 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuzammal Naseer
Cross-Modal Self-Training: Aligning Images and Pointclouds to Learn Classification without Labels
Apr 15, 2024
Large-scale vision 2D vision language models, such as CLIP can be aligned with a 3D encoder to learn generalizable (open-vocabulary) 3D vision models. However, current methods require supervised pre-training for such alignment, and the performance of such 3D zero-shot models remains sub-optimal for real-world adaptation. In this work, we propose an optimization framework: Cross-MoST: Cross-Modal Self-Training, to improve the label-free classification performance of a zero-shot 3D vision model by simply leveraging unlabeled 3D data and their accompanying 2D views. We propose a student-teacher framework to simultaneously process 2D views and 3D point clouds and generate joint pseudo labels to train a classifier and guide cross-model feature alignment. Thereby we demonstrate that 2D vision language models such as CLIP can be used to complement 3D representation learning to improve classification performance without the need for expensive class annotations. Using synthetic and real-world 3D datasets, we further demonstrate that Cross-MoST enables efficient cross-modal knowledge exchange resulting in both image and point cloud modalities learning from each other's rich representations.
Language Guided Domain Generalized Medical Image Segmentation
Apr 03, 2024Single source domain generalization (SDG) holds promise for more reliable and consistent image segmentation across real-world clinical settings particularly in the medical domain, where data privacy and acquisition cost constraints often limit the availability of diverse datasets. Depending solely on visual features hampers the model's capacity to adapt effectively to various domains, primarily because of the presence of spurious correlations and domain-specific characteristics embedded within the image features. Incorporating text features alongside visual features is a potential solution to enhance the model's understanding of the data, as it goes beyond pixel-level information to provide valuable context. Textual cues describing the anatomical structures, their appearances, and variations across various imaging modalities can guide the model in domain adaptation, ultimately contributing to more robust and consistent segmentation. In this paper, we propose an approach that explicitly leverages textual information by incorporating a contrastive learning mechanism guided by the text encoder features to learn a more robust feature representation. We assess the effectiveness of our text-guided contrastive feature alignment technique in various scenarios, including cross-modality, cross-sequence, and cross-site settings for different segmentation tasks. Our approach achieves favorable performance against existing methods in literature. Our code and model weights are available at https://github.com/ShahinaKK/LG_SDG.git.
Composed Video Retrieval via Enriched Context and Discriminative Embeddings
Mar 25, 2024Composed video retrieval (CoVR) is a challenging problem in computer vision which has recently highlighted the integration of modification text with visual queries for more sophisticated video search in large databases. Existing works predominantly rely on visual queries combined with modification text to distinguish relevant videos. However, such a strategy struggles to fully preserve the rich query-specific context in retrieved target videos and only represents the target video using visual embedding. We introduce a novel CoVR framework that leverages detailed language descriptions to explicitly encode query-specific contextual information and learns discriminative embeddings of vision only, text only and vision-text for better alignment to accurately retrieve matched target videos. Our proposed framework can be flexibly employed for both composed video (CoVR) and image (CoIR) retrieval tasks. Experiments on three datasets show that our approach obtains state-of-the-art performance for both CovR and zero-shot CoIR tasks, achieving gains as high as around 7% in terms of recall@K=1 score. Our code, models, detailed language descriptions for WebViD-CoVR dataset are available at \url{https://github.com/OmkarThawakar/composed-video-retrieval}
VURF: A General-purpose Reasoning and Self-refinement Framework for Video Understanding
Mar 25, 2024Recent studies have demonstrated the effectiveness of Large Language Models (LLMs) as reasoning modules that can deconstruct complex tasks into more manageable sub-tasks, particularly when applied to visual reasoning tasks for images. In contrast, this paper introduces a Video Understanding and Reasoning Framework (VURF) based on the reasoning power of LLMs. Ours is a novel approach to extend the utility of LLMs in the context of video tasks, leveraging their capacity to generalize from minimal input and output demonstrations within a contextual framework. By presenting LLMs with pairs of instructions and their corresponding high-level programs, we harness their contextual learning capabilities to generate executable visual programs for video understanding. To enhance program's accuracy and robustness, we implement two important strategies. Firstly, we employ a feedback-generation approach, powered by GPT-3.5, to rectify errors in programs utilizing unsupported functions. Secondly, taking motivation from recent works on self refinement of LLM outputs, we introduce an iterative procedure for improving the quality of the in-context examples by aligning the initial outputs to the outputs that would have been generated had the LLM not been bound by the structure of the in-context examples. Our results on several video-specific tasks, including visual QA, video anticipation, pose estimation and multi-video QA illustrate the efficacy of these enhancements in improving the performance of visual programming approaches for video tasks.
Hierarchical Text-to-Vision Self Supervised Alignment for Improved Histopathology Representation Learning
Mar 21, 2024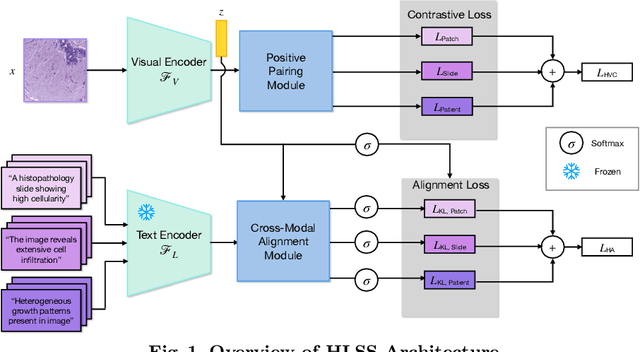
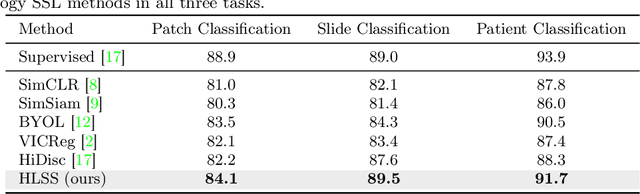
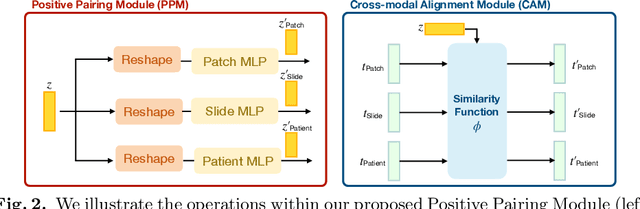
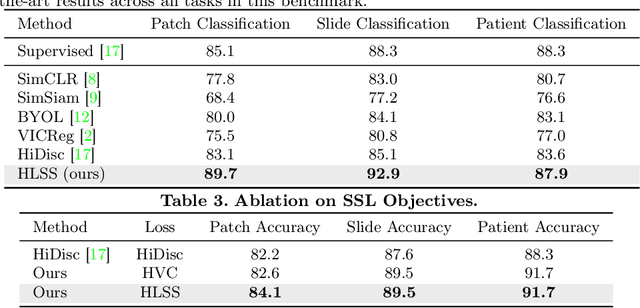
Self-supervised representation learning has been highly promising for histopathology image analysis with numerous approaches leveraging their patient-slide-patch hierarchy to learn better representations. In this paper, we explore how the combination of domain specific natural language information with such hierarchical visual representations can benefit rich representation learning for medical image tasks. Building on automated language description generation for features visible in histopathology images, we present a novel language-tied self-supervised learning framework, Hierarchical Language-tied Self-Supervision (HLSS) for histopathology images. We explore contrastive objectives and granular language description based text alignment at multiple hierarchies to inject language modality information into the visual representations. Our resulting model achieves state-of-the-art performance on two medical imaging benchmarks, OpenSRH and TCGA datasets. Our framework also provides better interpretability with our language aligned representation space. Code is available at https://github.com/Hasindri/HLSS.
ObjectCompose: Evaluating Resilience of Vision-Based Models on Object-to-Background Compositional Changes
Mar 15, 2024
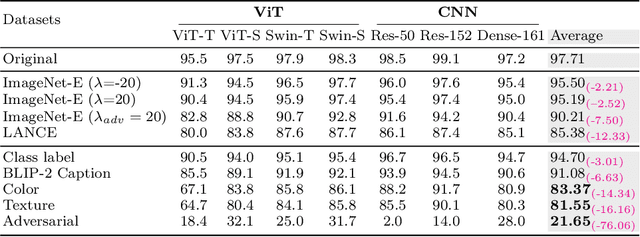
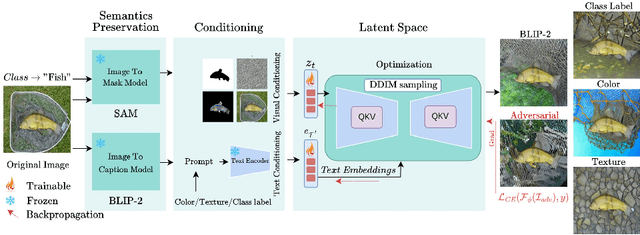
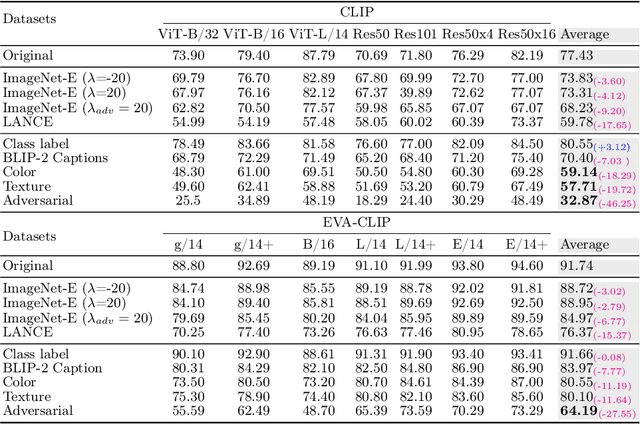
Given the large-scale multi-modal training of recent vision-based models and their generalization capabilities, understanding the extent of their robustness is critical for their real-world deployment. In this work, we evaluate the resilience of current vision-based models against diverse object-to-background context variations. The majority of robustness evaluation methods have introduced synthetic datasets to induce changes to object characteristics (viewpoints, scale, color) or utilized image transformation techniques (adversarial changes, common corruptions) on real images to simulate shifts in distributions. Recent works have explored leveraging large language models and diffusion models to generate changes in the background. However, these methods either lack in offering control over the changes to be made or distort the object semantics, making them unsuitable for the task. Our method, on the other hand, can induce diverse object-to-background changes while preserving the original semantics and appearance of the object. To achieve this goal, we harness the generative capabilities of text-to-image, image-to-text, and image-to-segment models to automatically generate a broad spectrum of object-to-background changes. We induce both natural and adversarial background changes by either modifying the textual prompts or optimizing the latents and textual embedding of text-to-image models. This allows us to quantify the role of background context in understanding the robustness and generalization of deep neural networks. We produce various versions of standard vision datasets (ImageNet, COCO), incorporating either diverse and realistic backgrounds into the images or introducing color, texture, and adversarial changes in the background. We conduct extensive experiment to analyze the robustness of vision-based models against object-to-background context variations across diverse tasks.
Rethinking Transformers Pre-training for Multi-Spectral Satellite Imagery
Mar 08, 2024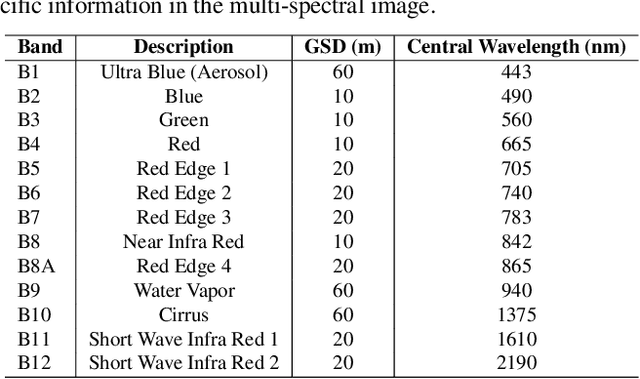
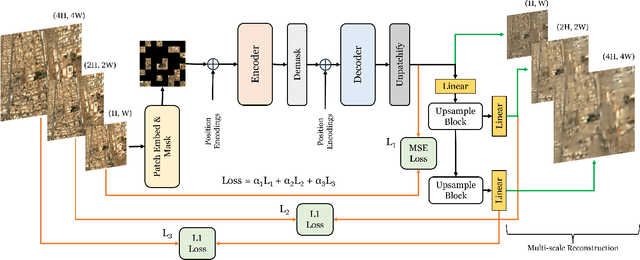
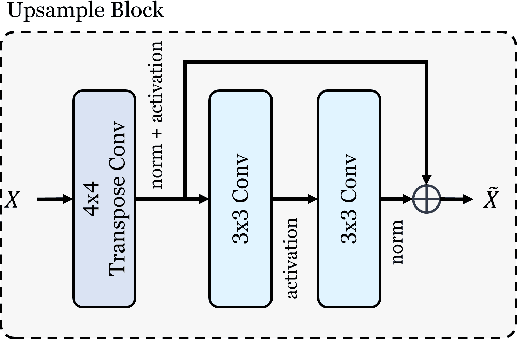
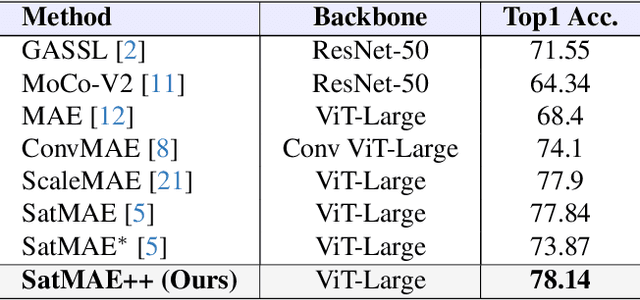
Recent advances in unsupervised learning have demonstrated the ability of large vision models to achieve promising results on downstream tasks by pre-training on large amount of unlabelled data. Such pre-training techniques have also been explored recently in the remote sensing domain due to the availability of large amount of unlabelled data. Different from standard natural image datasets, remote sensing data is acquired from various sensor technologies and exhibit diverse range of scale variations as well as modalities. Existing satellite image pre-training methods either ignore the scale information present in the remote sensing imagery or restrict themselves to use only a single type of data modality. In this paper, we re-visit transformers pre-training and leverage multi-scale information that is effectively utilized with multiple modalities. Our proposed approach, named SatMAE++, performs multi-scale pre-training and utilizes convolution based upsampling blocks to reconstruct the image at higher scales making it extensible to include more scales. Compared to existing works, the proposed SatMAE++ with multi-scale pre-training is equally effective for both optical as well as multi-spectral imagery. Extensive experiments on six datasets reveal the merits of proposed contributions, leading to state-of-the-art performance on all datasets. SatMAE++ achieves mean average precision (mAP) gain of 2.5\% for multi-label classification task on BigEarthNet dataset. Our code and pre-trained models are available at \url{https://github.com/techmn/satmae_pp}.
MedContext: Learning Contextual Cues for Efficient Volumetric Medical Segmentation
Feb 27, 2024Volumetric medical segmentation is a critical component of 3D medical image analysis that delineates different semantic regions. Deep neural networks have significantly improved volumetric medical segmentation, but they generally require large-scale annotated data to achieve better performance, which can be expensive and prohibitive to obtain. To address this limitation, existing works typically perform transfer learning or design dedicated pretraining-finetuning stages to learn representative features. However, the mismatch between the source and target domain can make it challenging to learn optimal representation for volumetric data, while the multi-stage training demands higher compute as well as careful selection of stage-specific design choices. In contrast, we propose a universal training framework called MedContext that is architecture-agnostic and can be incorporated into any existing training framework for 3D medical segmentation. Our approach effectively learns self supervised contextual cues jointly with the supervised voxel segmentation task without requiring large-scale annotated volumetric medical data or dedicated pretraining-finetuning stages. The proposed approach induces contextual knowledge in the network by learning to reconstruct the missing organ or parts of an organ in the output segmentation space. The effectiveness of MedContext is validated across multiple 3D medical datasets and four state-of-the-art model architectures. Our approach demonstrates consistent gains in segmentation performance across datasets and different architectures even in few-shot data scenarios. Our code and pretrained models are available at https://github.com/hananshafi/MedContext
Learning to Prompt with Text Only Supervision for Vision-Language Models
Jan 04, 2024Foundational vision-language models such as CLIP are becoming a new paradigm in vision, due to their excellent generalization abilities. However, adapting these models for downstream tasks while maintaining their generalization remains a challenge. In literature, one branch of methods adapts CLIP by learning prompts using visual information. While effective, most of these works require labeled data which is not practical, and often struggle to generalize towards new datasets due to over-fitting on the source data. An alternative approach resorts to training-free methods by generating class descriptions from large language models (LLMs) and perform prompt ensembling. However, these methods often generate class specific prompts that cannot be transferred to other classes, which incur higher costs by generating LLM descriptions for each class separately. In this work, we propose to combine the strengths of these both streams of methods by learning prompts using only text data derived from LLMs. As supervised training of prompts is not trivial due to absence of images, we develop a training approach that allows prompts to extract rich contextual knowledge from LLM data. Moreover, with LLM contextual data mapped within the learned prompts, it enables zero-shot transfer of prompts to new classes and datasets potentially cutting the LLM prompt engineering cost. To the best of our knowledge, this is the first work that learns generalized prompts using text only data. We perform extensive evaluations on 4 benchmarks where our method improves over prior ensembling works while being competitive to those utilizing labeled images. Our code and pre-trained models are available at https://github.com/muzairkhattak/ProText.