 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiaoyang Wang
FakeBench: Uncover the Achilles' Heels of Fake Images with Large Multimodal Models
Apr 20, 2024
Recently, fake images generated by artificial intelligence (AI) models have become indistinguishable from the real, exerting new challenges for fake image detection models. To this extent, simple binary judgments of real or fake seem less convincing and credible due to the absence of human-understandable explanations. Fortunately, Large Multimodal Models (LMMs) bring possibilities to materialize the judgment process while their performance remains undetermined. Therefore, we propose FakeBench, the first-of-a-kind benchmark towards transparent defake, consisting of fake images with human language descriptions on forgery signs. FakeBench gropes for two open questions of LMMs: (1) can LMMs distinguish fake images generated by AI, and (2) how do LMMs distinguish fake images? In specific, we construct the FakeClass dataset with 6k diverse-sourced fake and real images, each equipped with a Question&Answer pair concerning the authenticity of images, which are utilized to benchmark the detection ability. To examine the reasoning and interpretation abilities of LMMs, we present the FakeClue dataset, consisting of 15k pieces of descriptions on the telltale clues revealing the falsification of fake images. Besides, we construct the FakeQA to measure the LMMs' open-question answering ability on fine-grained authenticity-relevant aspects. Our experimental results discover that current LMMs possess moderate identification ability, preliminary interpretation and reasoning ability, and passable open-question answering ability for image defake. The FakeBench will be made publicly available soon.
Explainable AI for Fair Sepsis Mortality Predictive Model
Apr 19, 2024Artificial intelligence supports healthcare professionals with predictive modeling, greatly transforming clinical decision-making. This study addresses the crucial need for fairness and explainability in AI applications within healthcare to ensure equitable outcomes across diverse patient demographics. By focusing on the predictive modeling of sepsis-related mortality, we propose a method that learns a performance-optimized predictive model and then employs the transfer learning process to produce a model with better fairness. Our method also introduces a novel permutation-based feature importance algorithm aiming at elucidating the contribution of each feature in enhancing fairness on predictions. Unlike existing explainability methods concentrating on explaining feature contribution to predictive performance, our proposed method uniquely bridges the gap in understanding how each feature contributes to fairness. This advancement is pivotal, given sepsis's significant mortality rate and its role in one-third of hospital deaths. Our method not only aids in identifying and mitigating biases within the predictive model but also fosters trust among healthcare stakeholders by improving the transparency and fairness of model predictions, thereby contributing to more equitable and trustworthy healthcare delivery.
Hypergraph Self-supervised Learning with Sampling-efficient Signals
Apr 18, 2024Self-supervised learning (SSL) provides a promising alternative for representation learning on hypergraphs without costly labels. However, existing hypergraph SSL models are mostly based on contrastive methods with the instance-level discrimination strategy, suffering from two significant limitations: (1) They select negative samples arbitrarily, which is unreliable in deciding similar and dissimilar pairs, causing training bias. (2) They often require a large number of negative samples, resulting in expensive computational costs. To address the above issues, we propose SE-HSSL, a hypergraph SSL framework with three sampling-efficient self-supervised signals. Specifically, we introduce two sampling-free objectives leveraging the canonical correlation analysis as the node-level and group-level self-supervised signals. Additionally, we develop a novel hierarchical membership-level contrast objective motivated by the cascading overlap relationship in hypergraphs, which can further reduce membership sampling bias and improve the efficiency of sample utilization. Through comprehensive experiments on 7 real-world hypergraphs, we demonstrate the superiority of our approach over the state-of-the-art method in terms of both effectiveness and efficiency.
An ExplainableFair Framework for Prediction of Substance Use Disorder Treatment Completion
Apr 04, 2024Fairness of machine learning models in healthcare has drawn increasing attention from clinicians, researchers, and even at the highest level of government. On the other hand, the importance of developing and deploying interpretable or explainable models has been demonstrated, and is essential to increasing the trustworthiness and likelihood of adoption of these models. The objective of this study was to develop and implement a framework for addressing both these issues - fairness and explainability. We propose an explainable fairness framework, first developing a model with optimized performance, and then using an in-processing approach to mitigate model biases relative to the sensitive attributes of race and sex. We then explore and visualize explanations of the model changes that lead to the fairness enhancement process through exploring the changes in importance of features. Our resulting-fairness enhanced models retain high sensitivity with improved fairness and explanations of the fairness-enhancement that may provide helpful insights for healthcare providers to guide clinical decision-making and resource allocation.
Polarity Calibration for Opinion Summarization
Apr 02, 2024Opinion summarization is automatically generating summaries from a variety of subjective information, such as product reviews or political opinions. The challenge of opinions summarization lies in presenting divergent or even conflicting opinions. We conduct an analysis of previous summarization models, which reveals their inclination to amplify the polarity bias, emphasizing the majority opinions while ignoring the minority opinions. To address this issue and make the summarizer express both sides of opinions, we introduce the concept of polarity calibration, which aims to align the polarity of output summary with that of input text. Specifically, we develop a reinforcement training approach for polarity calibration. This approach feeds the polarity distance between output summary and input text as reward into the summarizer, and also balance polarity calibration with content preservation and language naturality. We evaluate our Polarity Calibration model (PoCa) on two types of opinions summarization tasks: summarizing product reviews and political opinions articles. Automatic and human evaluation demonstrate that our approach can mitigate the polarity mismatch between output summary and input text, as well as maintain the content semantic and language quality.
Towards the Uncharted: Density-Descending Feature Perturbation for Semi-supervised Semantic Segmentation
Mar 14, 2024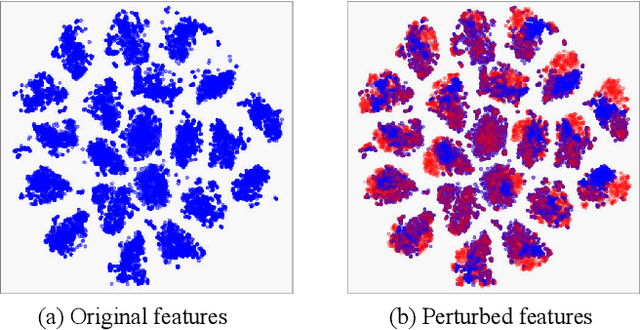
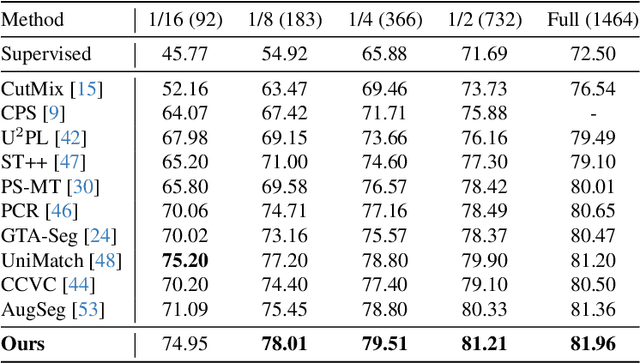
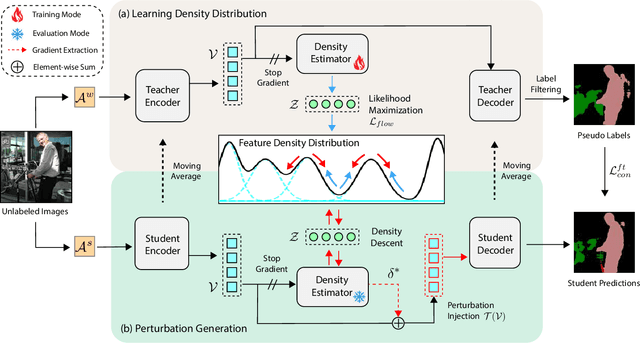
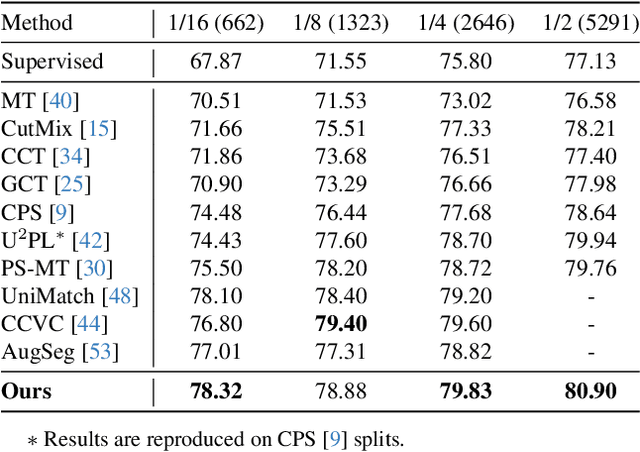
Semi-supervised semantic segmentation allows model to mine effective supervision from unlabeled data to complement label-guided training. Recent research has primarily focused on consistency regularization techniques, exploring perturbation-invariant training at both the image and feature levels. In this work, we proposed a novel feature-level consistency learning framework named Density-Descending Feature Perturbation (DDFP). Inspired by the low-density separation assumption in semi-supervised learning, our key insight is that feature density can shed a light on the most promising direction for the segmentation classifier to explore, which is the regions with lower density. We propose to shift features with confident predictions towards lower-density regions by perturbation injection. The perturbed features are then supervised by the predictions on the original features, thereby compelling the classifier to explore less dense regions to effectively regularize the decision boundary. Central to our method is the estimation of feature density. To this end, we introduce a lightweight density estimator based on normalizing flow, allowing for efficient capture of the feature density distribution in an online manner. By extracting gradients from the density estimator, we can determine the direction towards less dense regions for each feature. The proposed DDFP outperforms other designs on feature-level perturbations and shows state of the art performances on both Pascal VOC and Cityscapes dataset under various partition protocols. The project is available at https://github.com/Gavinwxy/DDFP.
Continual Segmentation with Disentangled Objectness Learning and Class Recognition
Mar 14, 2024Most continual segmentation methods tackle the problem as a per-pixel classification task. However, such a paradigm is very challenging, and we find query-based segmenters with built-in objectness have inherent advantages compared with per-pixel ones, as objectness has strong transfer ability and forgetting resistance. Based on these findings, we propose CoMasTRe by disentangling continual segmentation into two stages: forgetting-resistant continual objectness learning and well-researched continual classification. CoMasTRe uses a two-stage segmenter learning class-agnostic mask proposals at the first stage and leaving recognition to the second stage. During continual learning, a simple but effective distillation is adopted to strengthen objectness. To further mitigate the forgetting of old classes, we design a multi-label class distillation strategy suited for segmentation. We assess the effectiveness of CoMasTRe on PASCAL VOC and ADE20K. Extensive experiments show that our method outperforms per-pixel and query-based methods on both datasets. Code will be available at https://github.com/jordangong/CoMasTRe.
Can Large Language Models do Analytical Reasoning?
Mar 06, 2024

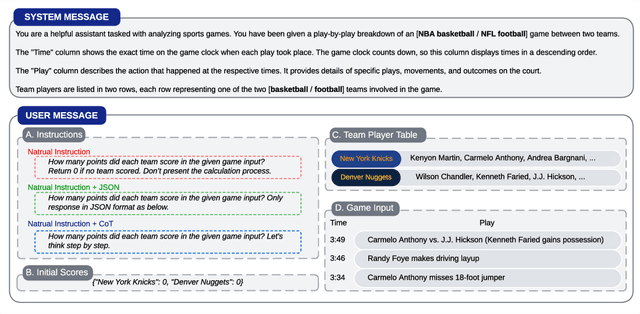
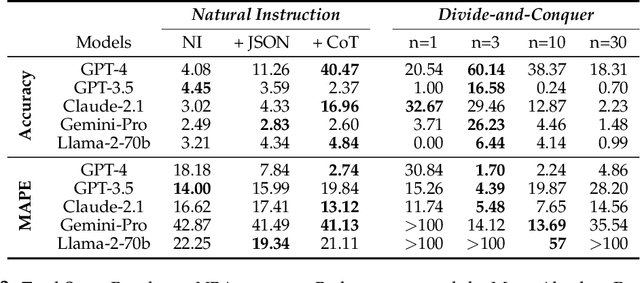
This paper explores the cutting-edge Large Language Model with analytical reasoning on sports. Our analytical reasoning embodies the tasks of letting large language models count how many points each team scores in a quarter in the NBA and NFL games. Our major discoveries are in two folds. Firstly, we find among all the models we employed, GPT-4 stands out in effectiveness, followed by Claude-2.1, with GPT-3.5, Gemini-Pro, and Llama-2-70b lagging behind. Specifically, we compare three different prompting techniques and a divide-and-conquer approach, we find that the latter was the most effective. Our divide-and-conquer approach breaks down play-by-play data into smaller, more manageable segments, solves each piece individually, and then aggregates them together. Besides the divide-and-conquer approach, we also explore the Chain of Thought (CoT) strategy, which markedly improves outcomes for certain models, notably GPT-4 and Claude-2.1, with their accuracy rates increasing significantly. However, the CoT strategy has negligible or even detrimental effects on the performance of other models like GPT-3.5 and Gemini-Pro. Secondly, to our surprise, we observe that most models, including GPT-4, struggle to accurately count the total scores for NBA quarters despite showing strong performance in counting NFL quarter scores. This leads us to further investigate the factors that impact the complexity of analytical reasoning tasks with extensive experiments, through which we conclude that task complexity depends on the length of context, the information density, and the presence of related information. Our research provides valuable insights into the complexity of analytical reasoning tasks and potential directions for developing future large language models.
SportsMetrics: Blending Text and Numerical Data to Understand Information Fusion in LLMs
Feb 15, 2024Large language models hold significant potential for integrating various data types, such as text documents and database records, for advanced analytics. However, blending text and numerical data presents substantial challenges. LLMs need to process and cross-reference entities and numbers, handle data inconsistencies and redundancies, and develop planning capabilities such as building a working memory for managing complex data queries. In this paper, we introduce four novel tasks centered around sports data analytics to evaluate the numerical reasoning and information fusion capabilities of LLMs. These tasks involve providing LLMs with detailed, play-by-play sports game descriptions, then challenging them with adversarial scenarios such as new game rules, longer durations, scrambled narratives, and analyzing key statistics in game summaries. We conduct extensive experiments on NBA and NFL games to assess the performance of LLMs on these tasks. Our benchmark, SportsMetrics, introduces a new mechanism for assessing LLMs' numerical reasoning and fusion skills.
FedCore: Straggler-Free Federated Learning with Distributed Coresets
Jan 31, 2024Federated learning (FL) is a machine learning paradigm that allows multiple clients to collaboratively train a shared model while keeping their data on-premise. However, the straggler issue, due to slow clients, often hinders the efficiency and scalability of FL. This paper presents FedCore, an algorithm that innovatively tackles the straggler problem via the decentralized selection of coresets, representative subsets of a dataset. Contrary to existing centralized coreset methods, FedCore creates coresets directly on each client in a distributed manner, ensuring privacy preservation in FL. FedCore translates the coreset optimization problem into a more tractable k-medoids clustering problem and operates distributedly on each client. Theoretical analysis confirms FedCore's convergence, and practical evaluations demonstrate an 8x reduction in FL training time, without compromising model accuracy. Our extensive evaluations also show that FedCore generalizes well to existing FL frameworks.