 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChristopher Stewart
A Case for Dataset Specific Profiling
Aug 01, 2022
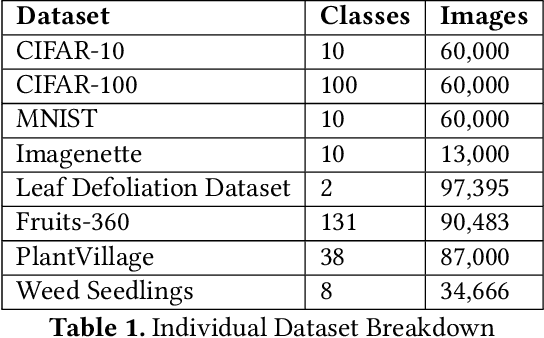
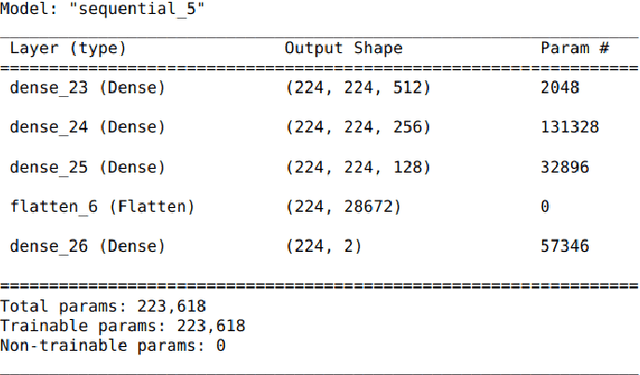
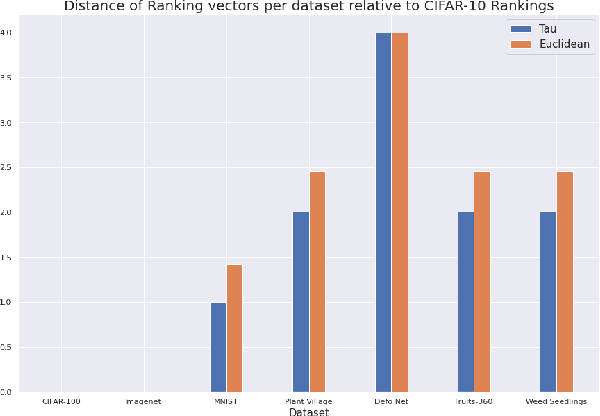
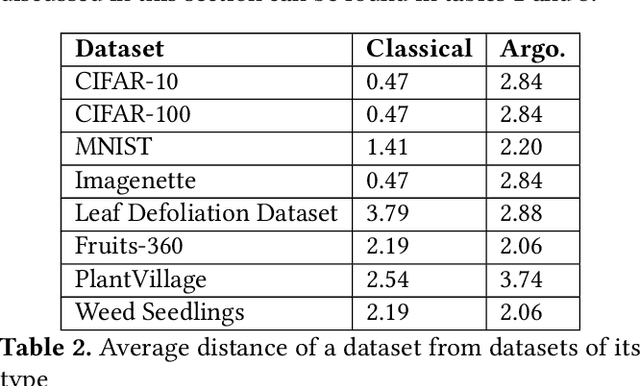
Data-driven science is an emerging paradigm where scientific discoveries depend on the execution of computational AI models against rich, discipline-specific datasets. With modern machine learning frameworks, anyone can develop and execute computational models that reveal concepts hidden in the data that could enable scientific applications. For important and widely used datasets, computing the performance of every computational model that can run against a dataset is cost prohibitive in terms of cloud resources. Benchmarking approaches used in practice use representative datasets to infer performance without actually executing models. While practicable, these approaches limit extensive dataset profiling to a few datasets and introduce bias that favors models suited for representative datasets. As a result, each dataset's unique characteristics are left unexplored and subpar models are selected based on inference from generalized datasets. This necessitates a new paradigm that introduces dataset profiling into the model selection process. To demonstrate the need for dataset-specific profiling, we answer two questions:(1) Can scientific datasets significantly permute the rank order of computational models compared to widely used representative datasets? (2) If so, could lightweight model execution improve benchmarking accuracy? Taken together, the answers to these questions lay the foundation for a new dataset-aware benchmarking paradigm.
Topic words analysis based on LDA model
May 15, 2014
Social network analysis (SNA), which is a research field describing and modeling the social connection of a certain group of people, is popular among network services. Our topic words analysis project is a SNA method to visualize the topic words among emails from Obama.com to accounts registered in Columbus, Ohio. Based on Latent Dirichlet Allocation (LDA) model, a popular topic model of SNA, our project characterizes the preference of senders for target group of receptors. Gibbs sampling is used to estimate topic and word distribution. Our training and testing data are emails from the carbon-free server Datagreening.com. We use parallel computing tool BashReduce for word processing and generate related words under each latent topic to discovers typical information of political news sending specially to local Columbus receptors. Running on two instances using paralleling tool BashReduce, our project contributes almost 30% speedup processing the raw contents, comparing with processing contents on one instance locally. Also, the experimental result shows that the LDA model applied in our project provides precision rate 53.96% higher than TF-IDF model finding target words, on the condition that appropriate size of topic words list is selected.