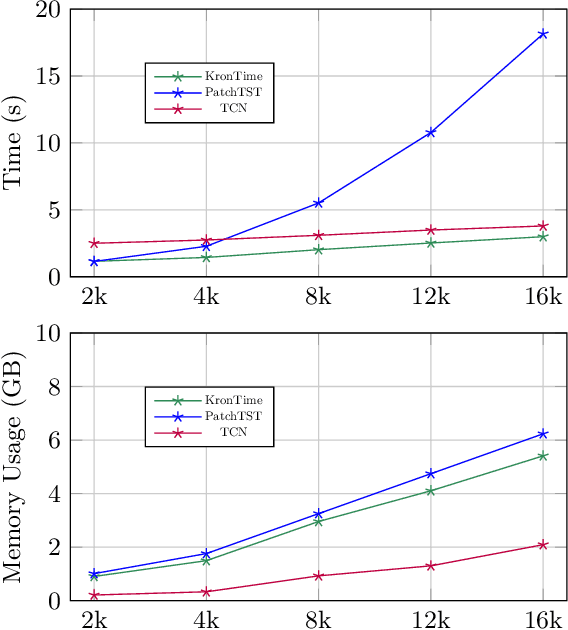
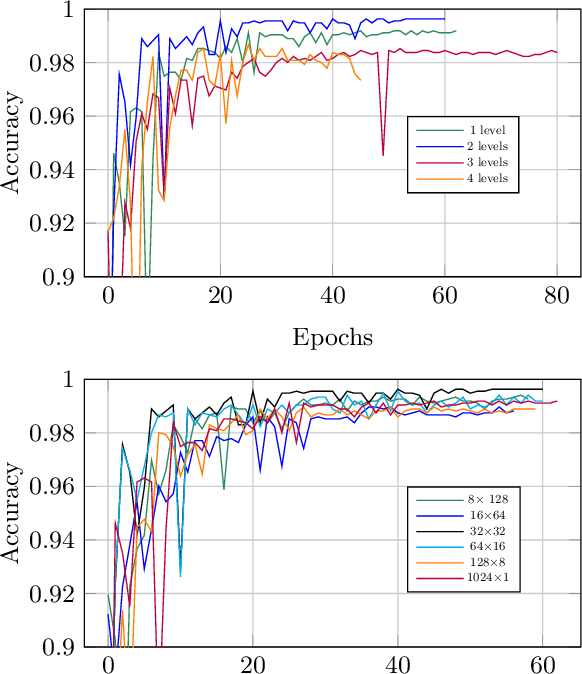
The high-resolution time series classification problem is essential due to the increasing availability of detailed temporal data in various domains. To tackle this challenge effectively, it is imperative that the state-of-the-art attention model is scalable to accommodate the growing sequence lengths typically encountered in high-resolution time series data, while also demonstrating robustness in handling the inherent noise prevalent in such datasets. To address this, we propose to hierarchically encode the long time series into multiple levels based on the interaction ranges. By capturing relationships at different levels, we can build more robust, expressive, and efficient models that are capable of capturing both short-term fluctuations and long-term trends in the data. We then propose a new time series transformer backbone (KronTime) by introducing Kronecker-decomposed attention to process such multi-level time series, which sequentially calculates attention from the lower level to the upper level. Experiments on four long time series datasets demonstrate superior classification results with improved efficiency compared to baseline methods.
An Item is Worth a Prompt: Versatile Image Editing with Disentangled Control
Mar 07, 2024Building on the success of text-to-image diffusion models (DPMs), image editing is an important application to enable human interaction with AI-generated content. Among various editing methods, editing within the prompt space gains more attention due to its capacity and simplicity of controlling semantics. However, since diffusion models are commonly pretrained on descriptive text captions, direct editing of words in text prompts usually leads to completely different generated images, violating the requirements for image editing. On the other hand, existing editing methods usually consider introducing spatial masks to preserve the identity of unedited regions, which are usually ignored by DPMs and therefore lead to inharmonic editing results. Targeting these two challenges, in this work, we propose to disentangle the comprehensive image-prompt interaction into several item-prompt interactions, with each item linked to a special learned prompt. The resulting framework, named D-Edit, is based on pretrained diffusion models with cross-attention layers disentangled and adopts a two-step optimization to build item-prompt associations. Versatile image editing can then be applied to specific items by manipulating the corresponding prompts. We demonstrate state-of-the-art results in four types of editing operations including image-based, text-based, mask-based editing, and item removal, covering most types of editing applications, all within a single unified framework. Notably, D-Edit is the first framework that can (1) achieve item editing through mask editing and (2) combine image and text-based editing. We demonstrate the quality and versatility of the editing results for a diverse collection of images through both qualitative and quantitative evaluations.
Deep Learning Architecture for Network-Efficiency at the Edge
Nov 09, 2023The growing number of AI-driven applications in the mobile devices has led to solutions that integrate deep learning models with the available edge-cloud resources; due to multiple benefits such as reduction in on-device energy consumption, improved latency, improved network usage, and certain privacy improvements, split learning, where deep learning models are split away from the mobile device and computed in a distributed manner, has become an extensively explored topic. Combined with compression-aware methods where learning adapts to compression of communicated data, the benefits of this approach have further improved and could serve as an alternative to established approaches like federated learning methods. In this work, we develop an adaptive compression-aware split learning method ('deprune') to improve and train deep learning models so that they are much more network-efficient (use less network resources and are faster), which would make them ideal to deploy in weaker devices with the help of edge-cloud resources. This method is also extended ('prune') to very quickly train deep learning models, through a transfer learning approach, that trades off little accuracy for much more network-efficient inference abilities. We show that the 'deprune' method can reduce network usage by 4x when compared with a split-learning approach (that does not use our method) without loss of accuracy, while also improving accuracy over compression-aware split-learning by 4 percent. Lastly, we show that the 'prune' method can reduce the training time for certain models by up to 6x without affecting the accuracy when compared against a compression-aware split-learning approach.
Age Optimum Sampling in Non-Stationary Environment
Oct 31, 2023In this work, we consider a status update system with a sensor and a receiver. The status update information is sampled by the sensor and then forwarded to the receiver through a channel with non-stationary delay distribution. The data freshness at the receiver is quantified by the Age-of-Information (AoI). The goal is to design an online sampling strategy that can minimize the average AoI when the non-stationary delay distribution is unknown. Assuming that channel delay distribution may change over time, to minimize the average AoI, we propose a joint stochastic approximation and non-parametric change point detection algorithm that can: (1) learn the optimum update threshold when the delay distribution remains static; (2) detect the change in transmission delay distribution quickly and then restart the learning process. Simulation results show that the proposed algorithm can quickly detect the delay changes, and the average AoI obtained by the proposed policy converges to the minimum AoI.
Incentive Mechanism Design for Unbiased Federated Learning with Randomized Client Participation
Apr 17, 2023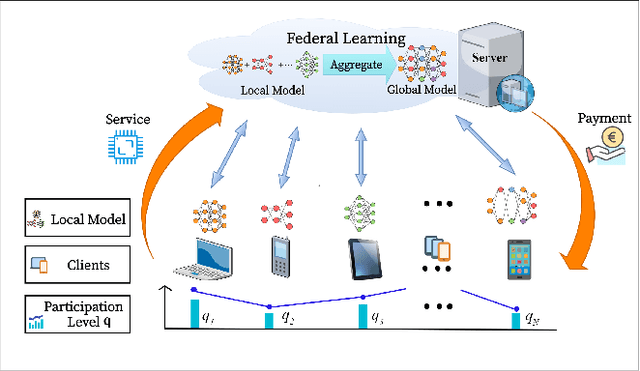
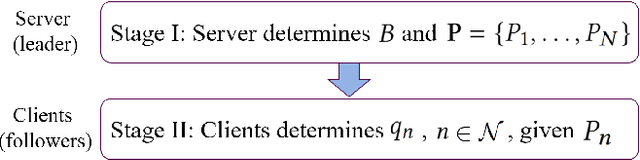

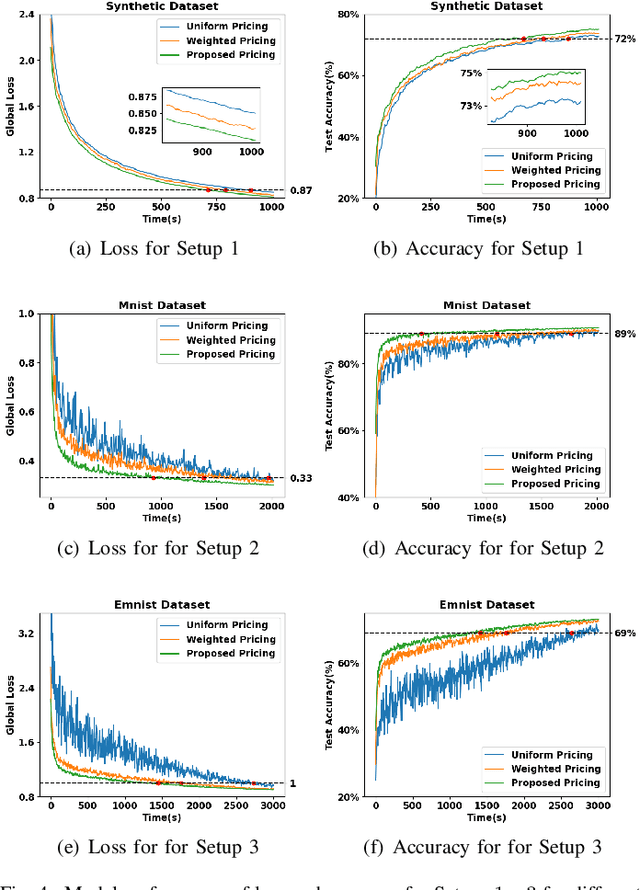
Incentive mechanism is crucial for federated learning (FL) when rational clients do not have the same interests in the global model as the server. However, due to system heterogeneity and limited budget, it is generally impractical for the server to incentivize all clients to participate in all training rounds (known as full participation). The existing FL incentive mechanisms are typically designed by stimulating a fixed subset of clients based on their data quantity or system resources. Hence, FL is performed only using this subset of clients throughout the entire training process, leading to a biased model because of data heterogeneity. This paper proposes a game theoretic incentive mechanism for FL with randomized client participation, where the server adopts a customized pricing strategy that motivates different clients to join with different participation levels (probabilities) for obtaining an unbiased and high performance model. Each client responds to the server's monetary incentive by choosing its best participation level, to maximize its profit based on not only the incurred local cost but also its intrinsic value for the global model. To effectively evaluate clients' contribution to the model performance, we derive a new convergence bound which analytically predicts how clients' arbitrary participation levels and their heterogeneous data affect the model performance. By solving a non-convex optimization problem, our analysis reveals that the intrinsic value leads to the interesting possibility of bidirectional payment between the server and clients. Experimental results using real datasets on a hardware prototype demonstrate the superiority of our mechanism in achieving higher model performance for the server as well as higher profits for the clients.
Robust and Resource-efficient Machine Learning Aided Viewport Prediction in Virtual Reality
Dec 20, 2022
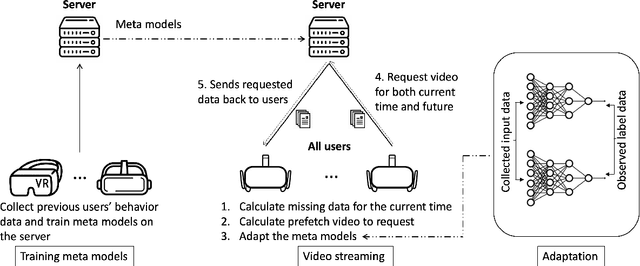
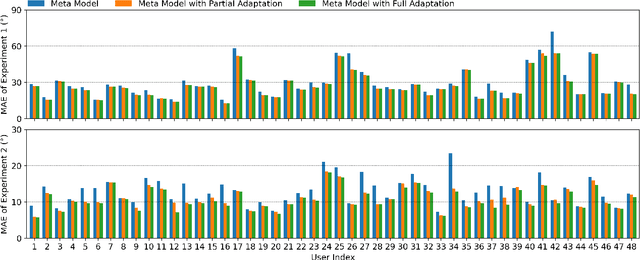
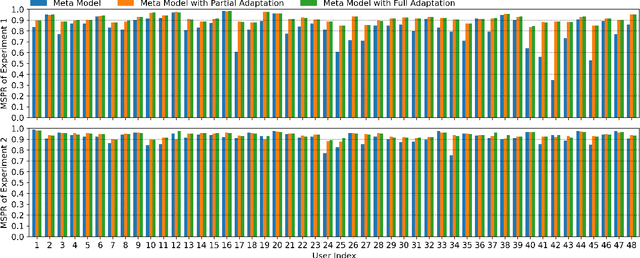
360-degree panoramic videos have gained considerable attention in recent years due to the rapid development of head-mounted displays (HMDs) and panoramic cameras. One major problem in streaming panoramic videos is that panoramic videos are much larger in size compared to traditional ones. Moreover, the user devices are often in a wireless environment, with limited battery, computation power, and bandwidth. To reduce resource consumption, researchers have proposed ways to predict the users' viewports so that only part of the entire video needs to be transmitted from the server. However, the robustness of such prediction approaches has been overlooked in the literature: it is usually assumed that only a few models, pre-trained on past users' experiences, are applied for prediction to all users. We observe that those pre-trained models can perform poorly for some users because they might have drastically different behaviors from the majority, and the pre-trained models cannot capture the features in unseen videos. In this work, we propose a novel meta learning based viewport prediction paradigm to alleviate the worst prediction performance and ensure the robustness of viewport prediction. This paradigm uses two machine learning models, where the first model predicts the viewing direction, and the second model predicts the minimum video prefetch size that can include the actual viewport. We first train two meta models so that they are sensitive to new training data, and then quickly adapt them to users while they are watching the videos. Evaluation results reveal that the meta models can adapt quickly to each user, and can significantly increase the prediction accuracy, especially for the worst-performing predictions.