 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChao-Yeh Chen
Learning Unified Embedding for Apparel Recognition
Aug 15, 2017
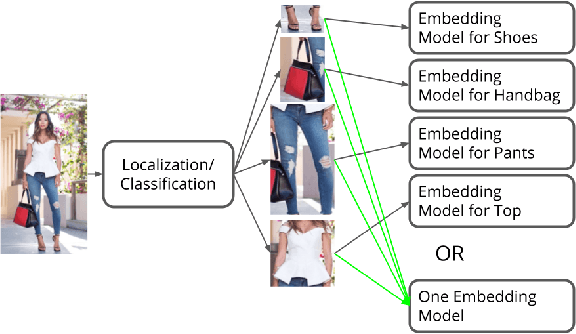


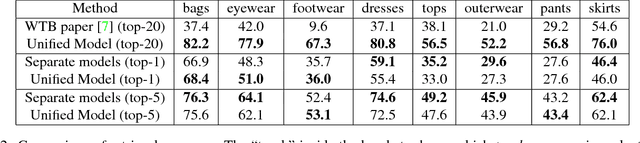
In apparel recognition, specialized models (e.g. models trained for a particular vertical like dresses) can significantly outperform general models (i.e. models that cover a wide range of verticals). Therefore, deep neural network models are often trained separately for different verticals. However, using specialized models for different verticals is not scalable and expensive to deploy. This paper addresses the problem of learning one unified embedding model for multiple object verticals (e.g. all apparel classes) without sacrificing accuracy. The problem is tackled from two aspects: training data and training difficulty. On the training data aspect, we figure out that for a single model trained with triplet loss, there is an accuracy sweet spot in terms of how many verticals are trained together. To ease the training difficulty, a novel learning scheme is proposed by using the output from specialized models as learning targets so that L2 loss can be used instead of triplet loss. This new loss makes the training easier and make it possible for more efficient use of the feature space. The end result is a unified model which can achieve the same retrieval accuracy as a number of separate specialized models, while having the model complexity as one. The effectiveness of our approach is shown in experiments.
Efficient Activity Detection in Untrimmed Video with Max-Subgraph Search
Jul 11, 2016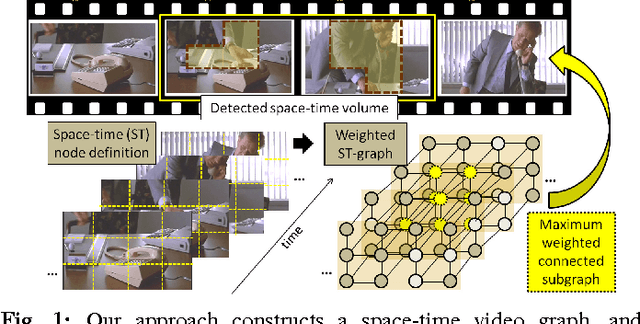
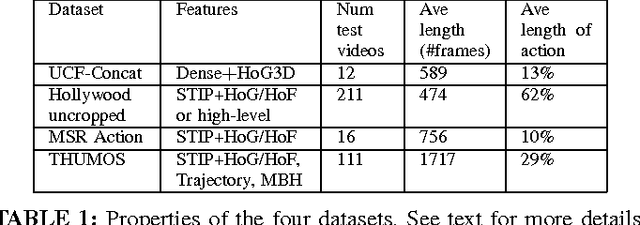
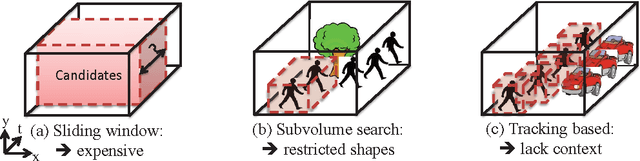
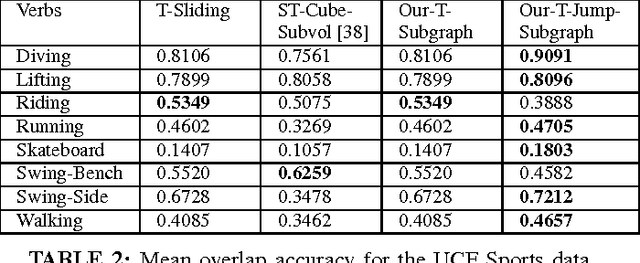
We propose an efficient approach for activity detection in video that unifies activity categorization with space-time localization. The main idea is to pose activity detection as a maximum-weight connected subgraph problem. Offline, we learn a binary classifier for an activity category using positive video exemplars that are "trimmed" in time to the activity of interest. Then, given a novel \emph{untrimmed} video sequence, we decompose it into a 3D array of space-time nodes, which are weighted based on the extent to which their component features support the learned activity model. To perform detection, we then directly localize instances of the activity by solving for the maximum-weight connected subgraph in the test video's space-time graph. We show that this detection strategy permits an efficient branch-and-cut solution for the best-scoring---and possibly non-cubically shaped---portion of the video for a given activity classifier. The upshot is a fast method that can search a broader space of space-time region candidates than was previously practical, which we find often leads to more accurate detection. We demonstrate the proposed algorithm on four datasets, and we show its speed and accuracy advantages over multiple existing search strategies.
Subjects and Their Objects: Localizing Interactees for a Person-Centric View of Importance
Apr 17, 2016
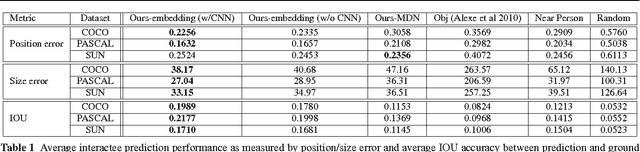

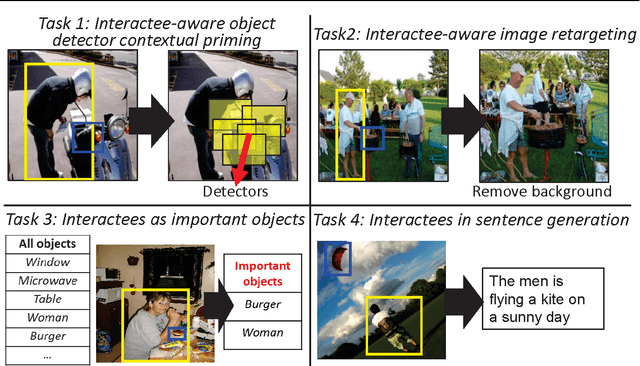
Understanding images with people often entails understanding their \emph{interactions} with other objects or people. As such, given a novel image, a vision system ought to infer which other objects/people play an important role in a given person's activity. However, existing methods are limited to learning action-specific interactions (e.g., how the pose of a tennis player relates to the position of his racquet when serving the ball) for improved recognition, making them unequipped to reason about novel interactions with actions or objects unobserved in the training data. We propose to predict the "interactee" in novel images---that is, to localize the \emph{object} of a person's action. Given an arbitrary image with a detected person, the goal is to produce a saliency map indicating the most likely positions and scales where that person's interactee would be found. To that end, we explore ways to learn the generic, action-independent connections between (a) representations of a person's pose, gaze, and scene cues and (b) the interactee object's position and scale. We provide results on a newly collected UT Interactee dataset spanning more than 10,000 images from SUN, PASCAL, and COCO. We show that the proposed interaction-informed saliency metric has practical utility for four tasks: contextual object detection, image retargeting, predicting object importance, and data-driven natural language scene description. All four scenarios reveal the value in linking the subject to its object in order to understand the story of an image.