 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChao Zhao
Returning to the Start: Generating Narratives with Related Endpoints
Mar 31, 2024
Human writers often bookend their writing with ending sentences that relate back to the beginning sentences in order to compose a satisfying narrative that "closes the loop." Motivated by this observation, we propose RENarGen, a controllable story-generation paradigm that generates narratives by ensuring the first and last sentences are related and then infilling the middle sentences. Our contributions include an initial exploration of how various methods of bookending from Narratology affect language modeling for stories. Automatic and human evaluations indicate RENarGen produces better stories with more narrative closure than current autoregressive models.
SPECTRUM: Speaker-Enhanced Pre-Training for Long Dialogue Summarization
Jan 31, 2024Multi-turn dialogues are characterized by their extended length and the presence of turn-taking conversations. Traditional language models often overlook the distinct features of these dialogues by treating them as regular text. In this paper, we propose a speaker-enhanced pre-training method for long dialogue summarization, which leverages the inherent structure of multiple-turn dialogues. To support our study, we curate a diverse dataset that includes transcripts from real-world scenarios, movie or TV show transcripts, and dialogues generated by a Large Language Model. We then perform a pre-training, which encompasses the detection of speaker changes, and masked utterance generation. Experimental results of fine-tuned models demonstrate that our model achieves state-of-the-art performance on downstream benchmarks with long context, surpassing baseline models and highlighting the effectiveness of our approach. Our findings highlight the importance of curating pre-training datasets that exhibit diversity and variations in length distribution to ensure effective alignment with downstream datasets.
Universal Deoxidation of Semiconductor Substrates Assisted by Machine-Learning and Real-Time-Feedback-Control
Dec 04, 2023Thin film deposition is an essential step in the semiconductor process. During preparation or loading, the substrate is exposed to the air unavoidably, which has motivated studies of the process control to remove the surface oxide before thin film deposition. Optimizing the deoxidation process in molecular beam epitaxy (MBE) for a random substrate is a multidimensional challenge and sometimes controversial. Due to variations in semiconductor materials and growth processes, the determination of substrate deoxidation temperature is highly dependent on the grower's expertise; the same substrate may yield inconsistent results when evaluated by different growers. Here, we employ a machine learning (ML) hybrid convolution and vision transformer (CNN-ViT) model. This model utilizes reflection high-energy electron diffraction (RHEED) video as input to determine the deoxidation status of the substrate as output, enabling automated substrate deoxidation under a controlled architecture. This also extends to the successful application of deoxidation processes on other substrates. Furthermore, we showcase the potential of models trained on data from a single MBE equipment to achieve high-accuracy deployment on other equipment. In contrast to traditional methods, our approach holds exceptional practical value. It standardizes deoxidation temperatures across various equipment and substrate materials, advancing the standardization research process in semiconductor preparation, a significant milestone in thin film growth technology. The concepts and methods demonstrated in this work are anticipated to revolutionize semiconductor manufacturing in optoelectronics and microelectronics industries by applying them to diverse material growth processes.
Machine-Learning-Assisted and Real-Time-Feedback-Controlled Growth of InAs/GaAs Quantum Dots
Jul 07, 2023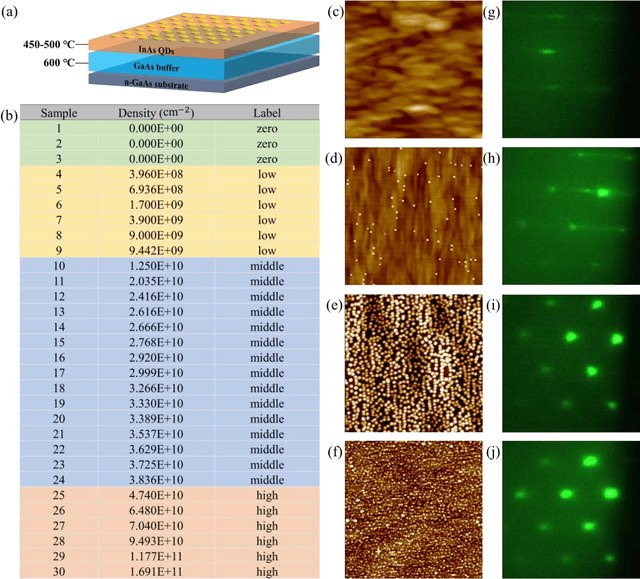
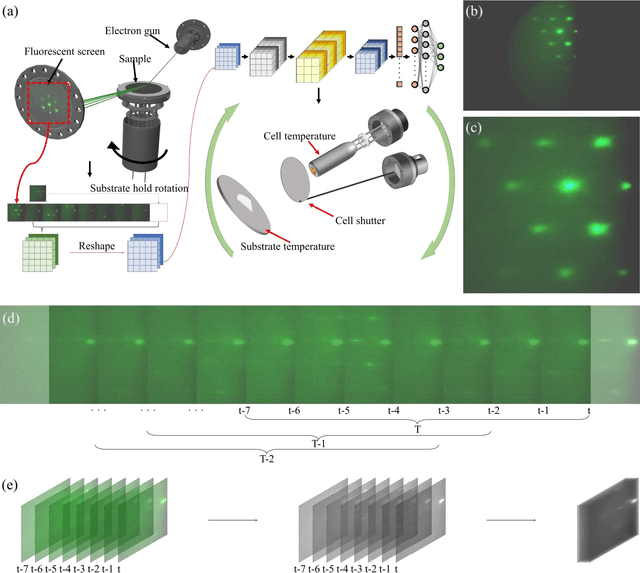
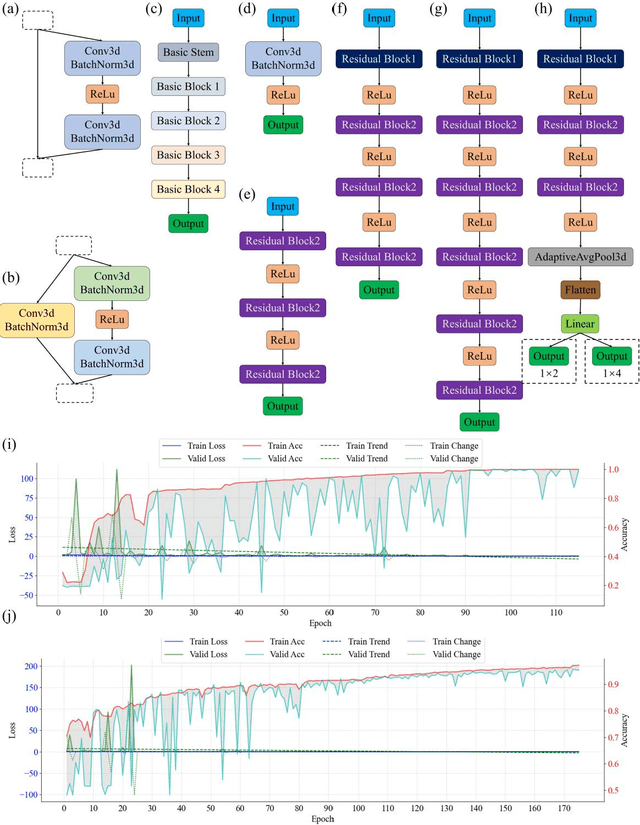
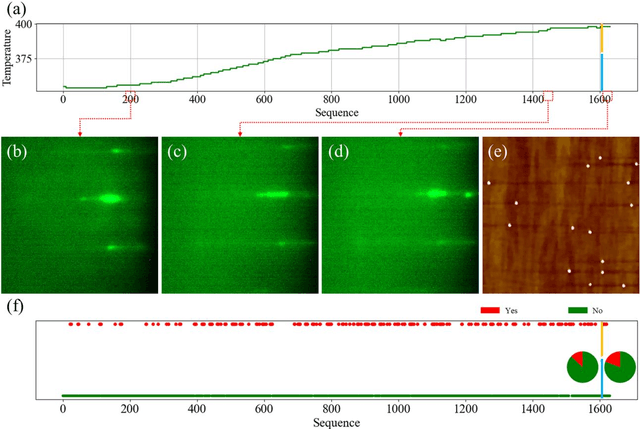
Self-assembled InAs/GaAs quantum dots (QDs) have properties highly valuable for developing various optoelectronic devices such as QD lasers and single photon sources. The applications strongly rely on the density and quality of these dots, which has motivated studies of the growth process control to realize high-quality epi-wafers and devices. Establishing the process parameters in molecular beam epitaxy (MBE) for a specific density of QDs is a multidimensional optimization challenge, usually addressed through time-consuming and iterative trial-and-error. Here, we report a real-time feedback control method to realize the growth of QDs with arbitrary and precise density, which is fully automated and intelligent. We developed a machine learning (ML) model named 3D ResNet, specially designed for training RHEED videos instead of static images and providing real-time feedback on surface morphologies for process control. As a result, we demonstrated that ML from previous growth could predict the post-growth density of QDs, by successfully tuning the QD densities in near-real time from 1.5E10 cm-2 down to 3.8E8 cm-2 or up to 1.4E11 cm-2. Compared to traditional methods, our approach, with in-situ tuning capabilities and excellent reliability, can dramatically expedite the material optimization process and improve the reproducibility of MBE growth, constituting significant progress for thin film growth techniques. The concepts and methodologies proved feasible in this work are promising to be applied to a variety of material growth processes, which will revolutionize semiconductor manufacturing for microelectronic and optoelectronic industries.
"What do others think?": Task-Oriented Conversational Modeling with Subjective Knowledge
May 20, 2023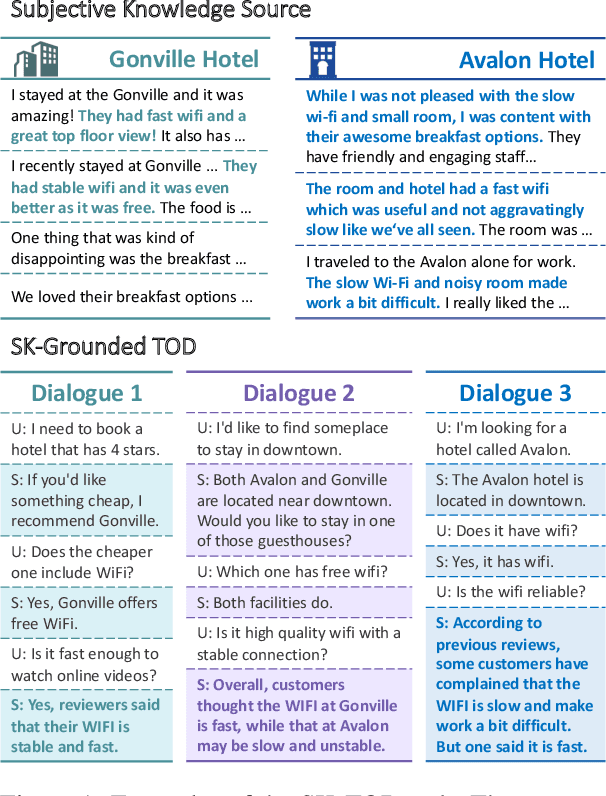
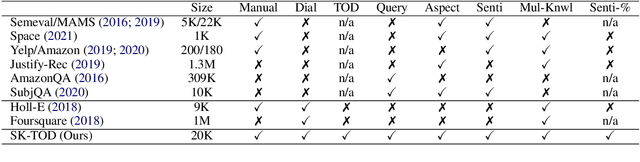
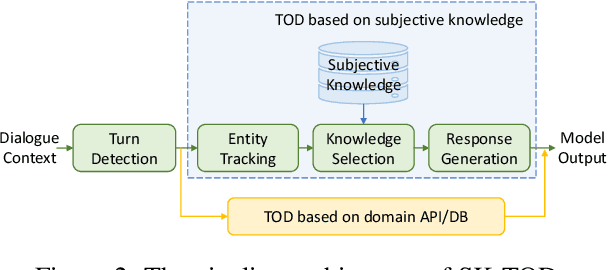
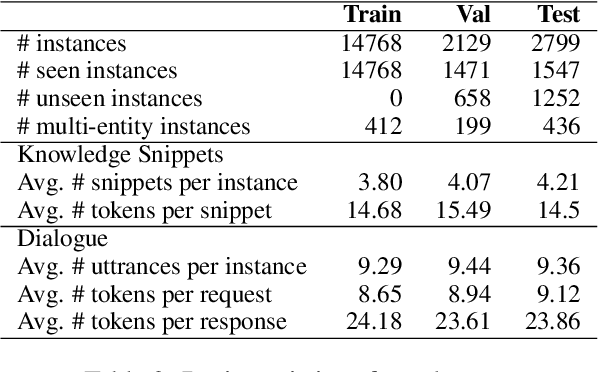
Task-oriented Dialogue (TOD) Systems aim to build dialogue systems that assist users in accomplishing specific goals, such as booking a hotel or a restaurant. Traditional TODs rely on domain-specific APIs/DBs or external factual knowledge to generate responses, which cannot accommodate subjective user requests (e.g., "Is the WIFI reliable?" or "Does the restaurant have a good atmosphere?"). To address this issue, we propose a novel task of subjective-knowledge-based TOD (SK-TOD). We also propose the first corresponding dataset, which contains subjective knowledge-seeking dialogue contexts and manually annotated responses grounded in subjective knowledge sources. When evaluated with existing TOD approaches, we find that this task poses new challenges such as aggregating diverse opinions from multiple knowledge snippets. We hope this task and dataset can promote further research on TOD and subjective content understanding. The code and the dataset are available at https://github.com/alexa/dstc11-track5.
Learn to Grasp via Intention Discovery and its Application to Challenging Clutter
Apr 05, 2023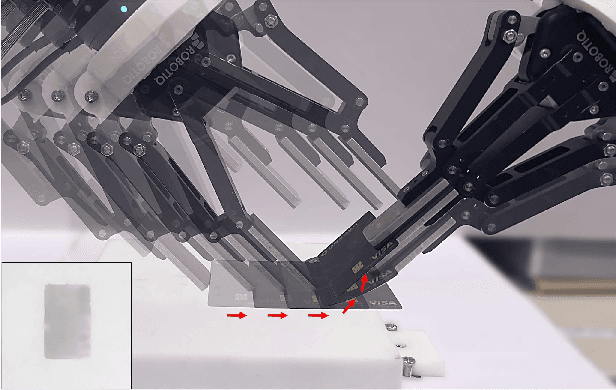
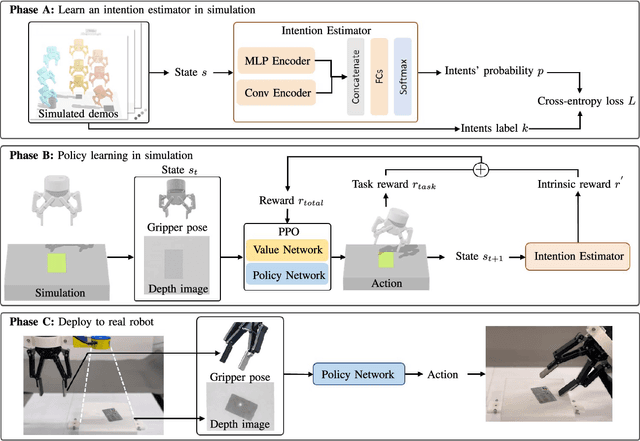
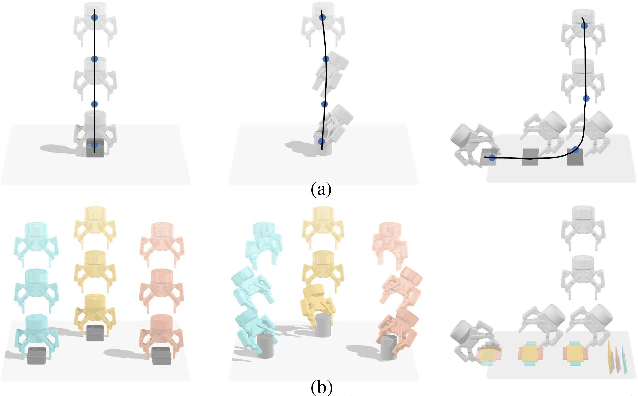
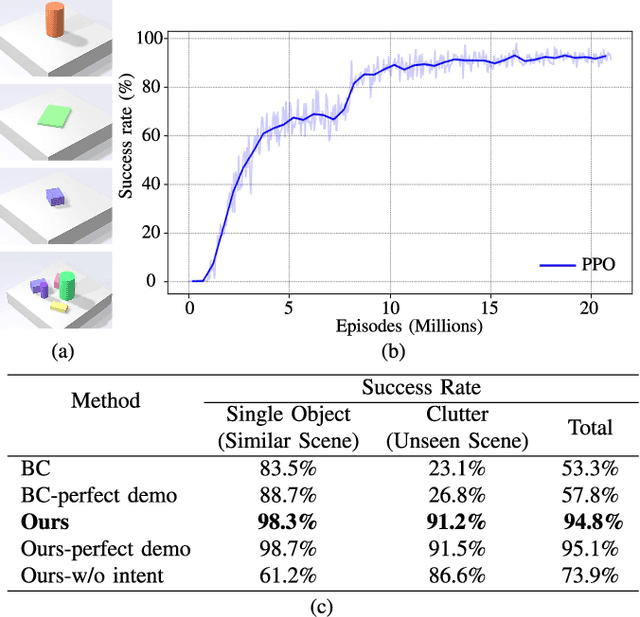
Humans excel in grasping objects through diverse and robust policies, many of which are so probabilistically rare that exploration-based learning methods hardly observe and learn. Inspired by the human learning process, we propose a method to extract and exploit latent intents from demonstrations, and then learn diverse and robust grasping policies through self-exploration. The resulting policy can grasp challenging objects in various environments with an off-the-shelf parallel gripper. The key component is a learned intention estimator, which maps gripper pose and visual sensory to a set of sub-intents covering important phases of the grasping movement. Sub-intents can be used to build an intrinsic reward to guide policy learning. The learned policy demonstrates remarkable zero-shot generalization from simulation to the real world while retaining its robustness against states that have never been encountered during training, novel objects such as protractors and user manuals, and environments such as the cluttered conveyor.
* Accepted to IEEE Robotics and Automation Letters (RA-L)
Flipbot: Learning Continuous Paper Flipping via Coarse-to-Fine Exteroceptive-Proprioceptive Exploration
Apr 05, 2023
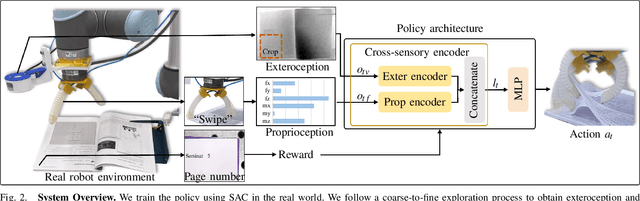
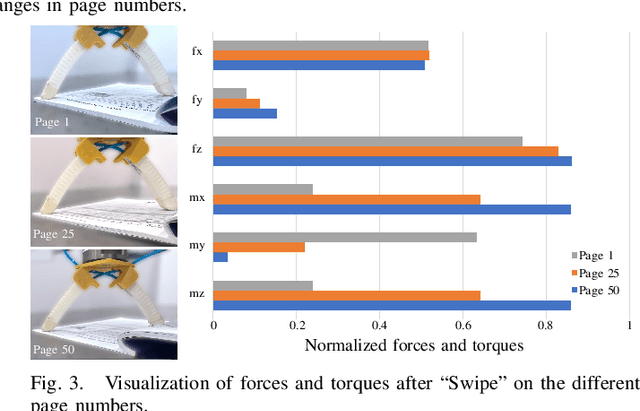

This paper tackles the task of singulating and grasping paper-like deformable objects. We refer to such tasks as paper-flipping. In contrast to manipulating deformable objects that lack compression strength (such as shirts and ropes), minor variations in the physical properties of the paper-like deformable objects significantly impact the results, making manipulation highly challenging. Here, we present Flipbot, a novel solution for flipping paper-like deformable objects. Flipbot allows the robot to capture object physical properties by integrating exteroceptive and proprioceptive perceptions that are indispensable for manipulating deformable objects. Furthermore, by incorporating a proposed coarse-to-fine exploration process, the system is capable of learning the optimal control parameters for effective paper-flipping through proprioceptive and exteroceptive inputs. We deploy our method on a real-world robot with a soft gripper and learn in a self-supervised manner. The resulting policy demonstrates the effectiveness of Flipbot on paper-flipping tasks with various settings beyond the reach of prior studies, including but not limited to flipping pages throughout a book and emptying paper sheets in a box.
ERRA: An Embodied Representation and Reasoning Architecture for Long-horizon Language-conditioned Manipulation Tasks
Apr 05, 2023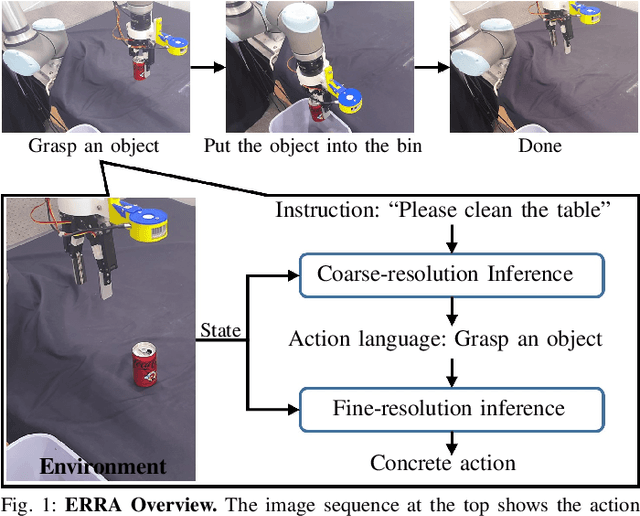
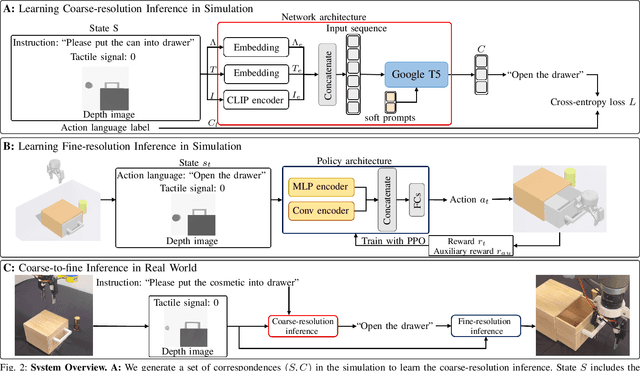
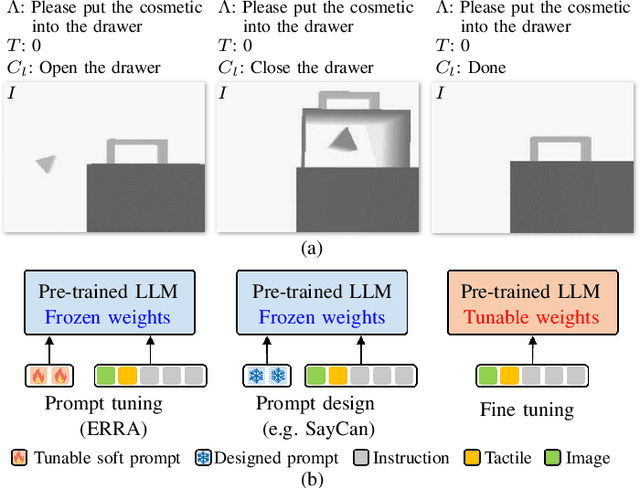

This letter introduces ERRA, an embodied learning architecture that enables robots to jointly obtain three fundamental capabilities (reasoning, planning, and interaction) for solving long-horizon language-conditioned manipulation tasks. ERRA is based on tightly-coupled probabilistic inferences at two granularity levels. Coarse-resolution inference is formulated as sequence generation through a large language model, which infers action language from natural language instruction and environment state. The robot then zooms to the fine-resolution inference part to perform the concrete action corresponding to the action language. Fine-resolution inference is constructed as a Markov decision process, which takes action language and environmental sensing as observations and outputs the action. The results of action execution in environments provide feedback for subsequent coarse-resolution reasoning. Such coarse-to-fine inference allows the robot to decompose and achieve long-horizon tasks interactively. In extensive experiments, we show that ERRA can complete various long-horizon manipulation tasks specified by abstract language instructions. We also demonstrate successful generalization to the novel but similar natural language instructions.
NarraSum: A Large-Scale Dataset for Abstractive Narrative Summarization
Dec 02, 2022
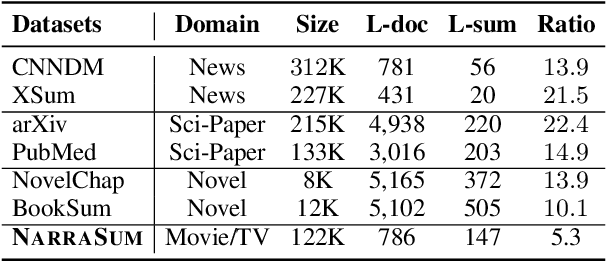


Narrative summarization aims to produce a distilled version of a narrative to describe its most salient events and characters. Summarizing a narrative is challenging as it requires an understanding of event causality and character behaviors. To encourage research in this direction, we propose NarraSum, a large-scale narrative summarization dataset. It contains 122K narrative documents, which are collected from plot descriptions of movies and TV episodes with diverse genres, and their corresponding abstractive summaries. Experiments show that there is a large performance gap between humans and the state-of-the-art summarization models on NarraSum. We hope that this dataset will promote future research in summarization, as well as broader studies of natural language understanding and generation. The dataset is available at https://github.com/zhaochaocs/narrasum.
Revisiting Generative Commonsense Reasoning: A Pre-Ordering Approach
May 26, 2022

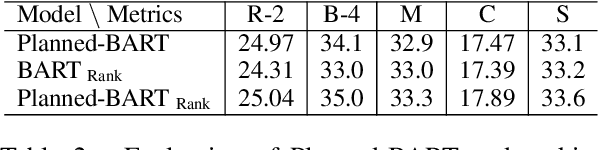
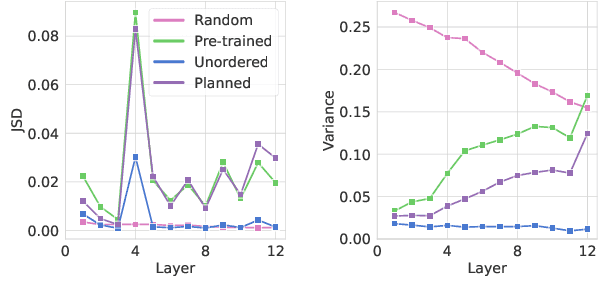
Pre-trained models (PTMs) have lead to great improvements in natural language generation (NLG). However, it is still unclear how much commonsense knowledge they possess. With the goal of evaluating commonsense knowledge of NLG models, recent work has proposed the problem of generative commonsense reasoning, e.g., to compose a logical sentence given a set of unordered concepts. Existing approaches to this problem hypothesize that PTMs lack sufficient parametric knowledge for this task, which can be overcome by introducing external knowledge or task-specific pre-training objectives. Different from this trend, we argue that PTM's inherent ability for generative commonsense reasoning is underestimated due to the order-agnostic property of its input. In particular, we hypothesize that the order of the input concepts can affect the PTM's ability to utilize its commonsense knowledge. To this end, we propose a pre-ordering approach to elaborately manipulate the order of the given concepts before generation. Experiments show that our approach can outperform the more sophisticated models that have access to a lot of external data and resources.