 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePinar Yanardag
CLoRA: A Contrastive Approach to Compose Multiple LoRA Models
Mar 28, 2024

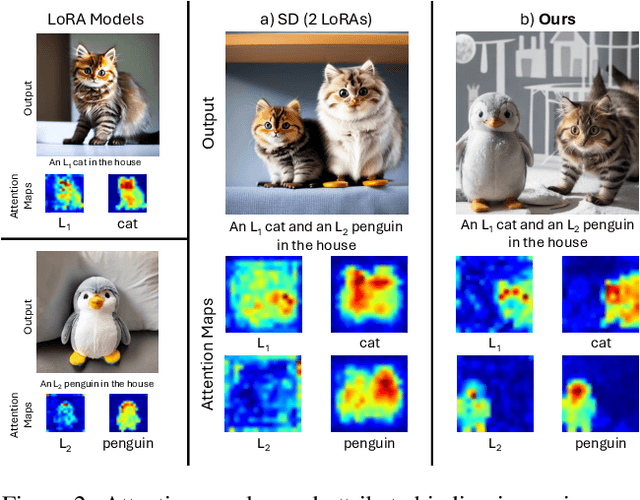
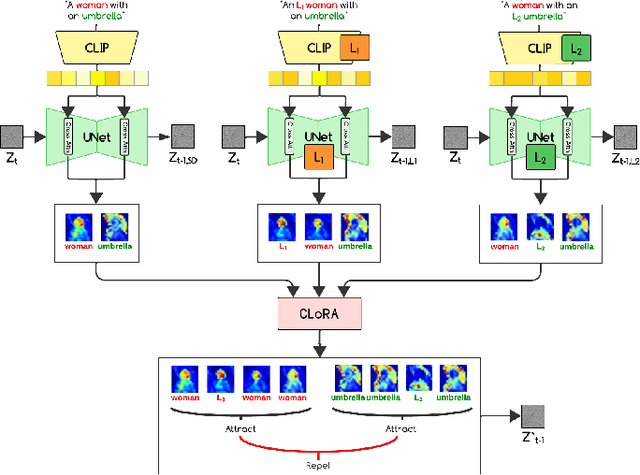

Low-Rank Adaptations (LoRAs) have emerged as a powerful and popular technique in the field of image generation, offering a highly effective way to adapt and refine pre-trained deep learning models for specific tasks without the need for comprehensive retraining. By employing pre-trained LoRA models, such as those representing a specific cat and a particular dog, the objective is to generate an image that faithfully embodies both animals as defined by the LoRAs. However, the task of seamlessly blending multiple concept LoRAs to capture a variety of concepts in one image proves to be a significant challenge. Common approaches often fall short, primarily because the attention mechanisms within different LoRA models overlap, leading to scenarios where one concept may be completely ignored (e.g., omitting the dog) or where concepts are incorrectly combined (e.g., producing an image of two cats instead of one cat and one dog). To overcome these issues, CLoRA addresses them by updating the attention maps of multiple LoRA models and leveraging them to create semantic masks that facilitate the fusion of latent representations. Our method enables the creation of composite images that truly reflect the characteristics of each LoRA, successfully merging multiple concepts or styles. Our comprehensive evaluations, both qualitative and quantitative, demonstrate that our approach outperforms existing methodologies, marking a significant advancement in the field of image generation with LoRAs. Furthermore, we share our source code, benchmark dataset, and trained LoRA models to promote further research on this topic.
GANTASTIC: GAN-based Transfer of Interpretable Directions for Disentangled Image Editing in Text-to-Image Diffusion Models
Mar 28, 2024



The rapid advancement in image generation models has predominantly been driven by diffusion models, which have demonstrated unparalleled success in generating high-fidelity, diverse images from textual prompts. Despite their success, diffusion models encounter substantial challenges in the domain of image editing, particularly in executing disentangled edits-changes that target specific attributes of an image while leaving irrelevant parts untouched. In contrast, Generative Adversarial Networks (GANs) have been recognized for their success in disentangled edits through their interpretable latent spaces. We introduce GANTASTIC, a novel framework that takes existing directions from pre-trained GAN models-representative of specific, controllable attributes-and transfers these directions into diffusion-based models. This novel approach not only maintains the generative quality and diversity that diffusion models are known for but also significantly enhances their capability to perform precise, targeted image edits, thereby leveraging the best of both worlds.
MIST: Mitigating Intersectional Bias with Disentangled Cross-Attention Editing in Text-to-Image Diffusion Models
Mar 28, 2024



Diffusion-based text-to-image models have rapidly gained popularity for their ability to generate detailed and realistic images from textual descriptions. However, these models often reflect the biases present in their training data, especially impacting marginalized groups. While prior efforts to debias language models have focused on addressing specific biases, such as racial or gender biases, efforts to tackle intersectional bias have been limited. Intersectional bias refers to the unique form of bias experienced by individuals at the intersection of multiple social identities. Addressing intersectional bias is crucial because it amplifies the negative effects of discrimination based on race, gender, and other identities. In this paper, we introduce a method that addresses intersectional bias in diffusion-based text-to-image models by modifying cross-attention maps in a disentangled manner. Our approach utilizes a pre-trained Stable Diffusion model, eliminates the need for an additional set of reference images, and preserves the original quality for unaltered concepts. Comprehensive experiments demonstrate that our method surpasses existing approaches in mitigating both single and intersectional biases across various attributes. We make our source code and debiased models for various attributes available to encourage fairness in generative models and to support further research.
CONFORM: Contrast is All You Need For High-Fidelity Text-to-Image Diffusion Models
Dec 11, 2023Images produced by text-to-image diffusion models might not always faithfully represent the semantic intent of the provided text prompt, where the model might overlook or entirely fail to produce certain objects. Existing solutions often require customly tailored functions for each of these problems, leading to sub-optimal results, especially for complex prompts. Our work introduces a novel perspective by tackling this challenge in a contrastive context. Our approach intuitively promotes the segregation of objects in attention maps while also maintaining that pairs of related attributes are kept close to each other. We conduct extensive experiments across a wide variety of scenarios, each involving unique combinations of objects, attributes, and scenes. These experiments effectively showcase the versatility, efficiency, and flexibility of our method in working with both latent and pixel-based diffusion models, including Stable Diffusion and Imagen. Moreover, we publicly share our source code to facilitate further research.
NoiseCLR: A Contrastive Learning Approach for Unsupervised Discovery of Interpretable Directions in Diffusion Models
Dec 08, 2023Generative models have been very popular in the recent years for their image generation capabilities. GAN-based models are highly regarded for their disentangled latent space, which is a key feature contributing to their success in controlled image editing. On the other hand, diffusion models have emerged as powerful tools for generating high-quality images. However, the latent space of diffusion models is not as thoroughly explored or understood. Existing methods that aim to explore the latent space of diffusion models usually relies on text prompts to pinpoint specific semantics. However, this approach may be restrictive in areas such as art, fashion, or specialized fields like medicine, where suitable text prompts might not be available or easy to conceive thus limiting the scope of existing work. In this paper, we propose an unsupervised method to discover latent semantics in text-to-image diffusion models without relying on text prompts. Our method takes a small set of unlabeled images from specific domains, such as faces or cats, and a pre-trained diffusion model, and discovers diverse semantics in unsupervised fashion using a contrastive learning objective. Moreover, the learned directions can be applied simultaneously, either within the same domain (such as various types of facial edits) or across different domains (such as applying cat and face edits within the same image) without interfering with each other. Our extensive experiments show that our method achieves highly disentangled edits, outperforming existing approaches in both diffusion-based and GAN-based latent space editing methods.
RAVE: Randomized Noise Shuffling for Fast and Consistent Video Editing with Diffusion Models
Dec 07, 2023Recent advancements in diffusion-based models have demonstrated significant success in generating images from text. However, video editing models have not yet reached the same level of visual quality and user control. To address this, we introduce RAVE, a zero-shot video editing method that leverages pre-trained text-to-image diffusion models without additional training. RAVE takes an input video and a text prompt to produce high-quality videos while preserving the original motion and semantic structure. It employs a novel noise shuffling strategy, leveraging spatio-temporal interactions between frames, to produce temporally consistent videos faster than existing methods. It is also efficient in terms of memory requirements, allowing it to handle longer videos. RAVE is capable of a wide range of edits, from local attribute modifications to shape transformations. In order to demonstrate the versatility of RAVE, we create a comprehensive video evaluation dataset ranging from object-focused scenes to complex human activities like dancing and typing, and dynamic scenes featuring swimming fish and boats. Our qualitative and quantitative experiments highlight the effectiveness of RAVE in diverse video editing scenarios compared to existing methods. Our code, dataset and videos can be found in https://rave-video.github.io.
3D-LatentMapper: View Agnostic Single-View Reconstruction of 3D Shapes
Dec 05, 2022



Computer graphics, 3D computer vision and robotics communities have produced multiple approaches to represent and generate 3D shapes, as well as a vast number of use cases. However, single-view reconstruction remains a challenging topic that can unlock various interesting use cases such as interactive design. In this work, we propose a novel framework that leverages the intermediate latent spaces of Vision Transformer (ViT) and a joint image-text representational model, CLIP, for fast and efficient Single View Reconstruction (SVR). More specifically, we propose a novel mapping network architecture that learns a mapping between deep features extracted from ViT and CLIP, and the latent space of a base 3D generative model. Unlike previous work, our method enables view-agnostic reconstruction of 3D shapes, even in the presence of large occlusions. We use the ShapeNetV2 dataset and perform extensive experiments with comparisons to SOTA methods to demonstrate our method's effectiveness.
Fantastic Style Channels and Where to Find Them: A Submodular Framework for Discovering Diverse Directions in GANs
Mar 31, 2022



The discovery of interpretable directions in the latent spaces of pre-trained GAN models has recently become a popular topic. In particular, StyleGAN2 has enabled various image generation and manipulation tasks due to its rich and disentangled latent spaces. The discovery of such directions is typically done either in a supervised manner, which requires annotated data for each desired manipulation or in an unsupervised manner, which requires a manual effort to identify the directions. As a result, existing work typically finds only a handful of directions in which controllable edits can be made. In this study, we design a novel submodular framework that finds the most representative and diverse subset of directions in the latent space of StyleGAN2. Our approach takes advantage of the latent space of channel-wise style parameters, so-called style space, in which we cluster channels that perform similar manipulations into groups. Our framework promotes diversity by using the notion of clusters and can be efficiently solved with a greedy optimization scheme. We evaluate our framework with qualitative and quantitative experiments and show that our method finds more diverse and disentangled directions. Our project page can be found at http://catlab-team.github.io/fantasticstyles.
Discovering Multiple and Diverse Directions for Cognitive Image Properties
Feb 23, 2022



Recent research has shown that it is possible to find interpretable directions in the latent spaces of pre-trained GANs. These directions enable controllable generation and support a variety of semantic editing operations. While previous work has focused on discovering a single direction that performs a desired editing operation such as zoom-in, limited work has been done on the discovery of multiple and diverse directions that can achieve the desired edit. In this work, we propose a novel framework that discovers multiple and diverse directions for a given property of interest. In particular, we focus on the manipulation of cognitive properties such as Memorability, Emotional Valence and Aesthetics. We show with extensive experiments that our method successfully manipulates these properties while producing diverse outputs. Our project page and source code can be found at http://catlab-team.github.io/latentcognitive.
FairStyle: Debiasing StyleGAN2 with Style Channel Manipulations
Feb 13, 2022Recent advances in generative adversarial networks have shown that it is possible to generate high-resolution and hyperrealistic images. However, the images produced by GANs are only as fair and representative as the datasets on which they are trained. In this paper, we propose a method for directly modifying a pre-trained StyleGAN2 model that can be used to generate a balanced set of images with respect to one (e.g., eyeglasses) or more attributes (e.g., gender and eyeglasses). Our method takes advantage of the style space of the StyleGAN2 model to perform disentangled control of the target attributes to be debiased. Our method does not require training additional models and directly debiases the GAN model, paving the way for its use in various downstream applications. Our experiments show that our method successfully debiases the GAN model within a few minutes without compromising the quality of the generated images. To promote fair generative models, we share the code and debiased models at http://catlab-team.github.io/fairstyle.