 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChao Yi
Bridge the Modality and Capacity Gaps in Vision-Language Model Selection
Mar 20, 2024
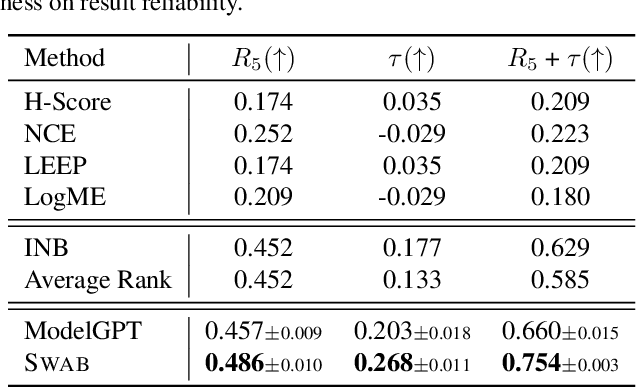
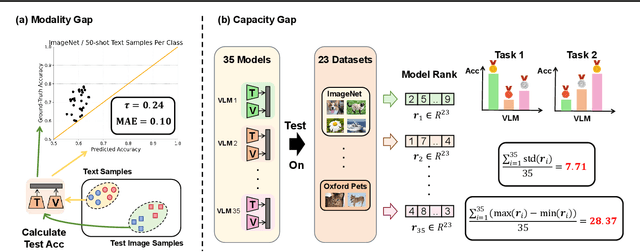

Vision Language Models (VLMs) excel in zero-shot image classification by pairing images with textual category names. The expanding variety of Pre-Trained VLMs enhances the likelihood of identifying a suitable VLM for specific tasks. Thus, a promising zero-shot image classification strategy is selecting the most appropriate Pre-Trained VLM from the VLM Zoo, relying solely on the text data of the target dataset without access to the dataset's images. In this paper, we analyze two inherent challenges in assessing the ability of a VLM in this Language-Only VLM selection: the "Modality Gap" -- the disparity in VLM's embeddings across two different modalities, making text a less reliable substitute for images; and the "Capability Gap" -- the discrepancy between the VLM's overall ranking and its ranking for target dataset, hindering direct prediction of a model's dataset-specific performance from its general performance. We propose VLM Selection With gAp Bridging (SWAB) to mitigate the negative impact of these two gaps. SWAB first adopts optimal transport to capture the relevance between open-source datasets and target dataset with a transportation matrix. It then uses this matrix to transfer useful statistics of VLMs from open-source datasets to the target dataset for bridging those two gaps and enhancing the VLM's capacity estimation for VLM selection. Experiments across various VLMs and image classification datasets validate SWAB's effectiveness.
ZhiJian: A Unifying and Rapidly Deployable Toolbox for Pre-trained Model Reuse
Aug 17, 2023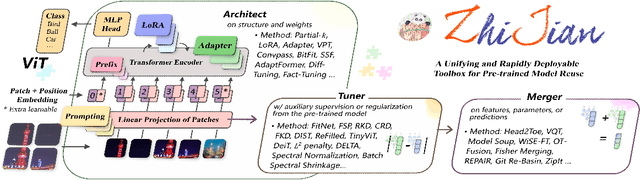
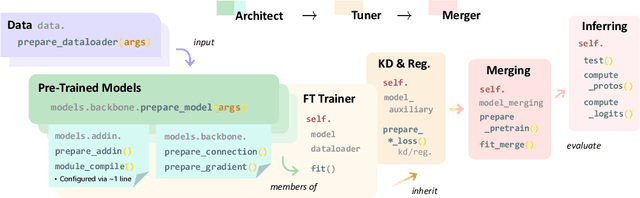
The rapid expansion of foundation pre-trained models and their fine-tuned counterparts has significantly contributed to the advancement of machine learning. Leveraging pre-trained models to extract knowledge and expedite learning in real-world tasks, known as "Model Reuse", has become crucial in various applications. Previous research focuses on reusing models within a certain aspect, including reusing model weights, structures, and hypothesis spaces. This paper introduces ZhiJian, a comprehensive and user-friendly toolbox for model reuse, utilizing the PyTorch backend. ZhiJian presents a novel paradigm that unifies diverse perspectives on model reuse, encompassing target architecture construction with PTM, tuning target model with PTM, and PTM-based inference. This empowers deep learning practitioners to explore downstream tasks and identify the complementary advantages among different methods. ZhiJian is readily accessible at https://github.com/zhangyikaii/lamda-zhijian facilitating seamless utilization of pre-trained models and streamlining the model reuse process for researchers and developers.
Finding Similar Exercises in Retrieval Manner
Mar 15, 2023


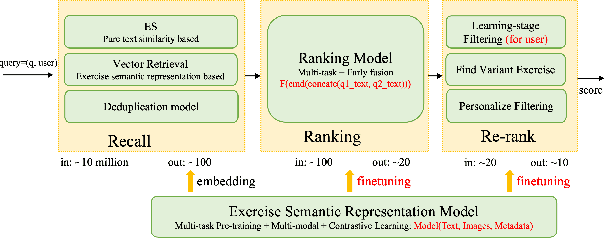
When students make a mistake in an exercise, they can consolidate it by ``similar exercises'' which have the same concepts, purposes and methods. Commonly, for a certain subject and study stage, the size of the exercise bank is in the range of millions to even tens of millions, how to find similar exercises for a given exercise becomes a crucial technical problem. Generally, we can assign a variety of explicit labels to the exercise, and then query through the labels, but the label annotation is time-consuming, laborious and costly, with limited precision and granularity, so it is not feasible. In practice, we define ``similar exercises'' as a retrieval process of finding a set of similar exercises based on recall, ranking and re-rank procedures, called the \textbf{FSE} problem (Finding similar exercises). Furthermore, comprehensive representation of the semantic information of exercises was obtained through representation learning. In addition to the reasonable architecture, we also explore what kind of tasks are more conducive to the learning of exercise semantic information from pre-training and supervised learning. It is difficult to annotate similar exercises and the annotation consistency among experts is low. Therefore this paper also provides solutions to solve the problem of low-quality annotated data. Compared with other methods, this paper has obvious advantages in both architecture rationality and algorithm precision, which now serves the daily teaching of hundreds of schools.
* 37th Conference on AAAI 2023 Artificial Intelligence for Education(AI4Edu)
Underwater Image Enhancement based on Deep Learning and Image Formation Model
Jan 07, 2021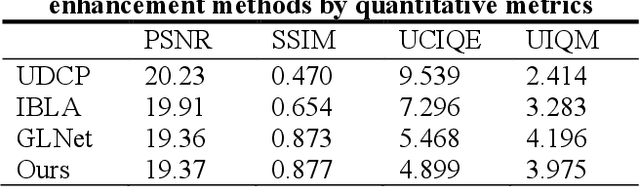



Underwater robots play an important role in oceanic geological exploration, resource exploitation, ecological research, and other fields. However, the visual perception of underwater robots is affected by various environmental factors. The main challenge now is that images captured by underwater robots are color-distorted. The hue of underwater images tends to be close to green and blue. In addition, the contrast is low and the details are fuzzy. In this paper, a new underwater image enhancement algorithm based on deep learning and image formation model is proposed. Experimental results show that the advantages of the proposed method are that it eliminates the influence of underwater environmental factors, enriches the color, enhances details, achieves higher scores in PSNR and SSIM metrics, and helps feature key-point point matching get better results. Another significant advantage is that its computation speed is much faster than other methods.
Time-Series Anomaly Detection Service at Microsoft
Jun 10, 2019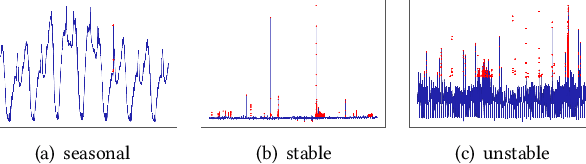
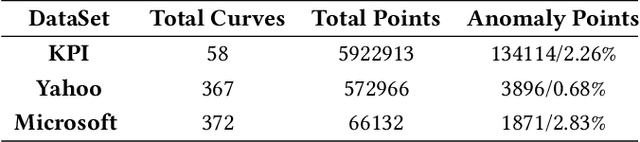
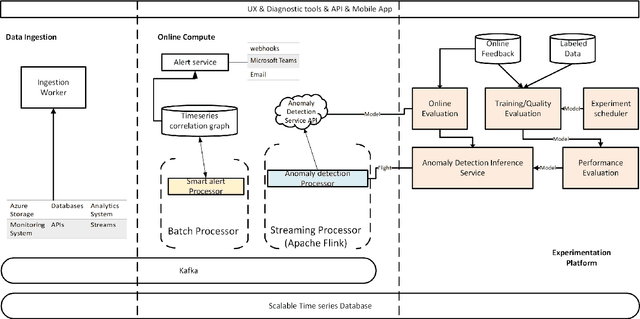

Large companies need to monitor various metrics (for example, Page Views and Revenue) of their applications and services in real time. At Microsoft, we develop a time-series anomaly detection service which helps customers to monitor the time-series continuously and alert for potential incidents on time. In this paper, we introduce the pipeline and algorithm of our anomaly detection service, which is designed to be accurate, efficient and general. The pipeline consists of three major modules, including data ingestion, experimentation platform and online compute. To tackle the problem of time-series anomaly detection, we propose a novel algorithm based on Spectral Residual (SR) and Convolutional Neural Network (CNN). Our work is the first attempt to borrow the SR model from visual saliency detection domain to time-series anomaly detection. Moreover, we innovatively combine SR and CNN together to improve the performance of SR model. Our approach achieves superior experimental results compared with state-of-the-art baselines on both public datasets and Microsoft production data.