 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJohn Wu
If LLM Is the Wizard, Then Code Is the Wand: A Survey on How Code Empowers Large Language Models to Serve as Intelligent Agents
Jan 08, 2024
The prominent large language models (LLMs) of today differ from past language models not only in size, but also in the fact that they are trained on a combination of natural language and formal language (code). As a medium between humans and computers, code translates high-level goals into executable steps, featuring standard syntax, logical consistency, abstraction, and modularity. In this survey, we present an overview of the various benefits of integrating code into LLMs' training data. Specifically, beyond enhancing LLMs in code generation, we observe that these unique properties of code help (i) unlock the reasoning ability of LLMs, enabling their applications to a range of more complex natural language tasks; (ii) steer LLMs to produce structured and precise intermediate steps, which can then be connected to external execution ends through function calls; and (iii) take advantage of code compilation and execution environment, which also provides diverse feedback for model improvement. In addition, we trace how these profound capabilities of LLMs, brought by code, have led to their emergence as intelligent agents (IAs) in situations where the ability to understand instructions, decompose goals, plan and execute actions, and refine from feedback are crucial to their success on downstream tasks. Finally, we present several key challenges and future directions of empowering LLMs with code.
A Case for Dataset Specific Profiling
Aug 01, 2022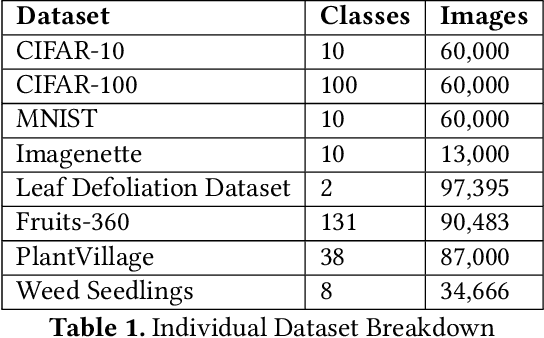
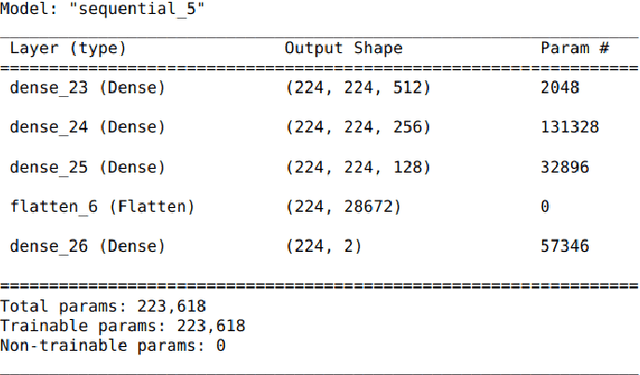
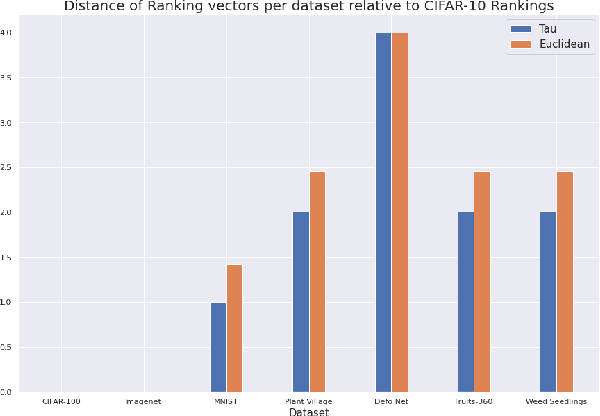
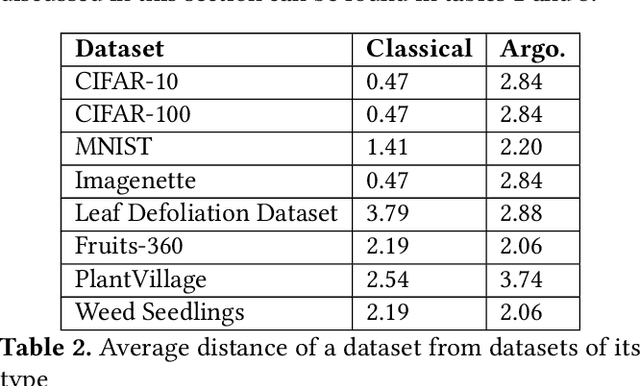
Data-driven science is an emerging paradigm where scientific discoveries depend on the execution of computational AI models against rich, discipline-specific datasets. With modern machine learning frameworks, anyone can develop and execute computational models that reveal concepts hidden in the data that could enable scientific applications. For important and widely used datasets, computing the performance of every computational model that can run against a dataset is cost prohibitive in terms of cloud resources. Benchmarking approaches used in practice use representative datasets to infer performance without actually executing models. While practicable, these approaches limit extensive dataset profiling to a few datasets and introduce bias that favors models suited for representative datasets. As a result, each dataset's unique characteristics are left unexplored and subpar models are selected based on inference from generalized datasets. This necessitates a new paradigm that introduces dataset profiling into the model selection process. To demonstrate the need for dataset-specific profiling, we answer two questions:(1) Can scientific datasets significantly permute the rank order of computational models compared to widely used representative datasets? (2) If so, could lightweight model execution improve benchmarking accuracy? Taken together, the answers to these questions lay the foundation for a new dataset-aware benchmarking paradigm.