 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChristopher A. George
Applying the Decisiveness and Robustness Metrics to Convolutional Neural Networks
May 29, 2020

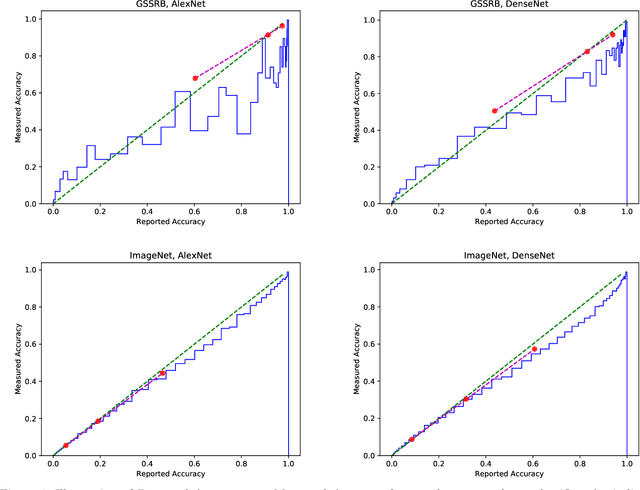
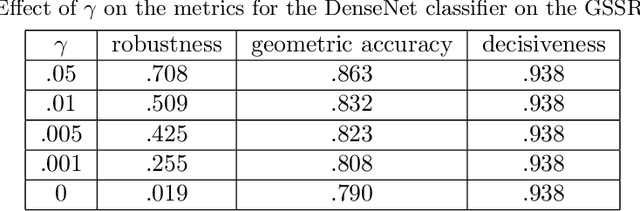
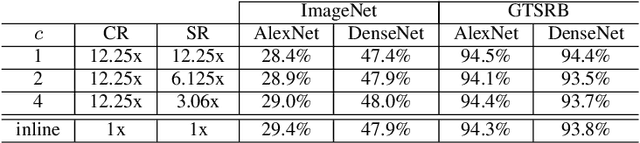
We review three recently-proposed classifier quality metrics and consider their suitability for large-scale classification challenges such as applying convolutional neural networks to the 1000-class ImageNet dataset. These metrics, referred to as the "geometric accuracy," "decisiveness," and "robustness," are based on the generalized mean ($\rho$ equals 0, 1, and -2/3, respectively) of the classifier's self-reported and measured probabilities of correct classification. We also propose some minor clarifications to standardize the metric definitions. With these updates, we show some examples of calculating the metrics using deep convolutional neural networks (AlexNet and DenseNet) acting on large datasets (the German Traffic Sign Recognition Benchmark and ImageNet).
Localized Compression: Applying Convolutional Neural Networks to Compressed Images
Nov 20, 2019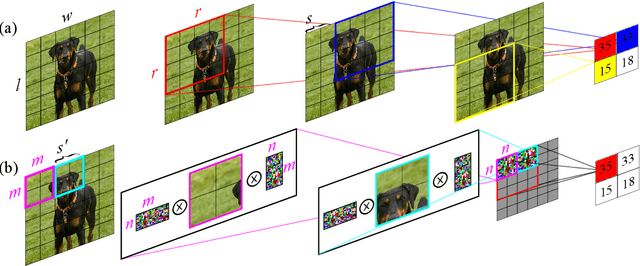
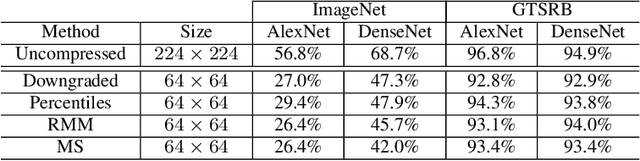
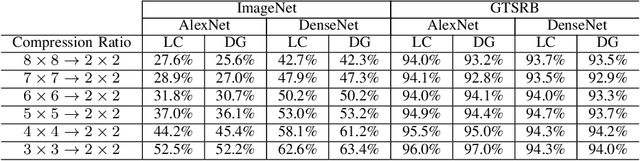
We address the challenge of applying existing convolutional neural network (CNN) architectures to compressed images. Existing CNN architectures represent images as a matrix of pixel intensities with a specified dimension; this desired dimension is achieved by downgrading or cropping. Downgrading and cropping are attractive in that the result is also an image; however, an algorithm producing an alternative "compressed" representation could yield better classification performance. This compression algorithm need not be reversible, but must be compatible with the CNN's operations. This problem is thus the counterpart of the well-studied problem of applying compressed CNNs to uncompressed images, which has attracted great interest as CNNs are deployed to size-, weight-, and power- (SWaP)-limited devices. We introduce Localized Compression, a generalization of downgrading in which the original image is divided into blocks and each block is compressed to a smaller size using either sampling- or random-matrix-based techniques. By aligning the size of the compressed blocks with the size of the CNN's convolutional region, localized compression can be made compatible with any CNN architecture. Our experimental results show that Localized Compression results in classification accuracy approximately 1-2% higher than is achieved by downgrading to the equivalent resolution.
Context Exploitation using Hierarchical Bayesian Models
May 30, 2018
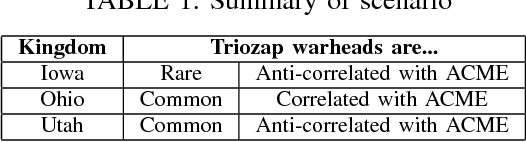
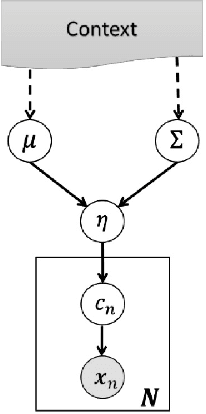

We consider the problem of how to improve automatic target recognition by fusing the naive sensor-level classification decisions with "intuition," or context, in a mathematically principled way. This is a general approach that is compatible with many definitions of context, but for specificity, we consider context as co-occurrence in imagery. In particular, we consider images that contain multiple objects identified at various confidence levels. We learn the patterns of co-occurrence in each context, then use these patterns as hyper-parameters for a Hierarchical Bayesian Model. The result is that low-confidence sensor classification decisions can be dramatically improved by fusing those readings with context. We further use hyperpriors to address the case where multiple contexts may be appropriate. We also consider the Bayesian Network, an alternative to the Hierarchical Bayesian Model, which is computationally more efficient but assumes that context and sensor readings are uncorrelated.
* 4 pages; 3 figures; 5 tables