 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChaoli Wang
ConvFormer: Combining CNN and Transformer for Medical Image Segmentation
Nov 15, 2022




Convolutional neural network (CNN) based methods have achieved great successes in medical image segmentation, but their capability to learn global representations is still limited due to using small effective receptive fields of convolution operations. Transformer based methods are capable of modelling long-range dependencies of information for capturing global representations, yet their ability to model local context is lacking. Integrating CNN and Transformer to learn both local and global representations while exploring multi-scale features is instrumental in further improving medical image segmentation. In this paper, we propose a hierarchical CNN and Transformer hybrid architecture, called ConvFormer, for medical image segmentation. ConvFormer is based on several simple yet effective designs. (1) A feed forward module of Deformable Transformer (DeTrans) is re-designed to introduce local information, called Enhanced DeTrans. (2) A residual-shaped hybrid stem based on a combination of convolutions and Enhanced DeTrans is developed to capture both local and global representations to enhance representation ability. (3) Our encoder utilizes the residual-shaped hybrid stem in a hierarchical manner to generate feature maps in different scales, and an additional Enhanced DeTrans encoder with residual connections is built to exploit multi-scale features with feature maps of different scales as input. Experiments on several datasets show that our ConvFormer, trained from scratch, outperforms various CNN- or Transformer-based architectures, achieving state-of-the-art performance.
DL4SciVis: A State-of-the-Art Survey on Deep Learning for Scientific Visualization
Apr 13, 2022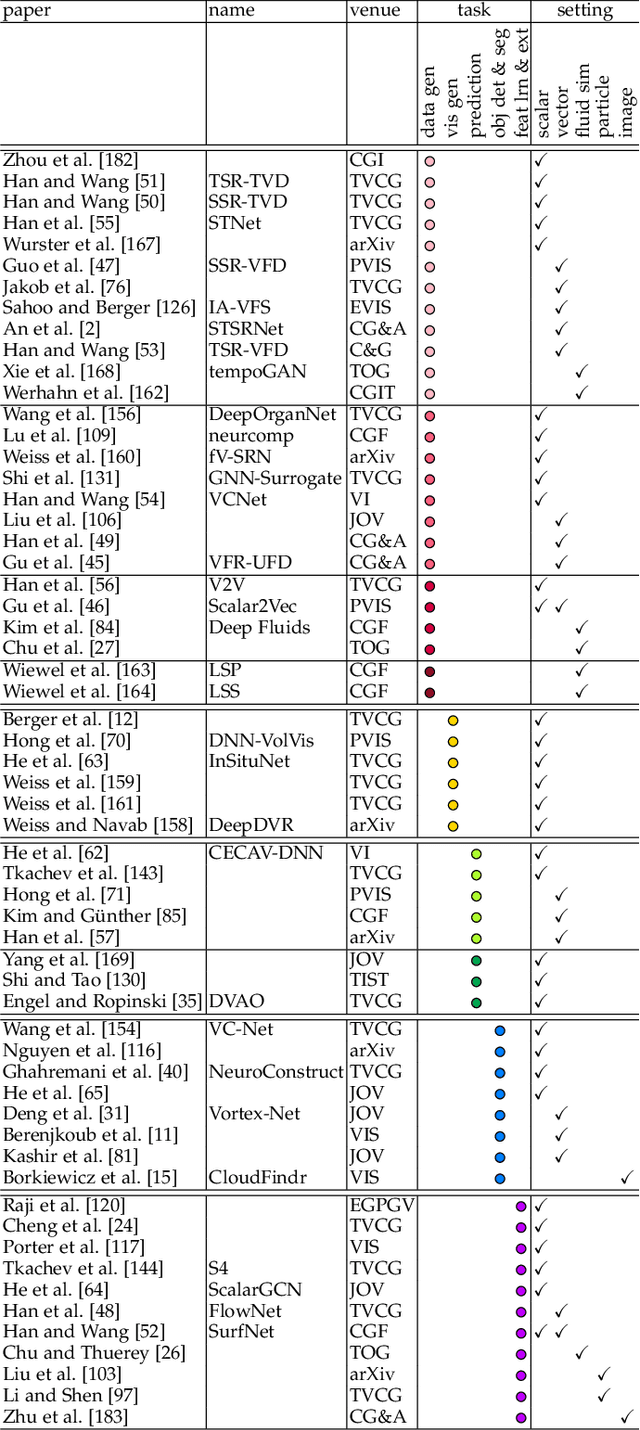
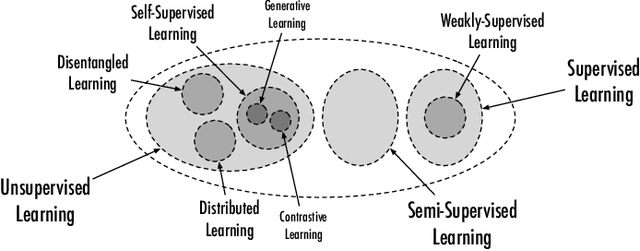
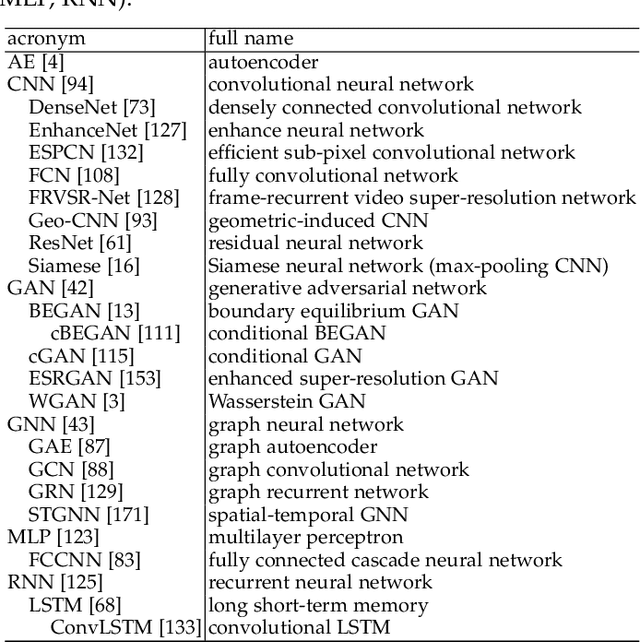
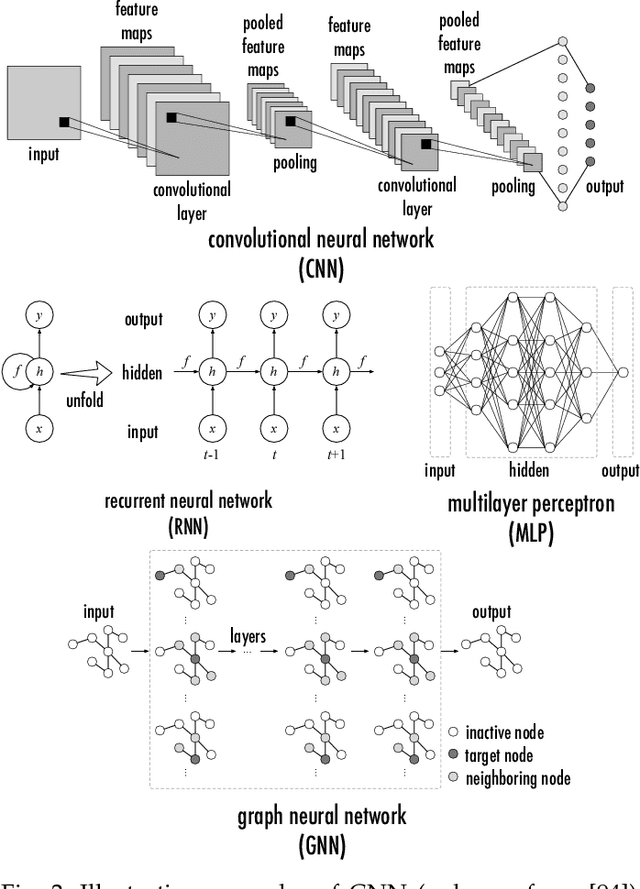
Since 2016, we have witnessed the tremendous growth of artificial intelligence+visualization (AI+VIS) research. However, existing survey papers on AI+VIS focus on visual analytics and information visualization, not scientific visualization (SciVis). In this paper, we survey related deep learning (DL) works in SciVis, specifically in the direction of DL4SciVis: designing DL solutions for solving SciVis problems. To stay focused, we primarily consider works that handle scalar and vector field data but exclude mesh data. We classify and discuss these works along six dimensions: domain setting, research task, learning type, network architecture, loss function, and evaluation metric. The paper concludes with a discussion of the remaining gaps to fill along the discussed dimensions and the grand challenges we need to tackle as a community. This state-of-the-art survey guides SciVis researchers in gaining an overview of this emerging topic and points out future directions to grow this research.
Hierarchical Self-Supervised Learning for Medical Image Segmentation Based on Multi-Domain Data Aggregation
Jul 10, 2021
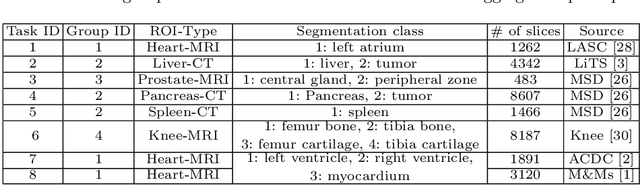
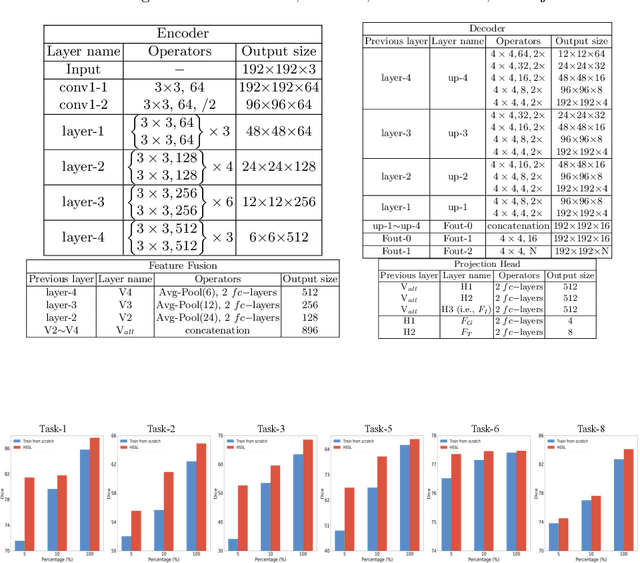
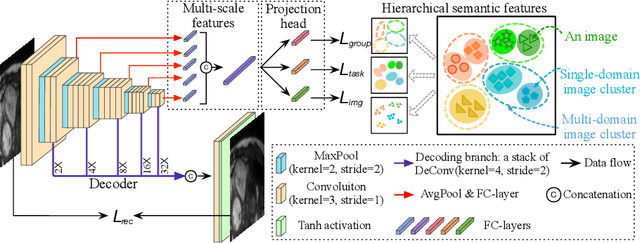
A large labeled dataset is a key to the success of supervised deep learning, but for medical image segmentation, it is highly challenging to obtain sufficient annotated images for model training. In many scenarios, unannotated images are abundant and easy to acquire. Self-supervised learning (SSL) has shown great potentials in exploiting raw data information and representation learning. In this paper, we propose Hierarchical Self-Supervised Learning (HSSL), a new self-supervised framework that boosts medical image segmentation by making good use of unannotated data. Unlike the current literature on task-specific self-supervised pretraining followed by supervised fine-tuning, we utilize SSL to learn task-agnostic knowledge from heterogeneous data for various medical image segmentation tasks. Specifically, we first aggregate a dataset from several medical challenges, then pre-train the network in a self-supervised manner, and finally fine-tune on labeled data. We develop a new loss function by combining contrastive loss and classification loss and pretrain an encoder-decoder architecture for segmentation tasks. Our extensive experiments show that multi-domain joint pre-training benefits downstream segmentation tasks and outperforms single-domain pre-training significantly. Compared to learning from scratch, our new method yields better performance on various tasks (e.g., +0.69% to +18.60% in Dice scores with 5% of annotated data). With limited amounts of training data, our method can substantially bridge the performance gap w.r.t. denser annotations (e.g., 10% vs.~100% of annotated data).
A New Ensemble Learning Framework for 3D Biomedical Image Segmentation
Dec 10, 2018



3D image segmentation plays an important role in biomedical image analysis. Many 2D and 3D deep learning models have achieved state-of-the-art segmentation performance on 3D biomedical image datasets. Yet, 2D and 3D models have their own strengths and weaknesses, and by unifying them together, one may be able to achieve more accurate results. In this paper, we propose a new ensemble learning framework for 3D biomedical image segmentation that combines the merits of 2D and 3D models. First, we develop a fully convolutional network based meta-learner to learn how to improve the results from 2D and 3D models (base-learners). Then, to minimize over-fitting for our sophisticated meta-learner, we devise a new training method that uses the results of the base-learners as multiple versions of "ground truths". Furthermore, since our new meta-learner training scheme does not depend on manual annotation, it can utilize abundant unlabeled 3D image data to further improve the model. Extensive experiments on two public datasets (the HVSMR 2016 Challenge dataset and the mouse piriform cortex dataset) show that our approach is effective under fully-supervised, semi-supervised, and transductive settings, and attains superior performance over state-of-the-art image segmentation methods.