 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiangying Shao
A Sequence-to-Sequence&Set Model for Text-to-Table Generation
May 31, 2023
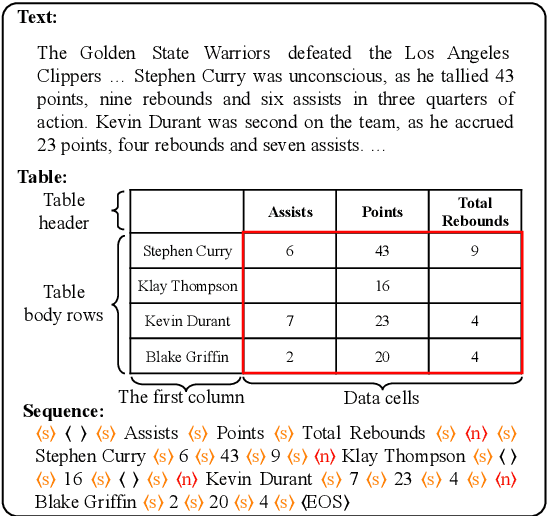
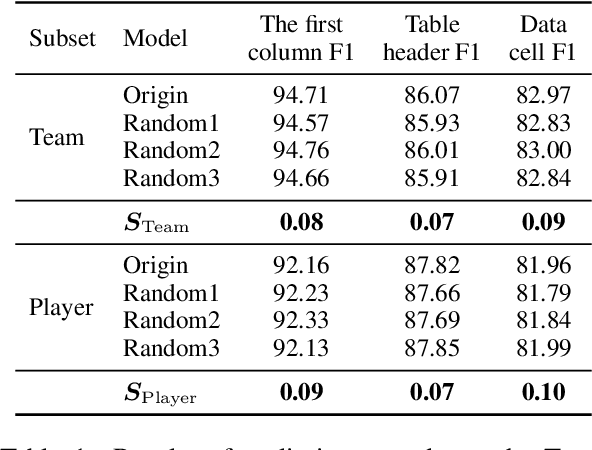
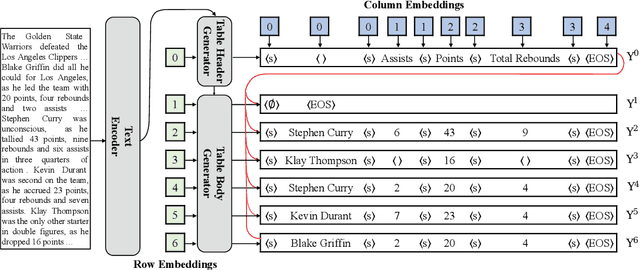
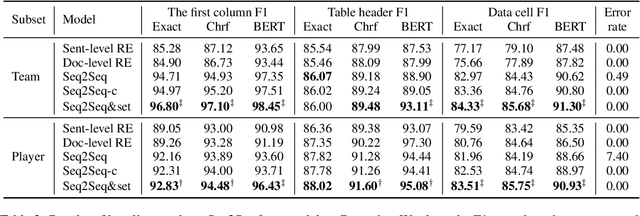
Recently, the text-to-table generation task has attracted increasing attention due to its wide applications. In this aspect, the dominant model formalizes this task as a sequence-to-sequence generation task and serializes each table into a token sequence during training by concatenating all rows in a top-down order. However, it suffers from two serious defects: 1) the predefined order introduces a wrong bias during training, which highly penalizes shifts in the order between rows; 2) the error propagation problem becomes serious when the model outputs a long token sequence. In this paper, we first conduct a preliminary study to demonstrate the generation of most rows is order-insensitive. Furthermore, we propose a novel sequence-to-sequence&set text-to-table generation model. Specifically, in addition to a text encoder encoding the input text, our model is equipped with a table header generator to first output a table header, i.e., the first row of the table, in the manner of sequence generation. Then we use a table body generator with learnable row embeddings and column embeddings to generate a set of table body rows in parallel. Particularly, to deal with the issue that there is no correspondence between each generated table body row and target during training, we propose a target assignment strategy based on the bipartite matching between the first cells of generated table body rows and targets. Experiment results show that our model significantly surpasses the baselines, achieving state-of-the-art performance on commonly-used datasets.
From Statistical Methods to Deep Learning, Automatic Keyphrase Prediction: A Survey
May 04, 2023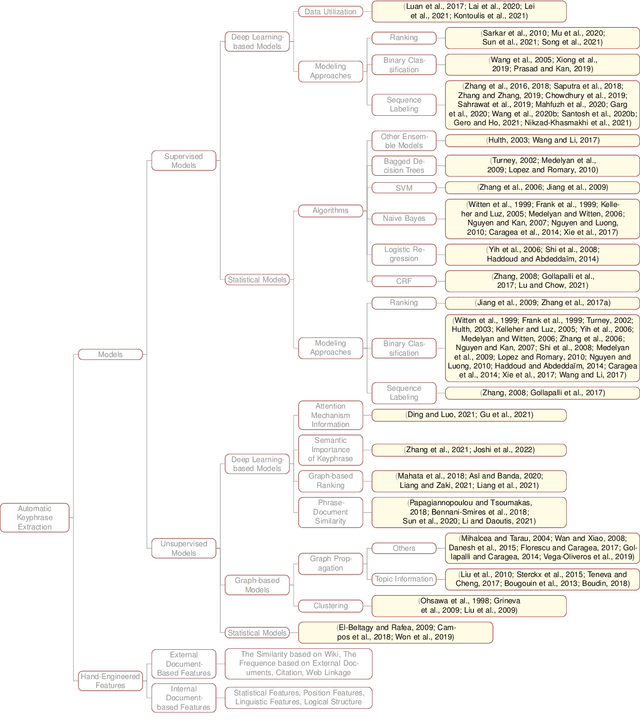
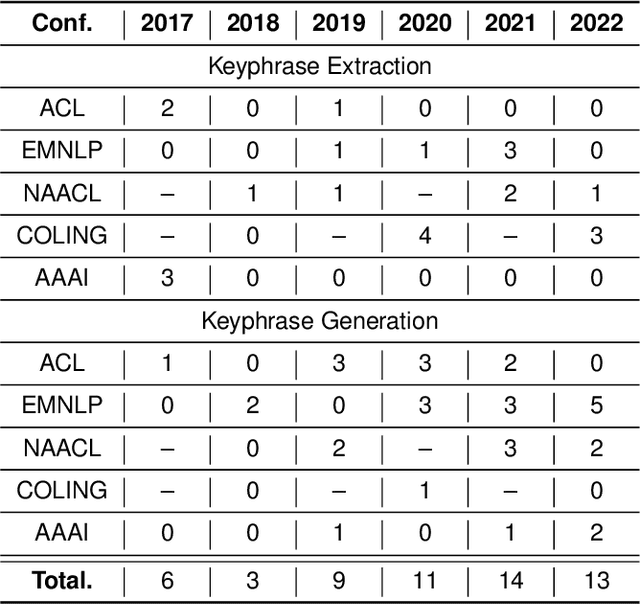
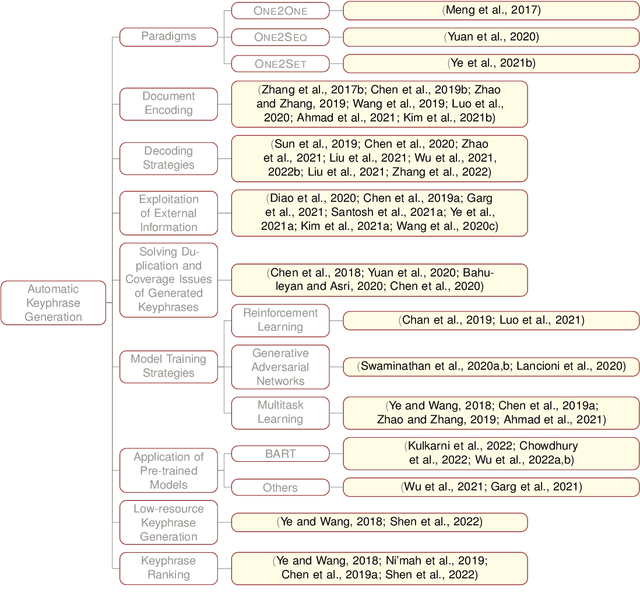
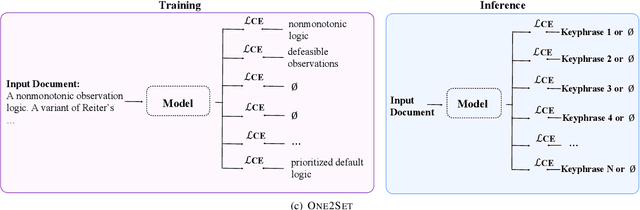
Keyphrase prediction aims to generate phrases (keyphrases) that highly summarizes a given document. Recently, researchers have conducted in-depth studies on this task from various perspectives. In this paper, we comprehensively summarize representative studies from the perspectives of dominant models, datasets and evaluation metrics. Our work analyzes up to 167 previous works, achieving greater coverage of this task than previous surveys. Particularly, we focus highly on deep learning-based keyphrase prediction, which attracts increasing attention of this task in recent years. Afterwards, we conduct several groups of experiments to carefully compare representative models. To the best of our knowledge, our work is the first attempt to compare these models using the identical commonly-used datasets and evaluation metric, facilitating in-depth analyses of their disadvantages and advantages. Finally, we discuss the possible research directions of this task in the future.