 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuan Lin
PolyLM: An Open Source Polyglot Large Language Model
Jul 12, 2023
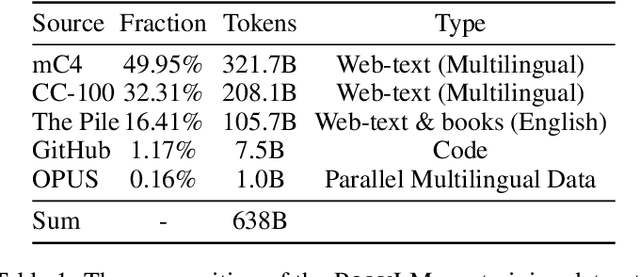

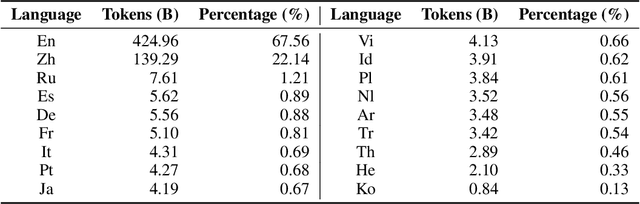
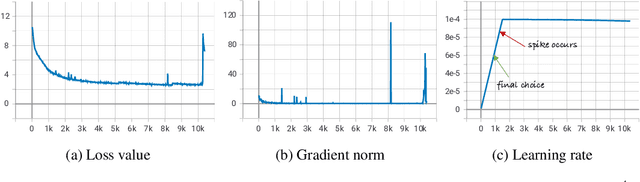
Large language models (LLMs) demonstrate remarkable ability to comprehend, reason, and generate following nature language instructions. However, the development of LLMs has been primarily focused on high-resource languages, such as English, thereby limiting their applicability and research in other languages. Consequently, we present PolyLM, a multilingual LLM trained on 640 billion (B) tokens, avaliable in two model sizes: 1.7B and 13B. To enhance its multilingual capabilities, we 1) integrate bilingual data into training data; and 2) adopt a curriculum learning strategy that increases the proportion of non-English data from 30% in the first stage to 60% in the final stage during pre-training. Further, we propose a multilingual self-instruct method which automatically generates 132.7K diverse multilingual instructions for model fine-tuning. To assess the model's performance, we collect several existing multilingual tasks, including multilingual understanding, question answering, generation, and translation. Extensive experiments show that PolyLM surpasses other open-source models such as LLaMA and BLOOM on multilingual tasks while maintaining comparable performance in English. Our models, alone with the instruction data and multilingual benchmark, are available at: \url{https://modelscope.cn/models/damo/nlp_polylm_13b_text_generation}.
Bridging the Domain Gaps in Context Representations for k-Nearest Neighbor Neural Machine Translation
May 26, 2023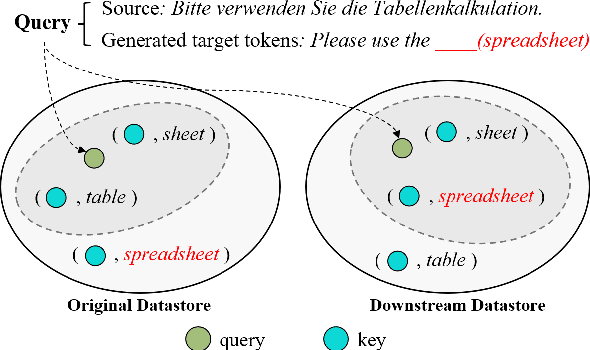
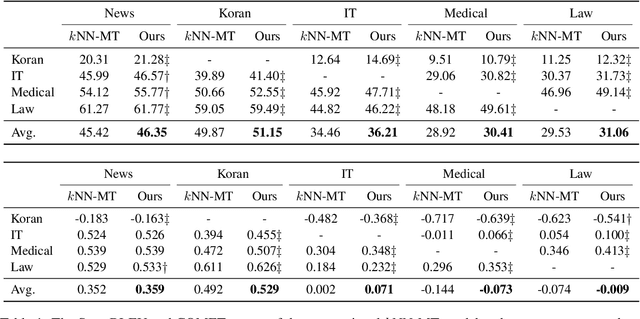
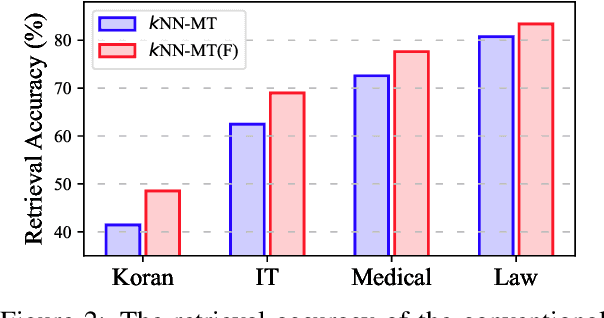
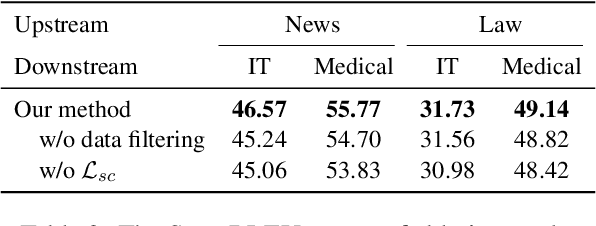
$k$-Nearest neighbor machine translation ($k$NN-MT) has attracted increasing attention due to its ability to non-parametrically adapt to new translation domains. By using an upstream NMT model to traverse the downstream training corpus, it is equipped with a datastore containing vectorized key-value pairs, which are retrieved during inference to benefit translation. However, there often exists a significant gap between upstream and downstream domains, which hurts the retrieval accuracy and the final translation quality. To deal with this issue, we propose a novel approach to boost the datastore retrieval of $k$NN-MT by reconstructing the original datastore. Concretely, we design a reviser to revise the key representations, making them better fit for the downstream domain. The reviser is trained using the collected semantically-related key-queries pairs, and optimized by two proposed losses: one is the key-queries semantic distance ensuring each revised key representation is semantically related to its corresponding queries, and the other is an L2-norm loss encouraging revised key representations to effectively retain the knowledge learned by the upstream NMT model. Extensive experiments on domain adaptation tasks demonstrate that our method can effectively boost the datastore retrieval and translation quality of $k$NN-MT.\footnote{Our code is available at \url{https://github.com/DeepLearnXMU/RevisedKey-knn-mt}.}
From Statistical Methods to Deep Learning, Automatic Keyphrase Prediction: A Survey
May 04, 2023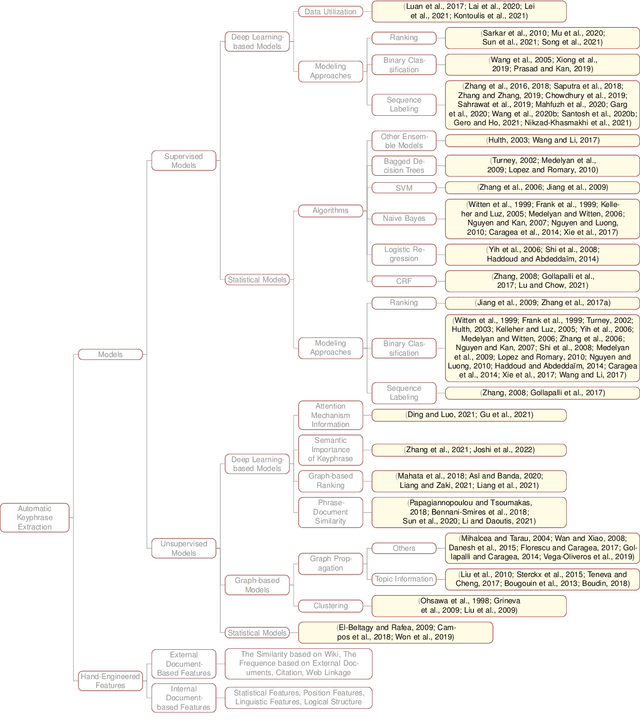
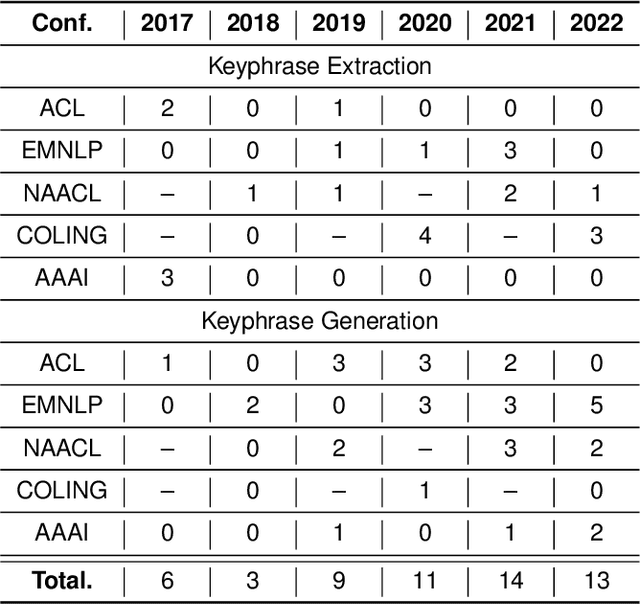
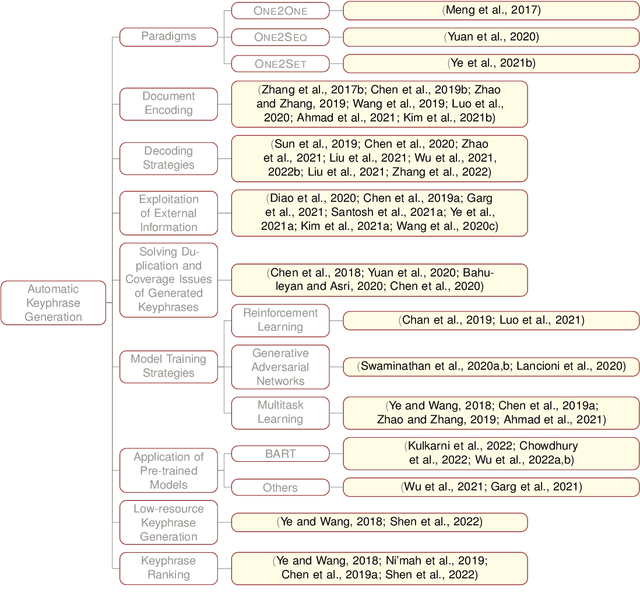
Keyphrase prediction aims to generate phrases (keyphrases) that highly summarizes a given document. Recently, researchers have conducted in-depth studies on this task from various perspectives. In this paper, we comprehensively summarize representative studies from the perspectives of dominant models, datasets and evaluation metrics. Our work analyzes up to 167 previous works, achieving greater coverage of this task than previous surveys. Particularly, we focus highly on deep learning-based keyphrase prediction, which attracts increasing attention of this task in recent years. Afterwards, we conduct several groups of experiments to carefully compare representative models. To the best of our knowledge, our work is the first attempt to compare these models using the identical commonly-used datasets and evaluation metric, facilitating in-depth analyses of their disadvantages and advantages. Finally, we discuss the possible research directions of this task in the future.
WR-ONE2SET: Towards Well-Calibrated Keyphrase Generation
Nov 13, 2022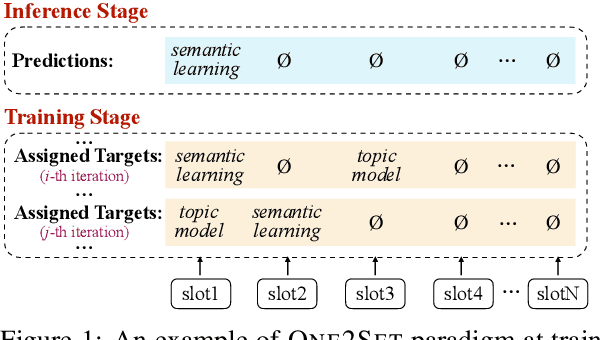
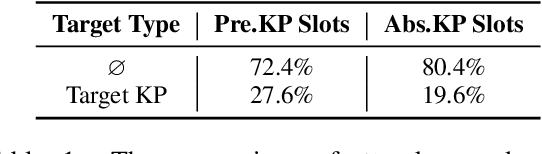

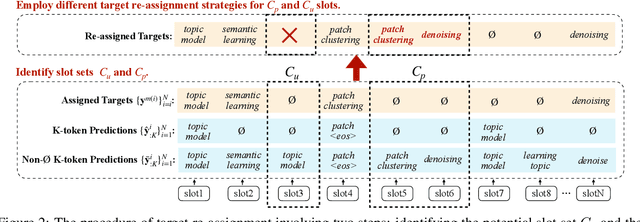
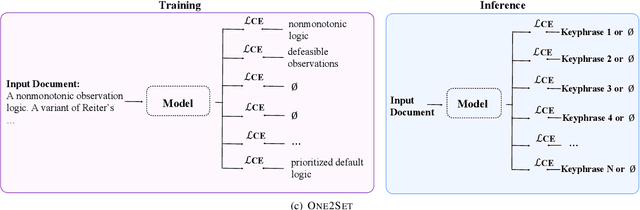
Keyphrase generation aims to automatically generate short phrases summarizing an input document. The recently emerged ONE2SET paradigm (Ye et al., 2021) generates keyphrases as a set and has achieved competitive performance. Nevertheless, we observe serious calibration errors outputted by ONE2SET, especially in the over-estimation of $\varnothing$ token (means "no corresponding keyphrase"). In this paper, we deeply analyze this limitation and identify two main reasons behind: 1) the parallel generation has to introduce excessive $\varnothing$ as padding tokens into training instances; and 2) the training mechanism assigning target to each slot is unstable and further aggravates the $\varnothing$ token over-estimation. To make the model well-calibrated, we propose WR-ONE2SET which extends ONE2SET with an adaptive instance-level cost Weighting strategy and a target Re-assignment mechanism. The former dynamically penalizes the over-estimated slots for different instances thus smoothing the uneven training distribution. The latter refines the original inappropriate assignment and reduces the supervisory signals of over-estimated slots. Experimental results on commonly-used datasets demonstrate the effectiveness and generality of our proposed paradigm.
CKD-TransBTS: Clinical Knowledge-Driven Hybrid Transformer with Modality-Correlated Cross-Attention for Brain Tumor Segmentation
Jul 15, 2022
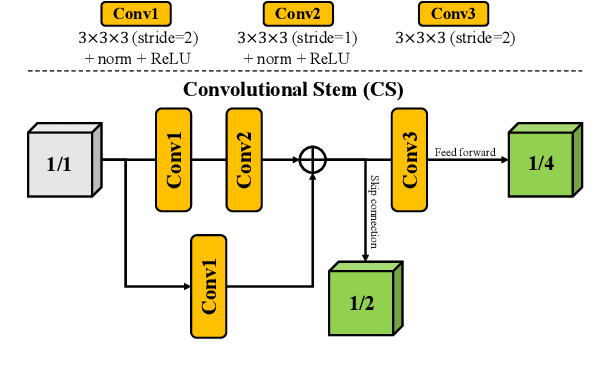

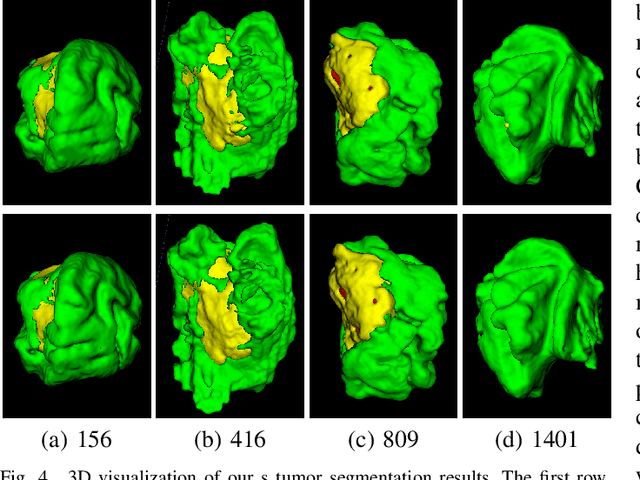
Brain tumor segmentation (BTS) in magnetic resonance image (MRI) is crucial for brain tumor diagnosis, cancer management and research purposes. With the great success of the ten-year BraTS challenges as well as the advances of CNN and Transformer algorithms, a lot of outstanding BTS models have been proposed to tackle the difficulties of BTS in different technical aspects. However, existing studies hardly consider how to fuse the multi-modality images in a reasonable manner. In this paper, we leverage the clinical knowledge of how radiologists diagnose brain tumors from multiple MRI modalities and propose a clinical knowledge-driven brain tumor segmentation model, called CKD-TransBTS. Instead of directly concatenating all the modalities, we re-organize the input modalities by separating them into two groups according to the imaging principle of MRI. A dual-branch hybrid encoder with the proposed modality-correlated cross-attention block (MCCA) is designed to extract the multi-modality image features. The proposed model inherits the strengths from both Transformer and CNN with the local feature representation ability for precise lesion boundaries and long-range feature extraction for 3D volumetric images. To bridge the gap between Transformer and CNN features, we propose a Trans&CNN Feature Calibration block (TCFC) in the decoder. We compare the proposed model with five CNN-based models and six transformer-based models on the BraTS 2021 challenge dataset. Extensive experiments demonstrate that the proposed model achieves state-of-the-art brain tumor segmentation performance compared with all the competitors.
WSSS4LUAD: Grand Challenge on Weakly-supervised Tissue Semantic Segmentation for Lung Adenocarcinoma
Apr 14, 2022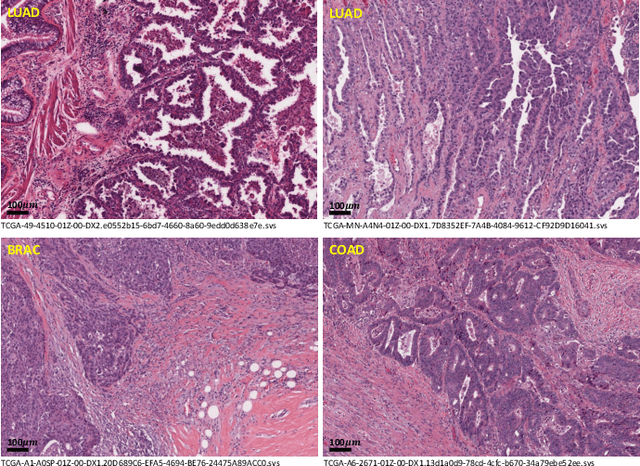
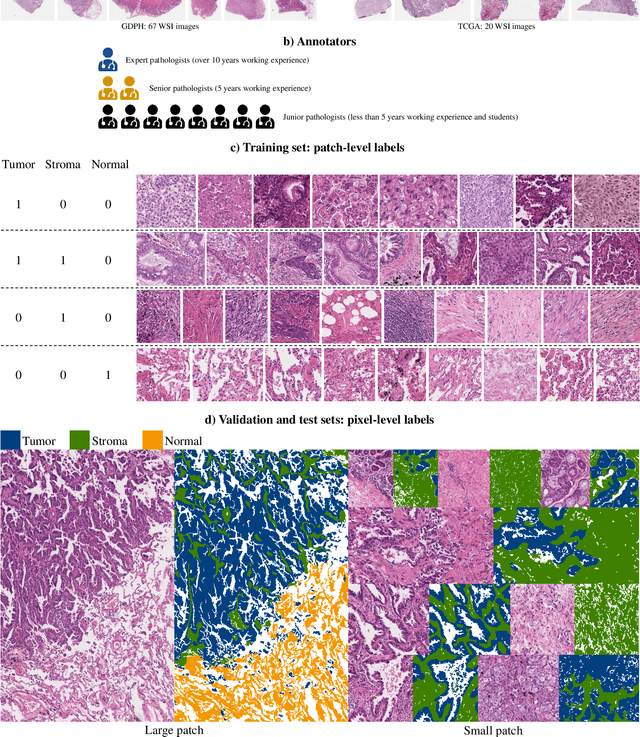
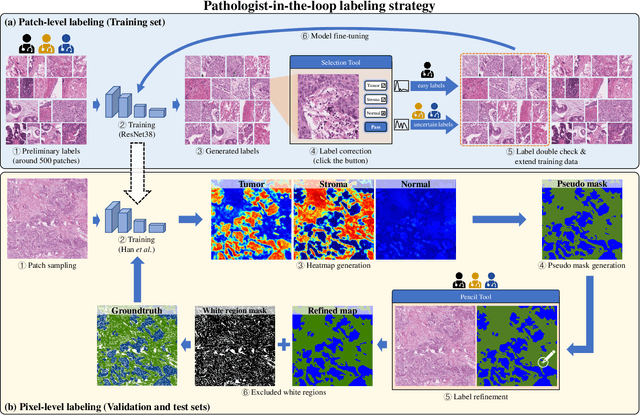
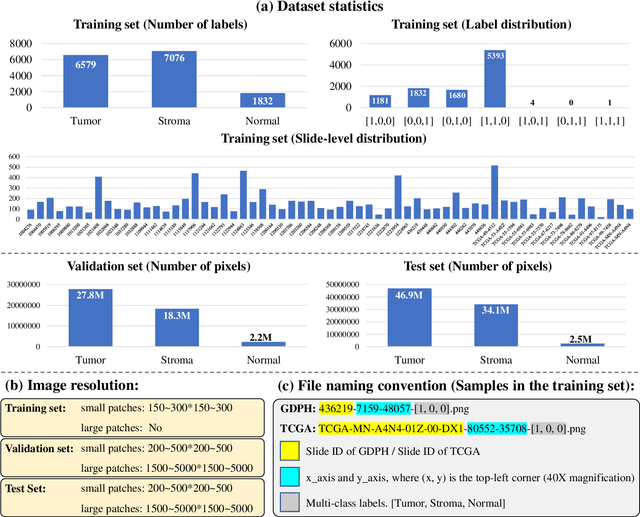
Lung cancer is the leading cause of cancer death worldwide, and adenocarcinoma (LUAD) is the most common subtype. Exploiting the potential value of the histopathology images can promote precision medicine in oncology. Tissue segmentation is the basic upstream task of histopathology image analysis. Existing deep learning models have achieved superior segmentation performance but require sufficient pixel-level annotations, which is time-consuming and expensive. To enrich the label resources of LUAD and to alleviate the annotation efforts, we organize this challenge WSSS4LUAD to call for the outstanding weakly-supervised semantic segmentation (WSSS) techniques for histopathology images of LUAD. Participants have to design the algorithm to segment tumor epithelial, tumor-associated stroma and normal tissue with only patch-level labels. This challenge includes 10,091 patch-level annotations (the training set) and over 130 million labeled pixels (the validation and test sets), from 87 WSIs (67 from GDPH, 20 from TCGA). All the labels were generated by a pathologist-in-the-loop pipeline with the help of AI models and checked by the label review board. Among 532 registrations, 28 teams submitted the results in the test phase with over 1,000 submissions. Finally, the first place team achieved mIoU of 0.8413 (tumor: 0.8389, stroma: 0.7931, normal: 0.8919). According to the technical reports of the top-tier teams, CAM is still the most popular approach in WSSS. Cutmix data augmentation has been widely adopted to generate more reliable samples. With the success of this challenge, we believe that WSSS approaches with patch-level annotations can be a complement to the traditional pixel annotations while reducing the annotation efforts. The entire dataset has been released to encourage more researches on computational pathology in LUAD and more novel WSSS techniques.
Multi-Layer Pseudo-Supervision for Histopathology Tissue Semantic Segmentation using Patch-level Classification Labels
Oct 14, 2021



Tissue-level semantic segmentation is a vital step in computational pathology. Fully-supervised models have already achieved outstanding performance with dense pixel-level annotations. However, drawing such labels on the giga-pixel whole slide images is extremely expensive and time-consuming. In this paper, we use only patch-level classification labels to achieve tissue semantic segmentation on histopathology images, finally reducing the annotation efforts. We proposed a two-step model including a classification and a segmentation phases. In the classification phase, we proposed a CAM-based model to generate pseudo masks by patch-level labels. In the segmentation phase, we achieved tissue semantic segmentation by our proposed Multi-Layer Pseudo-Supervision. Several technical novelties have been proposed to reduce the information gap between pixel-level and patch-level annotations. As a part of this paper, we introduced a new weakly-supervised semantic segmentation (WSSS) dataset for lung adenocarcinoma (LUAD-HistoSeg). We conducted several experiments to evaluate our proposed model on two datasets. Our proposed model outperforms two state-of-the-art WSSS approaches. Note that we can achieve comparable quantitative and qualitative results with the fully-supervised model, with only around a 2\% gap for MIoU and FwIoU. By comparing with manual labeling, our model can greatly save the annotation time from hours to minutes. The source code is available at: \url{https://github.com/ChuHan89/WSSS-Tissue}.
Towards User-Driven Neural Machine Translation
Jun 11, 2021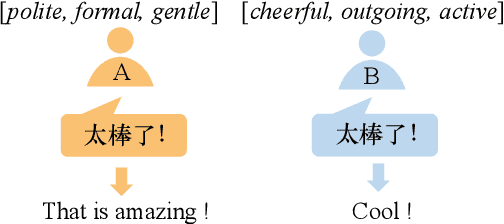
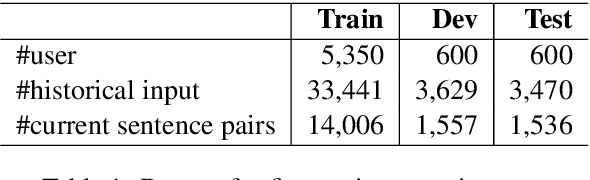
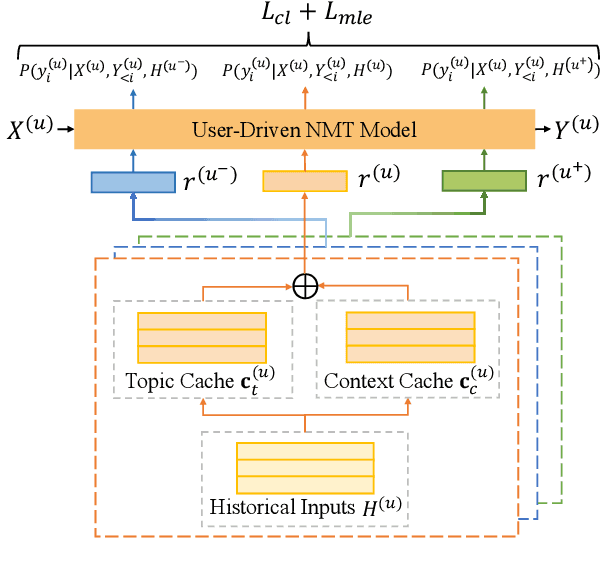
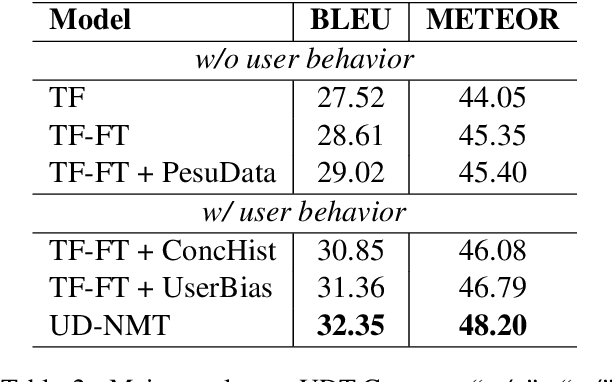
A good translation should not only translate the original content semantically, but also incarnate personal traits of the original text. For a real-world neural machine translation (NMT) system, these user traits (e.g., topic preference, stylistic characteristics and expression habits) can be preserved in user behavior (e.g., historical inputs). However, current NMT systems marginally consider the user behavior due to: 1) the difficulty of modeling user portraits in zero-shot scenarios, and 2) the lack of user-behavior annotated parallel dataset. To fill this gap, we introduce a novel framework called user-driven NMT. Specifically, a cache-based module and a user-driven contrastive learning method are proposed to offer NMT the ability to capture potential user traits from their historical inputs under a zero-shot learning fashion. Furthermore, we contribute the first Chinese-English parallel corpus annotated with user behavior called UDT-Corpus. Experimental results confirm that the proposed user-driven NMT can generate user-specific translations.
Dynamic Context-guided Capsule Network for Multimodal Machine Translation
Sep 04, 2020



Multimodal machine translation (MMT), which mainly focuses on enhancing text-only translation with visual features, has attracted considerable attention from both computer vision and natural language processing communities. Most current MMT models resort to attention mechanism, global context modeling or multimodal joint representation learning to utilize visual features. However, the attention mechanism lacks sufficient semantic interactions between modalities while the other two provide fixed visual context, which is unsuitable for modeling the observed variability when generating translation. To address the above issues, in this paper, we propose a novel Dynamic Context-guided Capsule Network (DCCN) for MMT. Specifically, at each timestep of decoding, we first employ the conventional source-target attention to produce a timestep-specific source-side context vector. Next, DCCN takes this vector as input and uses it to guide the iterative extraction of related visual features via a context-guided dynamic routing mechanism. Particularly, we represent the input image with global and regional visual features, we introduce two parallel DCCNs to model multimodal context vectors with visual features at different granularities. Finally, we obtain two multimodal context vectors, which are fused and incorporated into the decoder for the prediction of the target word. Experimental results on the Multi30K dataset of English-to-German and English-to-French translation demonstrate the superiority of DCCN. Our code is available on https://github.com/DeepLearnXMU/MM-DCCN.
New models for symbolic data analysis
Sep 11, 2018



Symbolic data analysis (SDA) is an emerging area of statistics based on aggregating individual level data into group-based distributional summaries (symbols), and then developing statistical methods to analyse them. It is ideal for analysing large and complex datasets, and has immense potential to become a standard inferential technique in the near future. However, existing SDA techniques are either non-inferential, do not easily permit meaningful statistical models, are unable to distinguish between competing models, and are based on simplifying assumptions that are known to be false. Further, the procedure for constructing symbols from the underlying data is erroneously not considered relevant to the resulting statistical analysis. In this paper we introduce a new general method for constructing likelihood functions for symbolic data based on a desired probability model for the underlying classical data, while only observing the distributional summaries. This approach resolves many of the conceptual and practical issues with current SDA methods, opens the door for new classes of symbol design and construction, in addition to developing SDA as a viable tool to enable and improve upon classical data analyses, particularly for very large and complex datasets. This work creates a new direction for SDA research, which we illustrate through several real and simulated data analyses.