 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKlara Nahrstedt
Federated Transfer Learning with Task Personalization for Condition Monitoring in Ultrasonic Metal Welding
Apr 20, 2024
Ultrasonic metal welding (UMW) is a key joining technology with widespread industrial applications. Condition monitoring (CM) capabilities are critically needed in UMW applications because process anomalies significantly deteriorate the joining quality. Recently, machine learning models emerged as a promising tool for CM in many manufacturing applications due to their ability to learn complex patterns. Yet, the successful deployment of these models requires substantial training data that may be expensive and time-consuming to collect. Additionally, many existing machine learning models lack generalizability and cannot be directly applied to new process configurations (i.e., domains). Such issues may be potentially alleviated by pooling data across manufacturers, but data sharing raises critical data privacy concerns. To address these challenges, this paper presents a Federated Transfer Learning with Task Personalization (FTL-TP) framework that provides domain generalization capabilities in distributed learning while ensuring data privacy. By effectively learning a unified representation from feature space, FTL-TP can adapt CM models for clients working on similar tasks, thereby enhancing their overall adaptability and performance jointly. To demonstrate the effectiveness of FTL-TP, we investigate two distinct UMW CM tasks, tool condition monitoring and workpiece surface condition classification. Compared with state-of-the-art FL algorithms, FTL-TP achieves a 5.35%--8.08% improvement of accuracy in CM in new target domains. FTL-TP is also shown to perform excellently in challenging scenarios involving unbalanced data distributions and limited client fractions. Furthermore, by implementing the FTL-TP method on an edge-cloud architecture, we show that this method is both viable and efficient in practice. The FTL-TP framework is readily extensible to various other manufacturing applications.
FedCore: Straggler-Free Federated Learning with Distributed Coresets
Jan 31, 2024Federated learning (FL) is a machine learning paradigm that allows multiple clients to collaboratively train a shared model while keeping their data on-premise. However, the straggler issue, due to slow clients, often hinders the efficiency and scalability of FL. This paper presents FedCore, an algorithm that innovatively tackles the straggler problem via the decentralized selection of coresets, representative subsets of a dataset. Contrary to existing centralized coreset methods, FedCore creates coresets directly on each client in a distributed manner, ensuring privacy preservation in FL. FedCore translates the coreset optimization problem into a more tractable k-medoids clustering problem and operates distributedly on each client. Theoretical analysis confirms FedCore's convergence, and practical evaluations demonstrate an 8x reduction in FL training time, without compromising model accuracy. Our extensive evaluations also show that FedCore generalizes well to existing FL frameworks.
WeldMon: A Cost-effective Ultrasonic Welding Machine Condition Monitoring System
Aug 05, 2023



Ultrasonic welding machines play a critical role in the lithium battery industry, facilitating the bonding of batteries with conductors. Ensuring high-quality welding is vital, making tool condition monitoring systems essential for early-stage quality control. However, existing monitoring methods face challenges in cost, downtime, and adaptability. In this paper, we present WeldMon, an affordable ultrasonic welding machine condition monitoring system that utilizes a custom data acquisition system and a data analysis pipeline designed for real-time analysis. Our classification algorithm combines auto-generated features and hand-crafted features, achieving superior cross-validation accuracy (95.8% on average over all testing tasks) compared to the state-of-the-art method (92.5%) in condition classification tasks. Our data augmentation approach alleviates the concept drift problem, enhancing tool condition classification accuracy by 8.3%. All algorithms run locally, requiring only 385 milliseconds to process data for each welding cycle. We deploy WeldMon and a commercial system on an actual ultrasonic welding machine, performing a comprehensive comparison. Our findings highlight the potential for developing cost-effective, high-performance, and reliable tool condition monitoring systems.
Hierarchical Semi-Supervised Contrastive Learning for Contamination-Resistant Anomaly Detection
Jul 24, 2022



Anomaly detection aims at identifying deviant samples from the normal data distribution. Contrastive learning has provided a successful way to sample representation that enables effective discrimination on anomalies. However, when contaminated with unlabeled abnormal samples in training set under semi-supervised settings, current contrastive-based methods generally 1) ignore the comprehensive relation between training data, leading to suboptimal performance, and 2) require fine-tuning, resulting in low efficiency. To address the above two issues, in this paper, we propose a novel hierarchical semi-supervised contrastive learning (HSCL) framework, for contamination-resistant anomaly detection. Specifically, HSCL hierarchically regulates three complementary relations: sample-to-sample, sample-to-prototype, and normal-to-abnormal relations, enlarging the discrimination between normal and abnormal samples with a comprehensive exploration of the contaminated data. Besides, HSCL is an end-to-end learning approach that can efficiently learn discriminative representations without fine-tuning. HSCL achieves state-of-the-art performance in multiple scenarios, such as one-class classification and cross-dataset detection. Extensive ablation studies further verify the effectiveness of each considered relation. The code is available at https://github.com/GaoangW/HSCL.
CrossRoI: Cross-camera Region of Interest Optimization for Efficient Real Time Video Analytics at Scale
May 13, 2021
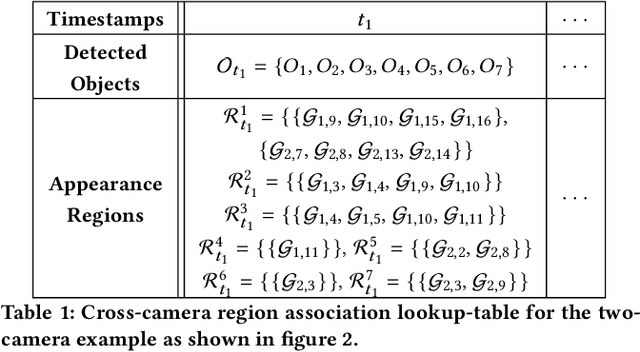
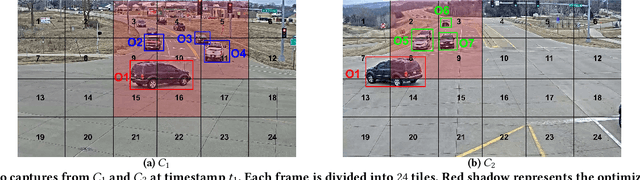
Video cameras are pervasively deployed in city scale for public good or community safety (i.e. traffic monitoring or suspected person tracking). However, analyzing large scale video feeds in real time is data intensive and poses severe challenges to network and computation systems today. We present CrossRoI, a resource-efficient system that enables real time video analytics at scale via harnessing the videos content associations and redundancy across a fleet of cameras. CrossRoI exploits the intrinsic physical correlations of cross-camera viewing fields to drastically reduce the communication and computation costs. CrossRoI removes the repentant appearances of same objects in multiple cameras without harming comprehensive coverage of the scene. CrossRoI operates in two phases - an offline phase to establish cross-camera correlations, and an efficient online phase for real time video inference. Experiments on real-world video feeds show that CrossRoI achieves 42% - 65% reduction for network overhead and 25% - 34% reduction for response delay in real time video analytics applications with more than 99% query accuracy, when compared to baseline methods. If integrated with SotA frame filtering systems, the performance gains of CrossRoI reach 50% - 80% (network overhead) and 33% - 61% (end-to-end delay).
DeepRT: A Soft Real Time Scheduler for Computer Vision Applications on the Edge
May 05, 2021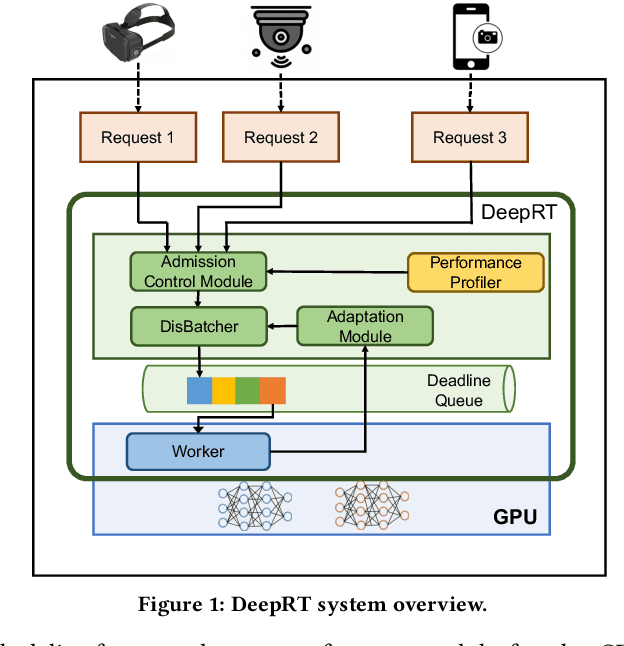
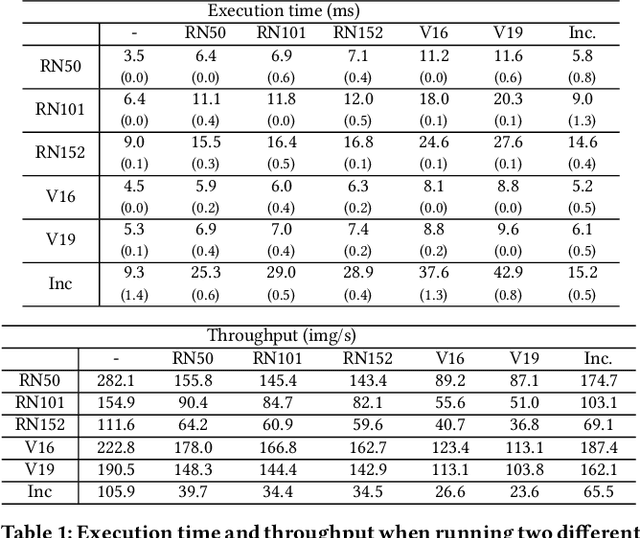
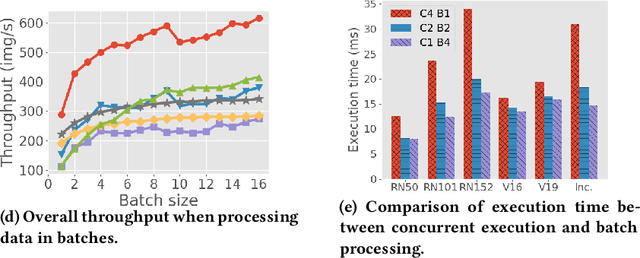
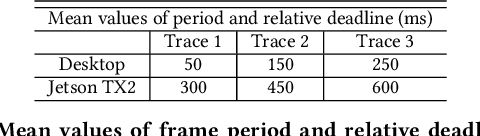
The ubiquity of smartphone cameras and IoT cameras, together with the recent boom of deep learning and deep neural networks, proliferate various computer vision driven mobile and IoT applications deployed on the edge. This paper focuses on applications which make soft real time requests to perform inference on their data - they desire prompt responses within designated deadlines, but occasional deadline misses are acceptable. Supporting soft real time applications on a multi-tenant edge server is not easy, since the requests sharing the limited GPU computing resources of an edge server interfere with each other. In order to tackle this problem, we comprehensively evaluate how latency and throughput respond to different GPU execution plans. Based on this analysis, we propose a GPU scheduler, DeepRT, which provides latency guarantee to the requests while maintaining high overall system throughput. The key component of DeepRT, DisBatcher, batches data from different requests as much as possible while it is proven to provide latency guarantee for requests admitted by an Admission Control Module. DeepRT also includes an Adaptation Module which tackles overruns. Our evaluation results show that DeepRT outperforms state-of-the-art works in terms of the number of deadline misses and throughput.
Robusta: Robust AutoML for Feature Selection via Reinforcement Learning
Jan 15, 2021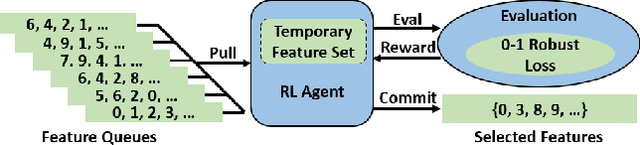
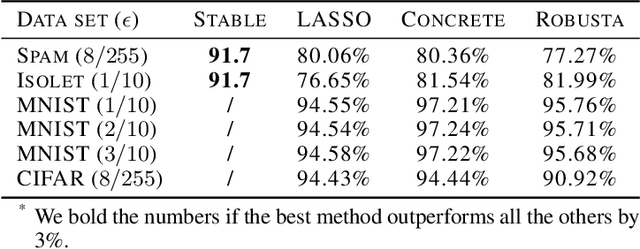
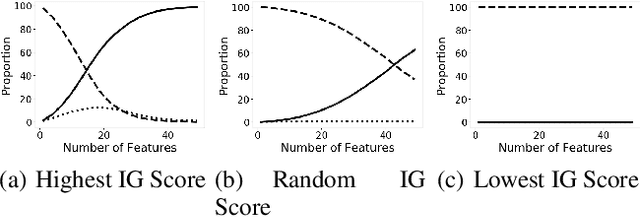
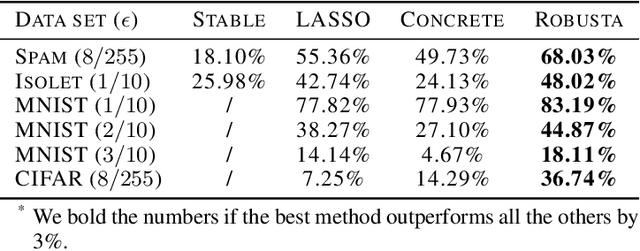
Several AutoML approaches have been proposed to automate the machine learning (ML) process, such as searching for the ML model architectures and hyper-parameters. However, these AutoML pipelines only focus on improving the learning accuracy of benign samples while ignoring the ML model robustness under adversarial attacks. As ML systems are increasingly being used in a variety of mission-critical applications, improving the robustness of ML systems has become of utmost importance. In this paper, we propose the first robust AutoML framework, Robusta--based on reinforcement learning (RL)--to perform feature selection, aiming to select features that lead to both accurate and robust ML systems. We show that a variation of the 0-1 robust loss can be directly optimized via an RL-based combinatorial search in the feature selection scenario. In addition, we employ heuristics to accelerate the search procedure based on feature scoring metrics, which are mutual information scores, tree-based classifiers feature importance scores, F scores, and Integrated Gradient (IG) scores, as well as their combinations. We conduct extensive experiments and show that the proposed framework is able to improve the model robustness by up to 22% while maintaining competitive accuracy on benign samples compared with other feature selection methods.
Serdab: An IoT Framework for Partitioning Neural Networks Computation across Multiple Enclaves
May 12, 2020



Recent advances in Deep Neural Networks (DNN) and Edge Computing have made it possible to automatically analyze streams of videos from home/security cameras over hierarchical clusters that include edge devices, close to the video source, as well as remote cloud compute resources. However, preserving the privacy and confidentiality of users' sensitive data as it passes through different devices remains a concern to most users. Private user data is subject to attacks by malicious attackers or misuse by internal administrators who may use the data in activities that are not explicitly approved by the user. To address this challenge, we present Serdab, a distributed orchestration framework for deploying deep neural network computation across multiple secure enclaves (e.g., Intel SGX). Secure enclaves provide a guarantee on the privacy of the data/code deployed inside it. However, their limited hardware resources make them inefficient when solely running an entire deep neural network. To bridge this gap, Serdab presents a DNN partitioning strategy to distribute the layers of the neural network across multiple enclave devices or across an enclave device and other hardware accelerators. Our partitioning strategy achieves up to 4.7x speedup compared to executing the entire neural network in one enclave.