 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChris Brockett
GRIM: GRaph-based Interactive narrative visualization for gaMes
Nov 15, 2023
Dialogue-based Role Playing Games (RPGs) require powerful storytelling. The narratives of these may take years to write and typically involve a large creative team. In this work, we demonstrate the potential of large generative text models to assist this process. \textbf{GRIM}, a prototype \textbf{GR}aph-based \textbf{I}nteractive narrative visualization system for ga\textbf{M}es, generates a rich narrative graph with branching storylines that match a high-level narrative description and constraints provided by the designer. Game designers can interactively edit the graph by automatically generating new sub-graphs that fit the edits within the original narrative and constraints. We illustrate the use of \textbf{GRIM} in conjunction with GPT-4, generating branching narratives for four well-known stories with different contextual constraints.
Towards Dialogue Systems with Agency in Human-AI Collaboration Tasks
May 22, 2023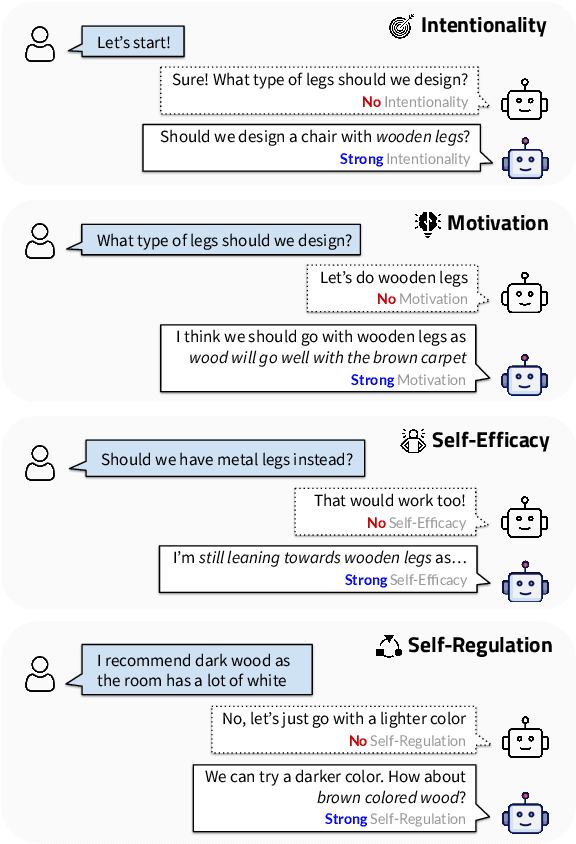

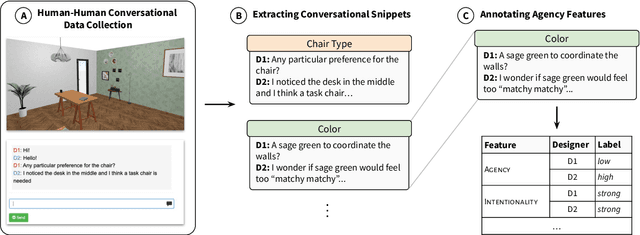

Agency, the capacity to proactively shape events, is crucial to how humans interact and collaborate with other humans. In this paper, we investigate Agency as a potentially desirable function of dialogue agents, and how it can be measured and controlled. We build upon the social-cognitive theory of Bandura (2001) to develop a framework of features through which Agency is expressed in dialogue -- indicating what you intend to do (Intentionality), motivating your intentions (Motivation), having self-belief in intentions (Self-Efficacy), and being able to self-adjust (Self-Regulation). We collect and release a new dataset of 83 human-human collaborative interior design conversations containing 908 conversational snippets annotated for Agency features. Using this dataset, we explore methods for measuring and controlling Agency in dialogue systems. Automatic and human evaluation show that although a baseline GPT-3 model can express Intentionality, models that explicitly manifest features associated with high Motivation, Self-Efficacy, and Self-Regulation are better perceived as being highly agentive. This work has implications for the development of dialogue systems with varying degrees of Agency in collaborative tasks.
GODEL: Large-Scale Pre-Training for Goal-Directed Dialog
Jun 22, 2022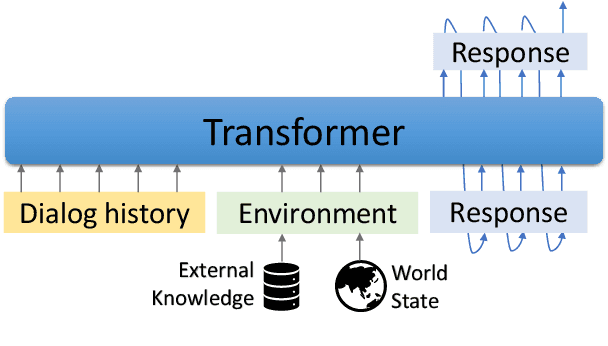
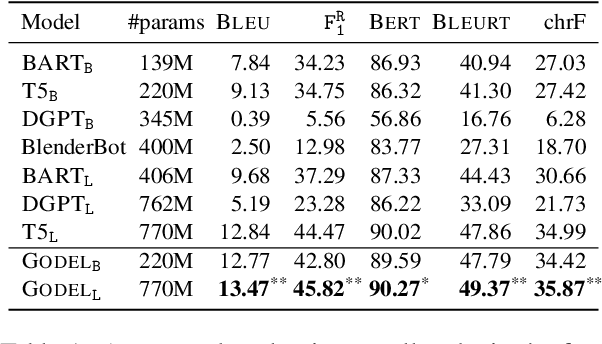


We introduce GODEL (Grounded Open Dialogue Language Model), a large pre-trained language model for dialog. In contrast with earlier models such as DialoGPT, GODEL leverages a new phase of grounded pre-training designed to better support adapting GODEL to a wide range of downstream dialog tasks that require information external to the current conversation (e.g., a database or document) to produce good responses. Experiments against an array of benchmarks that encompass task-oriented dialog, conversational QA, and grounded open-domain dialog show that GODEL outperforms state-of-the-art pre-trained dialog models in few-shot fine-tuning setups, in terms of both human and automatic evaluation. A novel feature of our evaluation methodology is the introduction of a notion of utility that assesses the usefulness of responses (extrinsic evaluation) in addition to their communicative features (intrinsic evaluation). We show that extrinsic evaluation offers improved inter-annotator agreement and correlation with automated metrics. Code and data processing scripts are publicly available.
Automatic Document Sketching: Generating Drafts from Analogous Texts
Jun 14, 2021

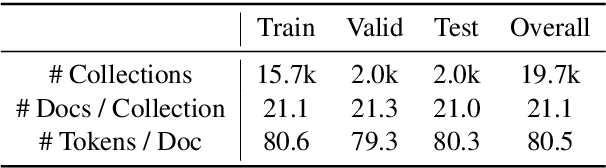
The advent of large pre-trained language models has made it possible to make high-quality predictions on how to add or change a sentence in a document. However, the high branching factor inherent to text generation impedes the ability of even the strongest language models to offer useful editing suggestions at a more global or document level. We introduce a new task, document sketching, which involves generating entire draft documents for the writer to review and revise. These drafts are built from sets of documents that overlap in form - sharing large segments of potentially reusable text - while diverging in content. To support this task, we introduce a Wikipedia-based dataset of analogous documents and investigate the application of weakly supervised methods, including use of a transformer-based mixture of experts, together with reinforcement learning. We report experiments using automated and human evaluation methods and discuss relative merits of these models.
Joint Retrieval and Generation Training for Grounded Text Generation
Jun 03, 2021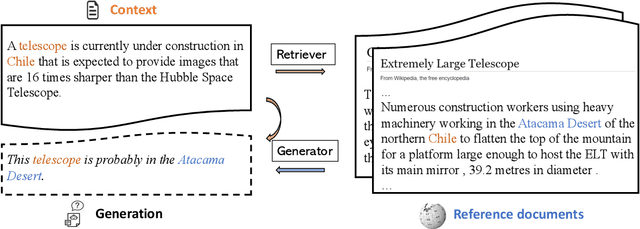
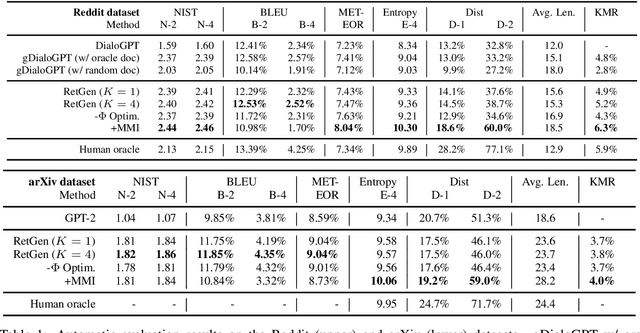
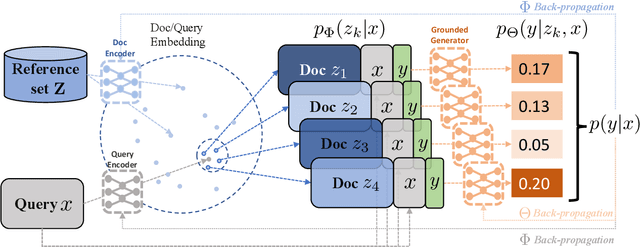

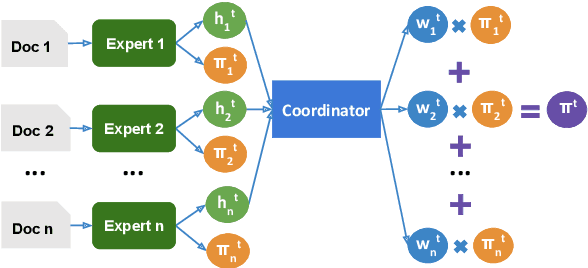
Recent advances in large-scale pre-training such as GPT-3 allow seemingly high quality text to be generated from a given prompt. However, such generation systems often suffer from problems of hallucinated facts, and are not inherently designed to incorporate useful external information. Grounded generation models appear to offer remedies, but their training typically relies on rarely-available parallel data where corresponding information-relevant documents are provided for context. We propose a framework that alleviates this data constraint by jointly training a grounded generator and document retriever on the language model signal. The model learns to reward retrieval of the documents with the highest utility in generation, and attentively combines them using a Mixture-of-Experts (MoE) ensemble to generate follow-on text. We demonstrate that both generator and retriever can take advantage of this joint training and work synergistically to produce more informative and relevant text in both prose and dialogue generation.
A Token-level Reference-free Hallucination Detection Benchmark for Free-form Text Generation
Apr 18, 2021
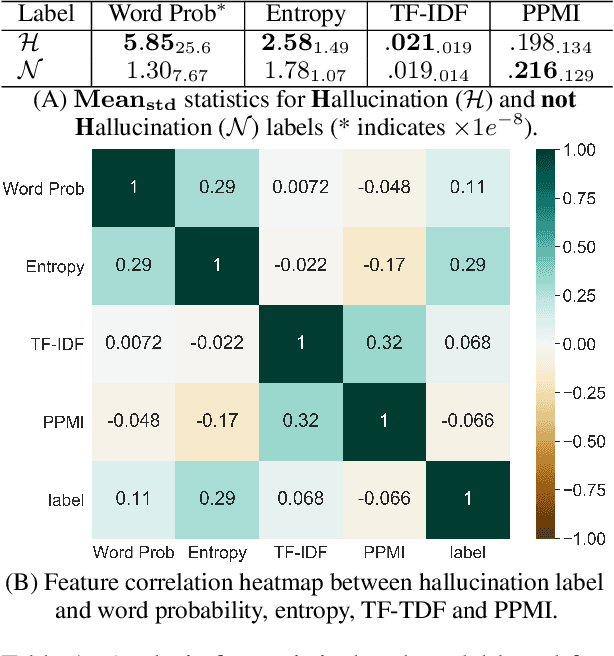

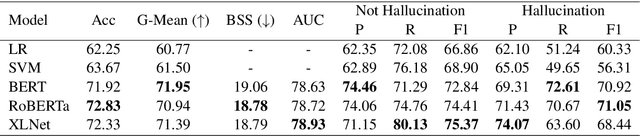
Large pretrained generative models like GPT-3 often suffer from hallucinating non-existent or incorrect content, which undermines their potential merits in real applications. Existing work usually attempts to detect these hallucinations based on a corresponding oracle reference at a sentence or document level. However ground-truth references may not be readily available for many free-form text generation applications, and sentence- or document-level detection may fail to provide the fine-grained signals that would prevent fallacious content in real time. As a first step to addressing these issues, we propose a novel token-level, reference-free hallucination detection task and an associated annotated dataset named HaDes (HAllucination DEtection dataSet). To create this dataset, we first perturb a large number of text segments extracted from English language Wikipedia, and then verify these with crowd-sourced annotations. To mitigate label imbalance during annotation, we utilize an iterative model-in-loop strategy. We conduct comprehensive data analyses and create multiple baseline models.
Text Editing by Command
Oct 24, 2020
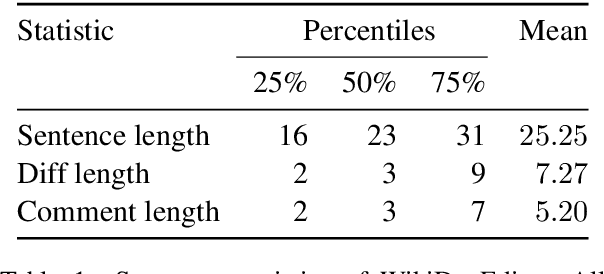
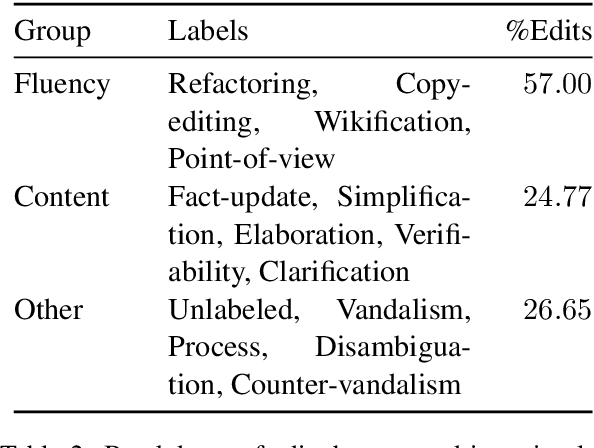
A prevailing paradigm in neural text generation is one-shot generation, where text is produced in a single step. The one-shot setting is inadequate, however, when the constraints the user wishes to impose on the generated text are dynamic, especially when authoring longer documents. We address this limitation with an interactive text generation setting in which the user interacts with the system by issuing commands to edit existing text. To this end, we propose a novel text editing task, and introduce WikiDocEdits, a dataset of single-sentence edits crawled from Wikipedia. We show that our Interactive Editor, a transformer-based model trained on this dataset, outperforms baselines and obtains positive results in both automatic and human evaluations. We present empirical and qualitative analyses of this model's performance.
Contextualized Perturbation for Textual Adversarial Attack
Sep 16, 2020
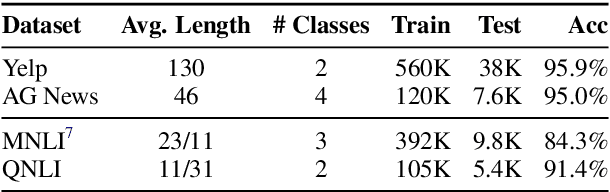
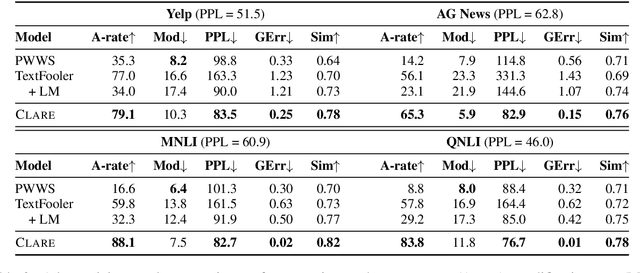
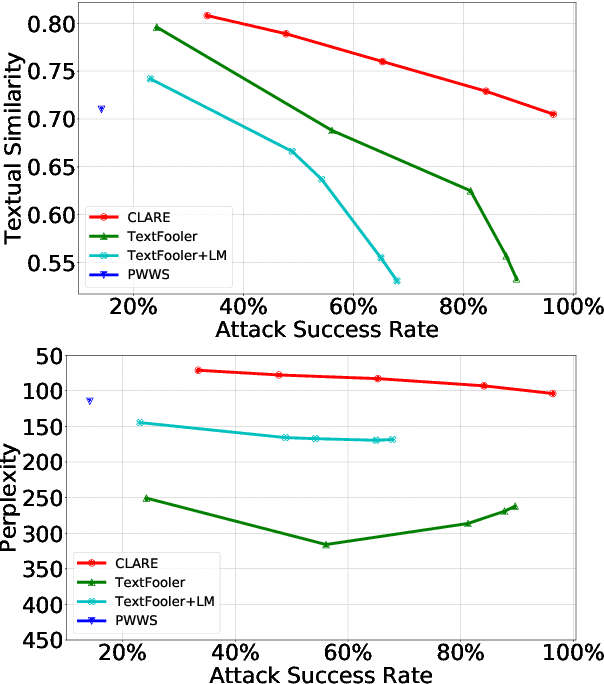
Adversarial examples expose the vulnerabilities of natural language processing (NLP) models, and can be used to evaluate and improve their robustness. Existing techniques of generating such examples are typically driven by local heuristic rules that are agnostic to the context, often resulting in unnatural and ungrammatical outputs. This paper presents CLARE, a ContextuaLized AdversaRial Example generation model that produces fluent and grammatical outputs through a mask-then-infill procedure. CLARE builds on a pre-trained masked language model and modifies the inputs in a context-aware manner. We propose three contextualized perturbations, Replace, Insert and Merge, allowing for generating outputs of varied lengths. With a richer range of available strategies, CLARE is able to attack a victim model more efficiently with fewer edits. Extensive experiments and human evaluation demonstrate that CLARE outperforms the baselines in terms of attack success rate, textual similarity, fluency and grammaticality.
Dialogue Response Ranking Training with Large-Scale Human Feedback Data
Sep 15, 2020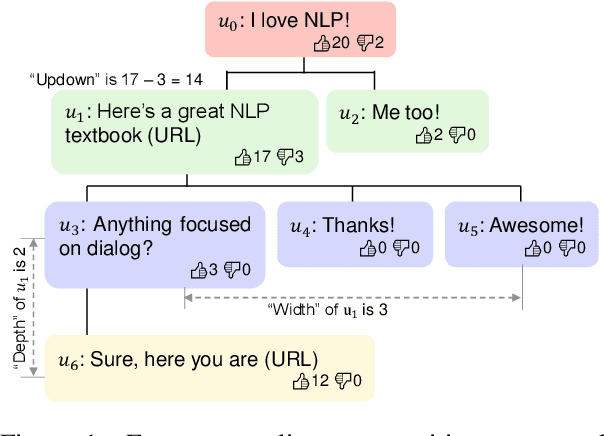
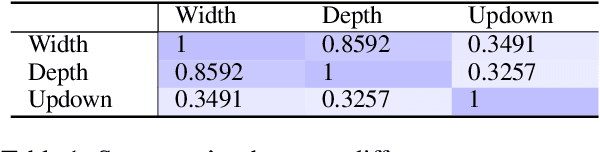
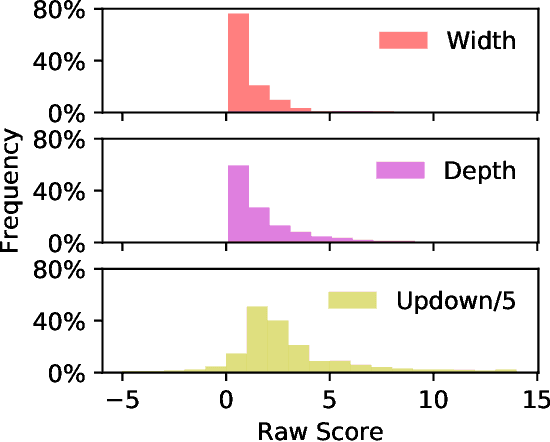
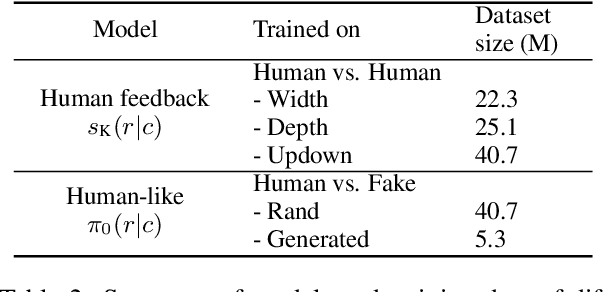
Existing open-domain dialog models are generally trained to minimize the perplexity of target human responses. However, some human replies are more engaging than others, spawning more followup interactions. Current conversational models are increasingly capable of producing turns that are context-relevant, but in order to produce compelling agents, these models need to be able to predict and optimize for turns that are genuinely engaging. We leverage social media feedback data (number of replies and upvotes) to build a large-scale training dataset for feedback prediction. To alleviate possible distortion between the feedback and engagingness, we convert the ranking problem to a comparison of response pairs which involve few confounding factors. We trained DialogRPT, a set of GPT-2 based models on 133M pairs of human feedback data and the resulting ranker outperformed several baselines. Particularly, our ranker outperforms the conventional dialog perplexity baseline with a large margin on predicting Reddit feedback. We finally combine the feedback prediction models and a human-like scoring model to rank the machine-generated dialog responses. Crowd-sourced human evaluation shows that our ranking method correlates better with real human preferences than baseline models.
A Recipe for Creating Multimodal Aligned Datasets for Sequential Tasks
May 19, 2020
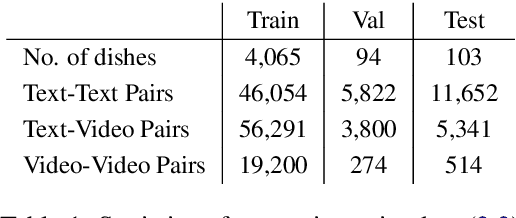
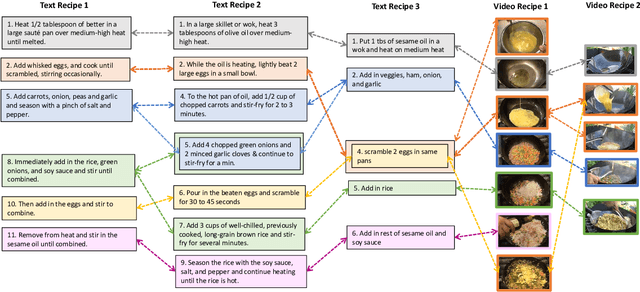
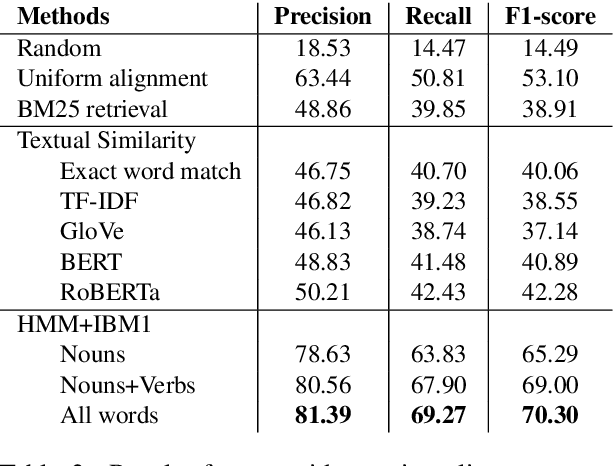
Many high-level procedural tasks can be decomposed into sequences of instructions that vary in their order and choice of tools. In the cooking domain, the web offers many partially-overlapping text and video recipes (i.e. procedures) that describe how to make the same dish (i.e. high-level task). Aligning instructions for the same dish across different sources can yield descriptive visual explanations that are far richer semantically than conventional textual instructions, providing commonsense insight into how real-world procedures are structured. Learning to align these different instruction sets is challenging because: a) different recipes vary in their order of instructions and use of ingredients; and b) video instructions can be noisy and tend to contain far more information than text instructions. To address these challenges, we first use an unsupervised alignment algorithm that learns pairwise alignments between instructions of different recipes for the same dish. We then use a graph algorithm to derive a joint alignment between multiple text and multiple video recipes for the same dish. We release the Microsoft Research Multimodal Aligned Recipe Corpus containing 150K pairwise alignments between recipes across 4,262 dishes with rich commonsense information.
* This paper has been accepted to be published at ACL 2020