 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRuihong Huang
Indexing Analytics to Instances: How Integrating a Dashboard can Support Design Education
Apr 08, 2024
We investigate how to use AI-based analytics to support design education. The analytics at hand measure multiscale design, that is, students' use of space and scale to visually and conceptually organize their design work. With the goal of making the analytics intelligible to instructors, we developed a research artifact integrating a design analytics dashboard with design instances, and the design environment that students use to create them. We theorize about how Suchman's notion of mutual intelligibility requires contextualized investigation of AI in order to develop findings about how analytics work for people. We studied the research artifact in 5 situated course contexts, in 3 departments. A total of 236 students used the multiscale design environment. The 9 instructors who taught those students experienced the analytics via the new research artifact. We derive findings from a qualitative analysis of interviews with instructors regarding their experiences. Instructors reflected on how the analytics and their presentation in the dashboard have the potential to affect design education. We develop research implications addressing: (1) how indexing design analytics in the dashboard to actual design work instances helps design instructors reflect on what they mean and, more broadly, is a technique for how AI-based design analytics can support instructors' assessment and feedback experiences in situated course contexts; and (2) how multiscale design analytics, in particular, have the potential to support design education. By indexing, we mean linking which provides context, here connecting the numbers of the analytics with visually annotated design work instances.
EMONA: Event-level Moral Opinions in News Articles
Apr 02, 2024Most previous research on moral frames has focused on social media short texts, little work has explored moral sentiment within news articles. In news articles, authors often express their opinions or political stance through moral judgment towards events, specifically whether the event is right or wrong according to social moral rules. This paper initiates a new task to understand moral opinions towards events in news articles. We have created a new dataset, EMONA, and annotated event-level moral opinions in news articles. This dataset consists of 400 news articles containing over 10k sentences and 45k events, among which 9,613 events received moral foundation labels. Extracting event morality is a challenging task, as moral judgment towards events can be very implicit. Baseline models were built for event moral identification and classification. In addition, we also conduct extrinsic evaluations to integrate event-level moral opinions into three downstream tasks. The statistical analysis and experiments show that moral opinions of events can serve as informative features for identifying ideological bias or subjective events.
Sentence-level Media Bias Analysis with Event Relation Graph
Apr 02, 2024Media outlets are becoming more partisan and polarized nowadays. In this paper, we identify media bias at the sentence level, and pinpoint bias sentences that intend to sway readers' opinions. As bias sentences are often expressed in a neutral and factual way, considering broader context outside a sentence can help reveal the bias. In particular, we observe that events in a bias sentence need to be understood in associations with other events in the document. Therefore, we propose to construct an event relation graph to explicitly reason about event-event relations for sentence-level bias identification. The designed event relation graph consists of events as nodes and four common types of event relations: coreference, temporal, causal, and subevent relations. Then, we incorporate event relation graph for bias sentences identification in two steps: an event-aware language model is built to inject the events and event relations knowledge into the basic language model via soft labels; further, a relation-aware graph attention network is designed to update sentence embedding with events and event relations information based on hard labels. Experiments on two benchmark datasets demonstrate that our approach with the aid of event relation graph improves both precision and recall of bias sentence identification.
Polarity Calibration for Opinion Summarization
Apr 02, 2024Opinion summarization is automatically generating summaries from a variety of subjective information, such as product reviews or political opinions. The challenge of opinions summarization lies in presenting divergent or even conflicting opinions. We conduct an analysis of previous summarization models, which reveals their inclination to amplify the polarity bias, emphasizing the majority opinions while ignoring the minority opinions. To address this issue and make the summarizer express both sides of opinions, we introduce the concept of polarity calibration, which aims to align the polarity of output summary with that of input text. Specifically, we develop a reinforcement training approach for polarity calibration. This approach feeds the polarity distance between output summary and input text as reward into the summarizer, and also balance polarity calibration with content preservation and language naturality. We evaluate our Polarity Calibration model (PoCa) on two types of opinions summarization tasks: summarizing product reviews and political opinions articles. Automatic and human evaluation demonstrate that our approach can mitigate the polarity mismatch between output summary and input text, as well as maintain the content semantic and language quality.
Identifying Conspiracy Theories News based on Event Relation Graph
Oct 28, 2023

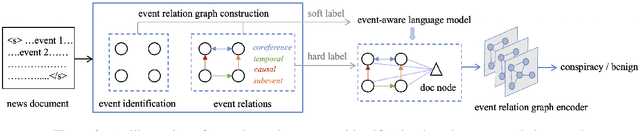
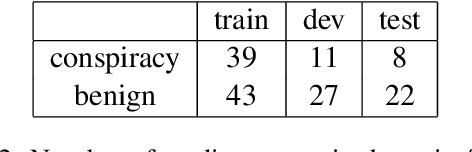
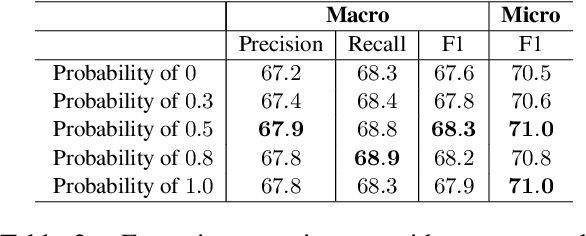
Conspiracy theories, as a type of misinformation, are narratives that explains an event or situation in an irrational or malicious manner. While most previous work examined conspiracy theory in social media short texts, limited attention was put on such misinformation in long news documents. In this paper, we aim to identify whether a news article contains conspiracy theories. We observe that a conspiracy story can be made up by mixing uncorrelated events together, or by presenting an unusual distribution of relations between events. Achieving a contextualized understanding of events in a story is essential for detecting conspiracy theories. Thus, we propose to incorporate an event relation graph for each article, in which events are nodes, and four common types of event relations, coreference, temporal, causal, and subevent relations, are considered as edges. Then, we integrate the event relation graph into conspiracy theory identification in two ways: an event-aware language model is developed to augment the basic language model with the knowledge of events and event relations via soft labels; further, a heterogeneous graph attention network is designed to derive a graph embedding based on hard labels. Experiments on a large benchmark dataset show that our approach based on event relation graph improves both precision and recall of conspiracy theory identification, and generalizes well for new unseen media sources.
Discourse Structures Guided Fine-grained Propaganda Identification
Oct 28, 2023



Propaganda is a form of deceptive narratives that instigate or mislead the public, usually with a political purpose. In this paper, we aim to identify propaganda in political news at two fine-grained levels: sentence-level and token-level. We observe that propaganda content is more likely to be embedded in sentences that attribute causality or assert contrast to nearby sentences, as well as seen in opinionated evaluation, speculation and discussions of future expectation. Hence, we propose to incorporate both local and global discourse structures for propaganda discovery and construct two teacher models for identifying PDTB-style discourse relations between nearby sentences and common discourse roles of sentences in a news article respectively. We further devise two methods to incorporate the two types of discourse structures for propaganda identification by either using teacher predicted probabilities as additional features or soliciting guidance in a knowledge distillation framework. Experiments on the benchmark dataset demonstrate that leveraging guidance from discourse structures can significantly improve both precision and recall of propaganda content identification.
All Things Considered: Detecting Partisan Events from News Media with Cross-Article Comparison
Oct 28, 2023Public opinion is shaped by the information news media provide, and that information in turn may be shaped by the ideological preferences of media outlets. But while much attention has been devoted to media bias via overt ideological language or topic selection, a more unobtrusive way in which the media shape opinion is via the strategic inclusion or omission of partisan events that may support one side or the other. We develop a latent variable-based framework to predict the ideology of news articles by comparing multiple articles on the same story and identifying partisan events whose inclusion or omission reveals ideology. Our experiments first validate the existence of partisan event selection, and then show that article alignment and cross-document comparison detect partisan events and article ideology better than competitive baselines. Our results reveal the high-level form of media bias, which is present even among mainstream media with strong norms of objectivity and nonpartisanship. Our codebase and dataset are available at https://github.com/launchnlp/ATC.
Semi-supervised News Discourse Profiling with Contrastive Learning
Sep 20, 2023

News Discourse Profiling seeks to scrutinize the event-related role of each sentence in a news article and has been proven useful across various downstream applications. Specifically, within the context of a given news discourse, each sentence is assigned to a pre-defined category contingent upon its depiction of the news event structure. However, existing approaches suffer from an inadequacy of available human-annotated data, due to the laborious and time-intensive nature of generating discourse-level annotations. In this paper, we present a novel approach, denoted as Intra-document Contrastive Learning with Distillation (ICLD), for addressing the news discourse profiling task, capitalizing on its unique structural characteristics. Notably, we are the first to apply a semi-supervised methodology within this task paradigm, and evaluation demonstrates the effectiveness of the presented approach.
RST-style Discourse Parsing Guided by Document-level Content Structures
Sep 08, 2023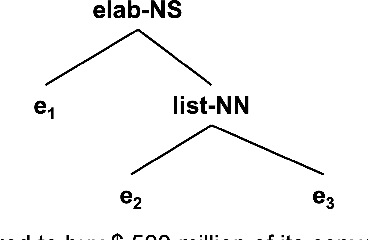



Rhetorical Structure Theory based Discourse Parsing (RST-DP) explores how clauses, sentences, and large text spans compose a whole discourse and presents the rhetorical structure as a hierarchical tree. Existing RST parsing pipelines construct rhetorical structures without the knowledge of document-level content structures, which causes relatively low performance when predicting the discourse relations for large text spans. Recognizing the value of high-level content-related information in facilitating discourse relation recognition, we propose a novel pipeline for RST-DP that incorporates structure-aware news content sentence representations derived from the task of News Discourse Profiling. By incorporating only a few additional layers, this enhanced pipeline exhibits promising performance across various RST parsing metrics.
Composition-contrastive Learning for Sentence Embeddings
Jul 14, 2023
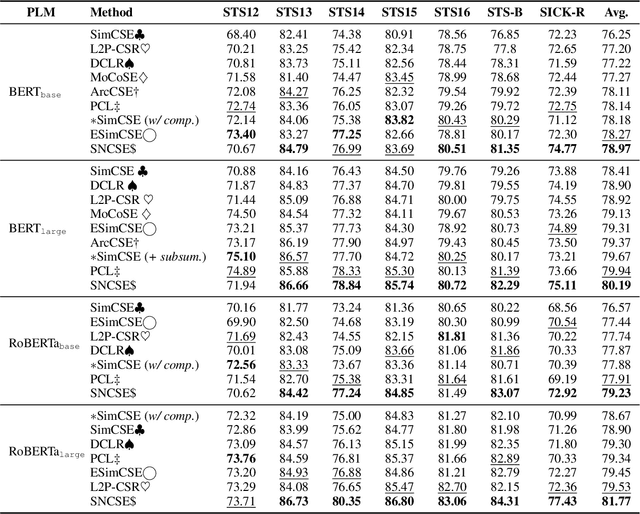
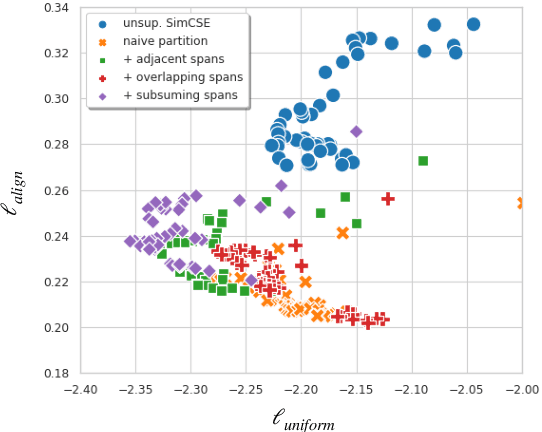

Vector representations of natural language are ubiquitous in search applications. Recently, various methods based on contrastive learning have been proposed to learn textual representations from unlabelled data; by maximizing alignment between minimally-perturbed embeddings of the same text, and encouraging a uniform distribution of embeddings across a broader corpus. Differently, we propose maximizing alignment between texts and a composition of their phrasal constituents. We consider several realizations of this objective and elaborate the impact on representations in each case. Experimental results on semantic textual similarity tasks show improvements over baselines that are comparable with state-of-the-art approaches. Moreover, this work is the first to do so without incurring costs in auxiliary training objectives or additional network parameters.