 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCongrui Huang
NuTime: Numerically Multi-Scaled Embedding for Large-Scale Time Series Pretraining
Oct 12, 2023
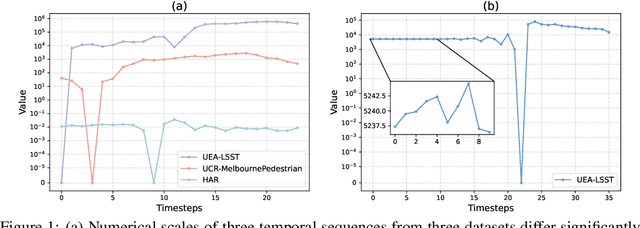
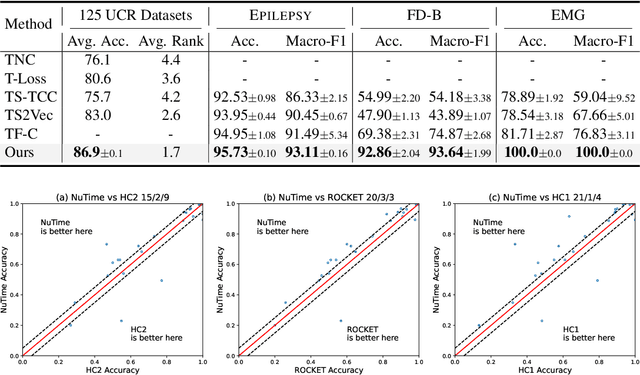
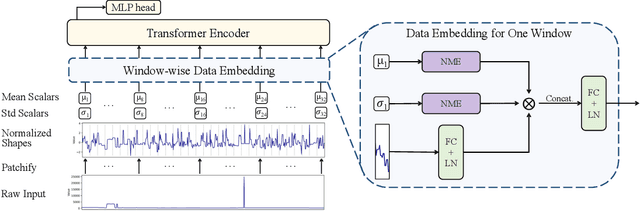
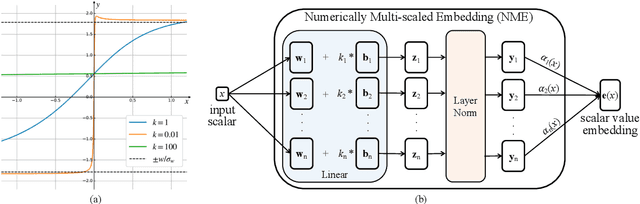
Recent research on time-series self-supervised models shows great promise in learning semantic representations. However, it has been limited to small-scale datasets, e.g., thousands of temporal sequences. In this work, we make key technical contributions that are tailored to the numerical properties of time-series data and allow the model to scale to large datasets, e.g., millions of temporal sequences. We adopt the Transformer architecture by first partitioning the input into non-overlapping windows. Each window is then characterized by its normalized shape and two scalar values denoting the mean and standard deviation within each window. To embed scalar values that may possess arbitrary numerical scales to high-dimensional vectors, we propose a numerically multi-scaled embedding module enumerating all possible scales for the scalar values. The model undergoes pretraining using the proposed numerically multi-scaled embedding with a simple contrastive objective on a large-scale dataset containing over a million sequences. We study its transfer performance on a number of univariate and multivariate classification benchmarks. Our method exhibits remarkable improvement against previous representation learning approaches and establishes the new state of the art, even compared with domain-specific non-learning-based methods.
Protecting the Future: Neonatal Seizure Detection with Spatial-Temporal Modeling
Jul 02, 2023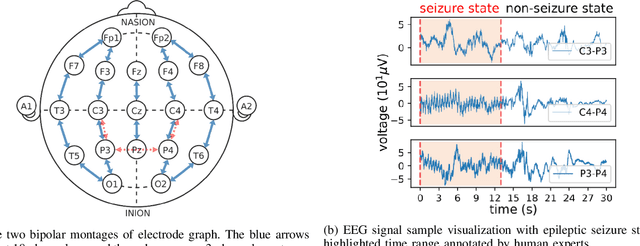
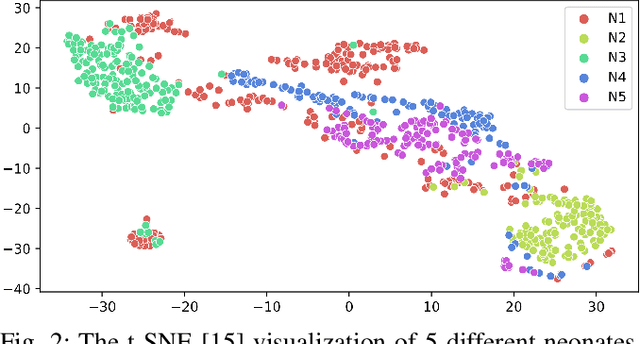
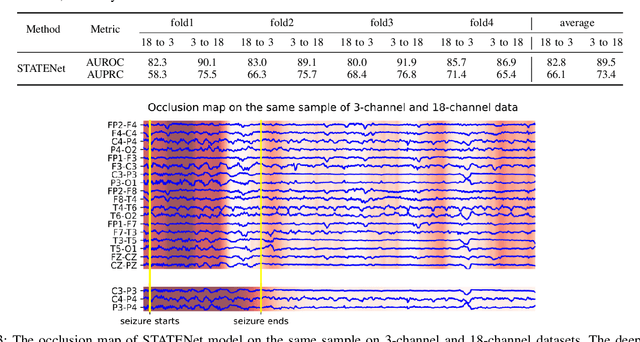
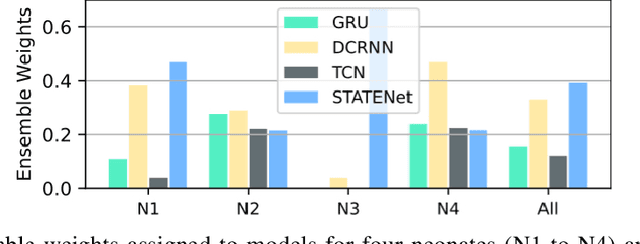
A timely detection of seizures for newborn infants with electroencephalogram (EEG) has been a common yet life-saving practice in the Neonatal Intensive Care Unit (NICU). However, it requires great human efforts for real-time monitoring, which calls for automated solutions to neonatal seizure detection. Moreover, the current automated methods focusing on adult epilepsy monitoring often fail due to (i) dynamic seizure onset location in human brains; (ii) different montages on neonates and (iii) huge distribution shift among different subjects. In this paper, we propose a deep learning framework, namely STATENet, to address the exclusive challenges with exquisite designs at the temporal, spatial and model levels. The experiments over the real-world large-scale neonatal EEG dataset illustrate that our framework achieves significantly better seizure detection performance.
Label-Efficient Interactive Time-Series Anomaly Detection
Dec 30, 2022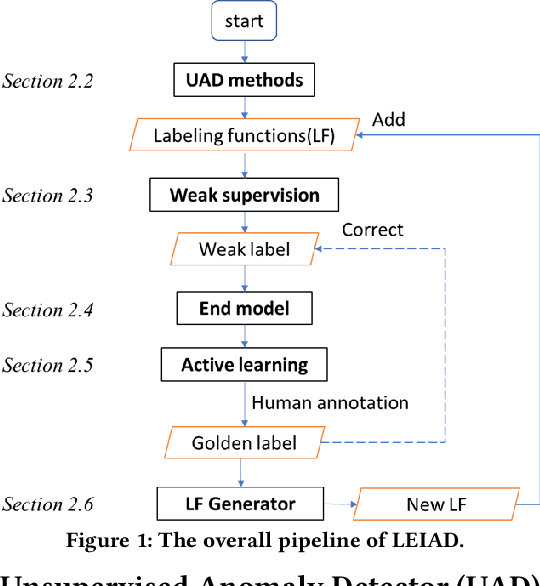
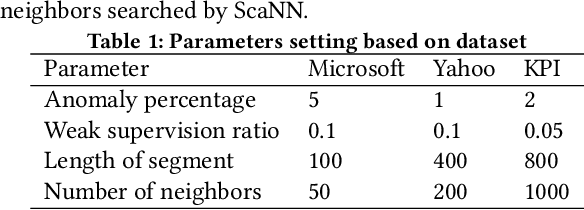
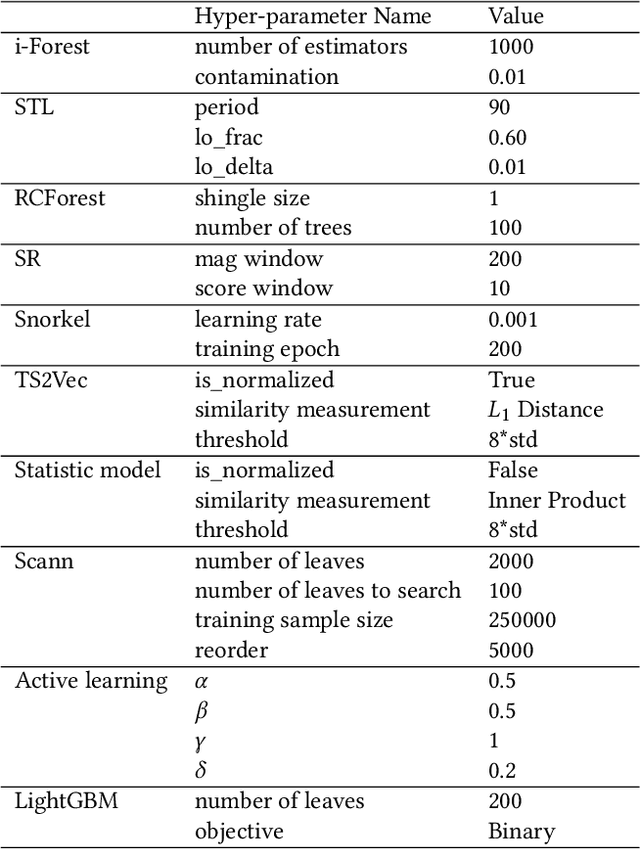
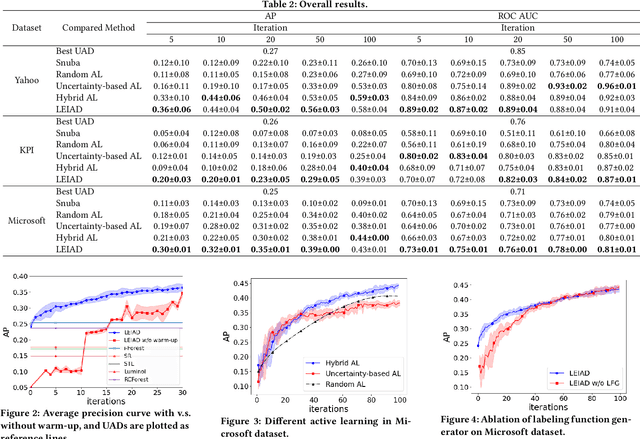
Time-series anomaly detection is an important task and has been widely applied in the industry. Since manual data annotation is expensive and inefficient, most applications adopt unsupervised anomaly detection methods, but the results are usually sub-optimal and unsatisfactory to end customers. Weak supervision is a promising paradigm for obtaining considerable labels in a low-cost way, which enables the customers to label data by writing heuristic rules rather than annotating each instance individually. However, in the time-series domain, it is hard for people to write reasonable labeling functions as the time-series data is numerically continuous and difficult to be understood. In this paper, we propose a Label-Efficient Interactive Time-Series Anomaly Detection (LEIAD) system, which enables a user to improve the results of unsupervised anomaly detection by performing only a small amount of interactions with the system. To achieve this goal, the system integrates weak supervision and active learning collaboratively while generating labeling functions automatically using only a few labeled data. All of these techniques are complementary and can promote each other in a reinforced manner. We conduct experiments on three time-series anomaly detection datasets, demonstrating that the proposed system is superior to existing solutions in both weak supervision and active learning areas. Also, the system has been tested in a real scenario in industry to show its practicality.
Learning Timestamp-Level Representations for Time Series with Hierarchical Contrastive Loss
Jun 19, 2021
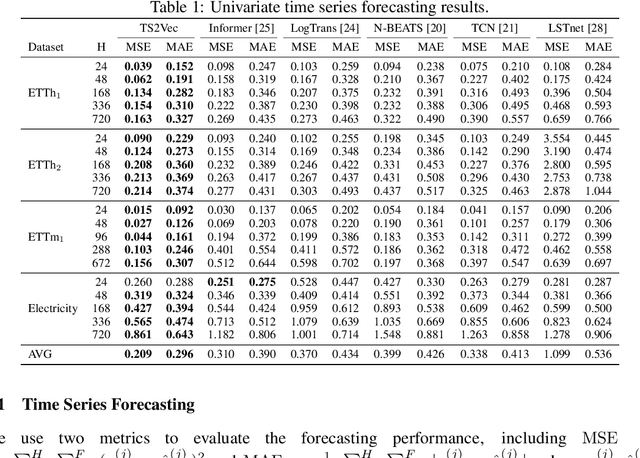
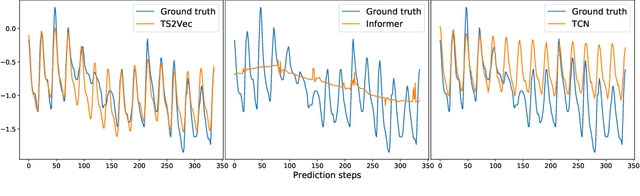
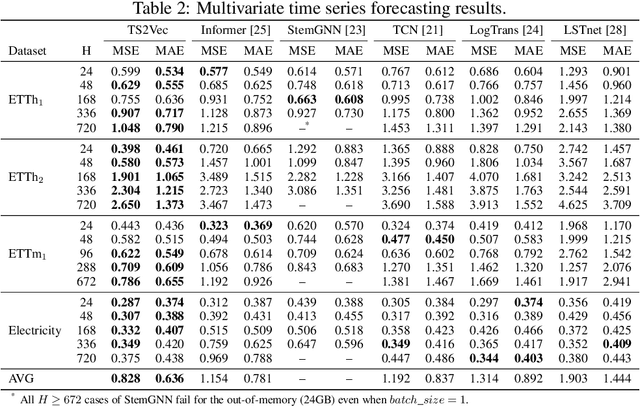
This paper presents TS2Vec, a universal framework for learning timestamp-level representations of time series. Unlike existing methods, TS2Vec performs timestamp-wise discrimination, which learns a contextual representation vector directly for each timestamp. We find that the learned representations have superior predictive ability. A linear regression trained on top of the learned representations outperforms previous SOTAs for supervised time series forecasting. Also, the instance-level representations can be simply obtained by applying a max pooling layer on top of learned representations of all timestamps. We conduct extensive experiments on time series classification tasks to evaluate the quality of instance-level representations. As a result, TS2Vec achieves significant improvement compared with existing SOTAs of unsupervised time series representation on 125 UCR datasets and 29 UEA datasets. The source code is publicly available at https://github.com/yuezhihan/ts2vec.
Multivariate Time-series Anomaly Detection via Graph Attention Network
Sep 04, 2020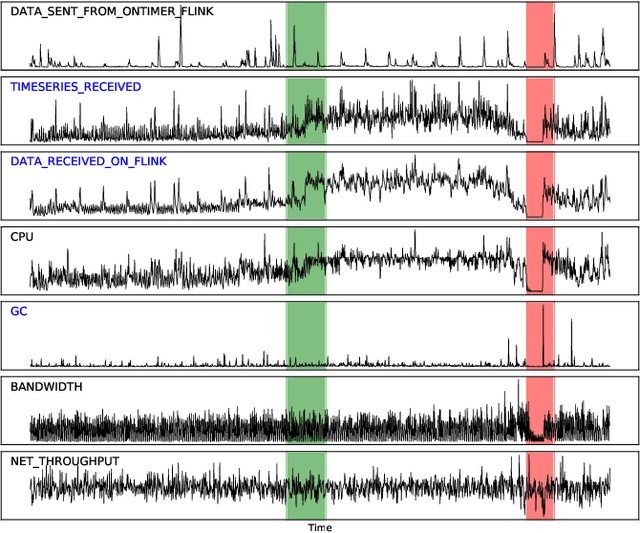
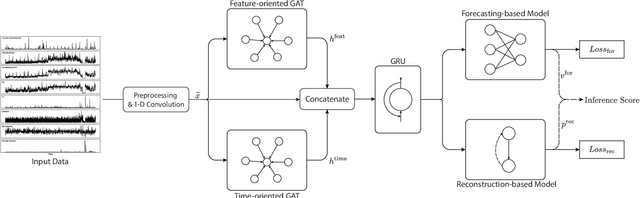
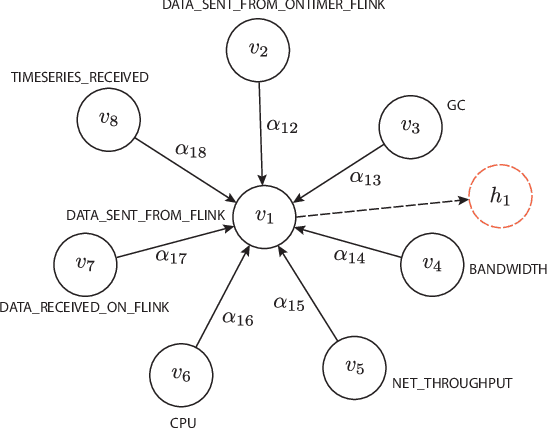
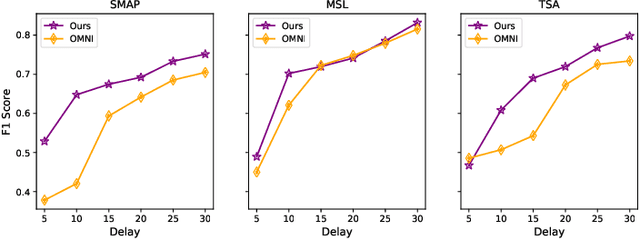
Anomaly detection on multivariate time-series is of great importance in both data mining research and industrial applications. Recent approaches have achieved significant progress in this topic, but there is remaining limitations. One major limitation is that they do not capture the relationships between different time-series explicitly, resulting in inevitable false alarms. In this paper, we propose a novel self-supervised framework for multivariate time-series anomaly detection to address this issue. Our framework considers each univariate time-series as an individual feature and includes two graph attention layers in parallel to learn the complex dependencies of multivariate time-series in both temporal and feature dimensions. In addition, our approach jointly optimizes a forecasting-based model and are construction-based model, obtaining better time-series representations through a combination of single-timestamp prediction and reconstruction of the entire time-series. We demonstrate the efficacy of our model through extensive experiments. The proposed method outperforms other state-of-the-art models on three real-world datasets. Further analysis shows that our method has good interpretability and is useful for anomaly diagnosis.
Automated Model Selection for Time-Series Anomaly Detection
Aug 25, 2020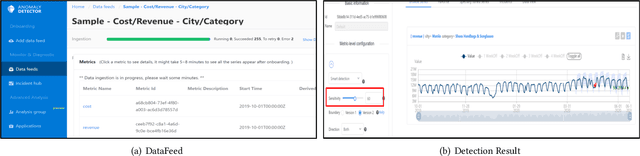
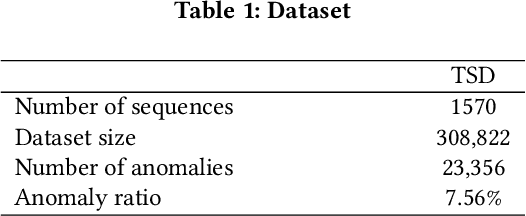
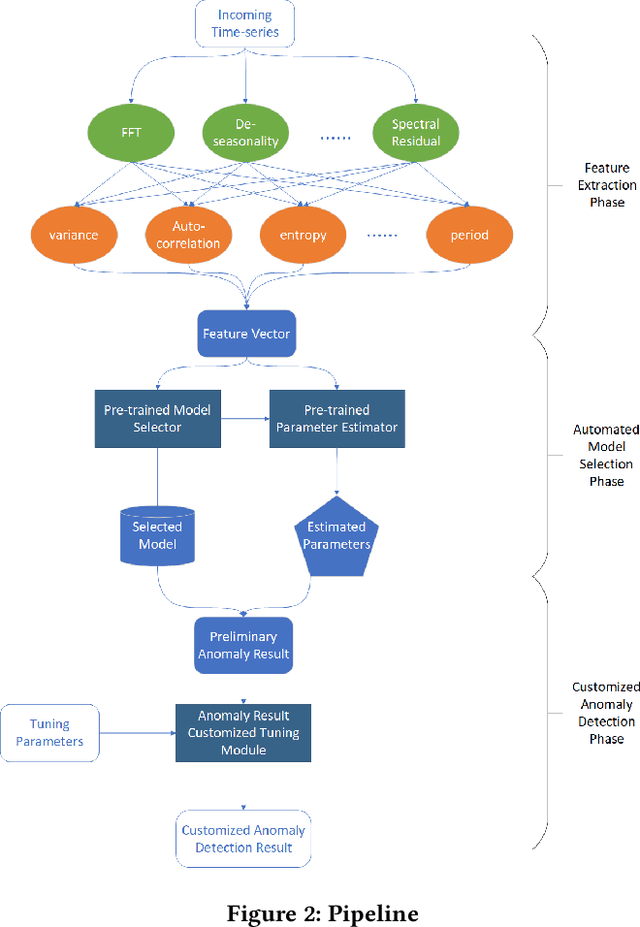
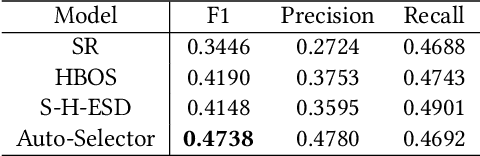
Time-series anomaly detection is a popular topic in both academia and industrial fields. Many companies need to monitor thousands of temporal signals for their applications and services and require instant feedback and alerts for potential incidents in time. The task is challenging because of the complex characteristics of time-series, which are messy, stochastic, and often without proper labels. This prohibits training supervised models because of lack of labels and a single model hardly fits different time series. In this paper, we propose a solution to address these issues. We present an automated model selection framework to automatically find the most suitable detection model with proper parameters for the incoming data. The model selection layer is extensible as it can be updated without too much effort when a new detector is available to the service. Finally, we incorporate a customized tuning algorithm to flexibly filter anomalies to meet customers' criteria. Experiments on real-world datasets show the effectiveness of our solution.
Time-Series Anomaly Detection Service at Microsoft
Jun 10, 2019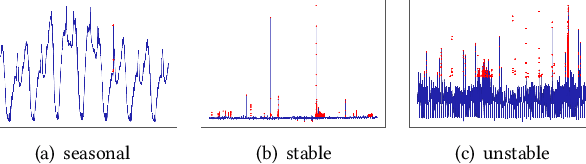
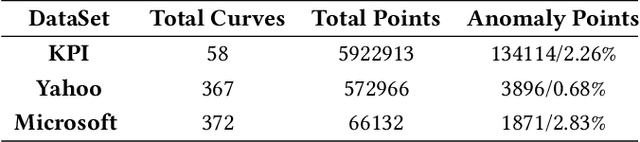
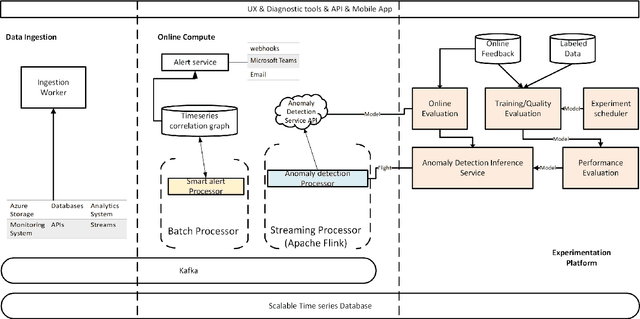

Large companies need to monitor various metrics (for example, Page Views and Revenue) of their applications and services in real time. At Microsoft, we develop a time-series anomaly detection service which helps customers to monitor the time-series continuously and alert for potential incidents on time. In this paper, we introduce the pipeline and algorithm of our anomaly detection service, which is designed to be accurate, efficient and general. The pipeline consists of three major modules, including data ingestion, experimentation platform and online compute. To tackle the problem of time-series anomaly detection, we propose a novel algorithm based on Spectral Residual (SR) and Convolutional Neural Network (CNN). Our work is the first attempt to borrow the SR model from visual saliency detection domain to time-series anomaly detection. Moreover, we innovatively combine SR and CNN together to improve the performance of SR model. Our approach achieves superior experimental results compared with state-of-the-art baselines on both public datasets and Microsoft production data.