 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHashmat Shadab Malik
ObjectCompose: Evaluating Resilience of Vision-Based Models on Object-to-Background Compositional Changes
Mar 15, 2024

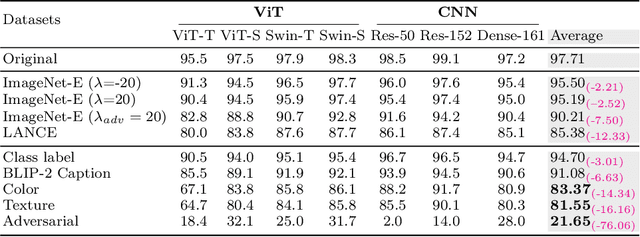
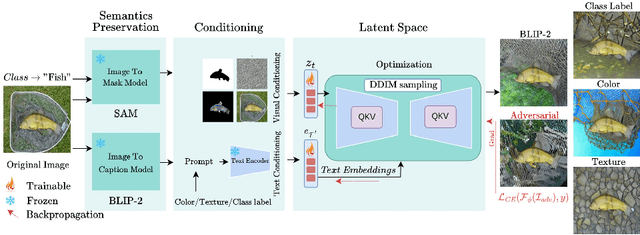
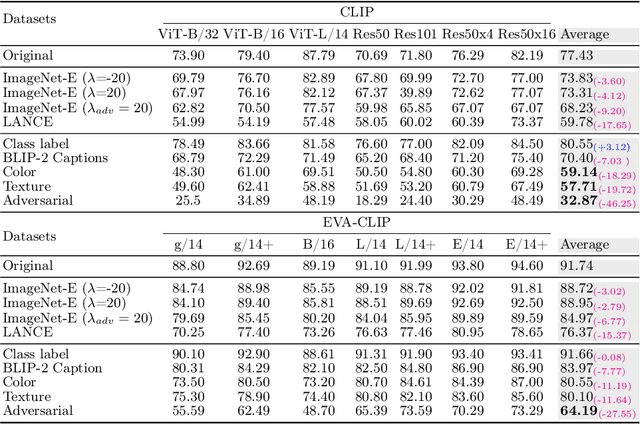
Given the large-scale multi-modal training of recent vision-based models and their generalization capabilities, understanding the extent of their robustness is critical for their real-world deployment. In this work, we evaluate the resilience of current vision-based models against diverse object-to-background context variations. The majority of robustness evaluation methods have introduced synthetic datasets to induce changes to object characteristics (viewpoints, scale, color) or utilized image transformation techniques (adversarial changes, common corruptions) on real images to simulate shifts in distributions. Recent works have explored leveraging large language models and diffusion models to generate changes in the background. However, these methods either lack in offering control over the changes to be made or distort the object semantics, making them unsuitable for the task. Our method, on the other hand, can induce diverse object-to-background changes while preserving the original semantics and appearance of the object. To achieve this goal, we harness the generative capabilities of text-to-image, image-to-text, and image-to-segment models to automatically generate a broad spectrum of object-to-background changes. We induce both natural and adversarial background changes by either modifying the textual prompts or optimizing the latents and textual embedding of text-to-image models. This allows us to quantify the role of background context in understanding the robustness and generalization of deep neural networks. We produce various versions of standard vision datasets (ImageNet, COCO), incorporating either diverse and realistic backgrounds into the images or introducing color, texture, and adversarial changes in the background. We conduct extensive experiment to analyze the robustness of vision-based models against object-to-background context variations across diverse tasks.
Adversarial Pixel Restoration as a Pretext Task for Transferable Perturbations
Jul 18, 2022



Transferable adversarial attacks optimize adversaries from a pretrained surrogate model and known label space to fool the unknown black-box models. Therefore, these attacks are restricted by the availability of an effective surrogate model. In this work, we relax this assumption and propose Adversarial Pixel Restoration as a self-supervised alternative to train an effective surrogate model from scratch under the condition of no labels and few data samples. Our training approach is based on a min-max objective which reduces overfitting via an adversarial objective and thus optimizes for a more generalizable surrogate model. Our proposed attack is complimentary to our adversarial pixel restoration and is independent of any task specific objective as it can be launched in a self-supervised manner. We successfully demonstrate the adversarial transferability of our approach to Vision Transformers as well as Convolutional Neural Networks for the tasks of classification, object detection, and video segmentation. Our codes & pre-trained surrogate models are available at: https://github.com/HashmatShadab/APR
Object Detection in Aerial Images: What Improves the Accuracy?
Jan 21, 2022



Object detection is a challenging and popular computer vision problem. The problem is even more challenging in aerial images due to significant variation in scale and viewpoint in a diverse set of object categories. Recently, deep learning-based object detection approaches have been actively explored for the problem of object detection in aerial images. In this work, we investigate the impact of Faster R-CNN for aerial object detection and explore numerous strategies to improve its performance for aerial images. We conduct extensive experiments on the challenging iSAID dataset. The resulting adapted Faster R-CNN obtains a significant mAP gain of 4.96% over its vanilla baseline counterpart on the iSAID validation set, demonstrating the impact of different strategies investigated in this work.