 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChuangtao Chen
Quantum Mixed-State Self-Attention Network
Mar 05, 2024
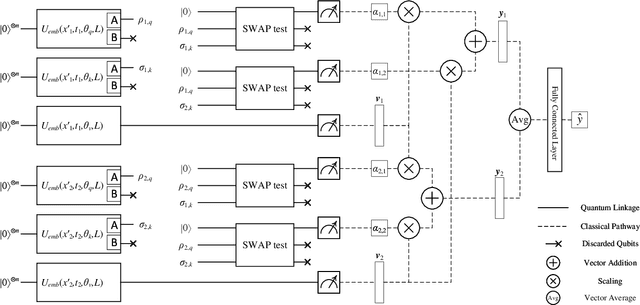
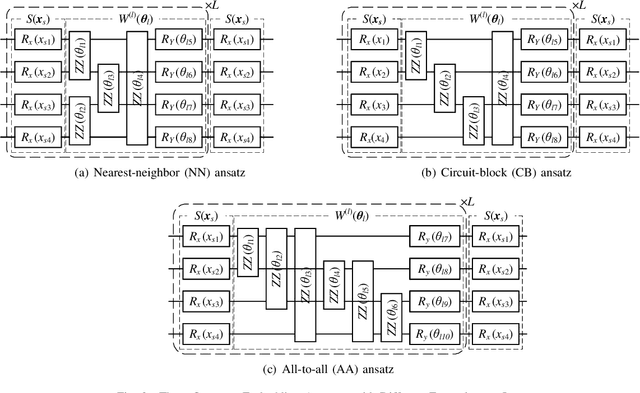
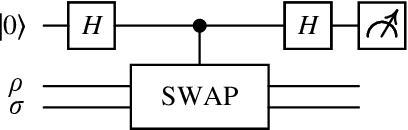
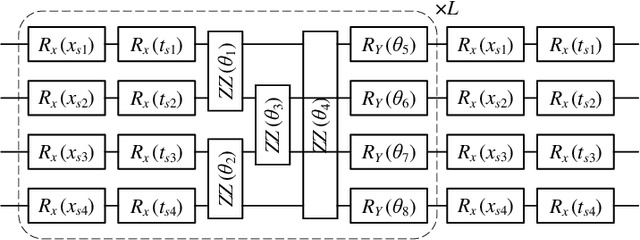
The rapid advancement of quantum computing has increasingly highlighted its potential in the realm of machine learning, particularly in the context of natural language processing (NLP) tasks. Quantum machine learning (QML) leverages the unique capabilities of quantum computing to offer novel perspectives and methodologies for complex data processing and pattern recognition challenges. This paper introduces a novel Quantum Mixed-State Attention Network (QMSAN), which integrates the principles of quantum computing with classical machine learning algorithms, especially self-attention networks, to enhance the efficiency and effectiveness in handling NLP tasks. QMSAN model employs a quantum attention mechanism based on mixed states, enabling efficient direct estimation of similarity between queries and keys within the quantum domain, leading to more effective attention weight acquisition. Additionally, we propose an innovative quantum positional encoding scheme, implemented through fixed quantum gates within the quantum circuit, to enhance the model's accuracy. Experimental validation on various datasets demonstrates that QMSAN model outperforms existing quantum and classical models in text classification, achieving significant performance improvements. QMSAN model not only significantly reduces the number of parameters but also exceeds classical self-attention networks in performance, showcasing its strong capability in data representation and information extraction. Furthermore, our study investigates the model's robustness in different quantum noise environments, showing that QMSAN possesses commendable robustness to low noise.
Quantum Generative Diffusion Model
Jan 13, 2024This paper introduces the Quantum Generative Diffusion Model (QGDM), a fully quantum-mechanical model for generating quantum state ensembles, inspired by Denoising Diffusion Probabilistic Models. QGDM features a diffusion process that introduces timestep-dependent noise into quantum states, paired with a denoising mechanism trained to reverse this contamination. This model efficiently evolves a completely mixed state into a target quantum state post-training. Our comparative analysis with Quantum Generative Adversarial Networks demonstrates QGDM's superiority, with fidelity metrics exceeding 0.99 in numerical simulations involving up to 4 qubits. Additionally, we present a Resource-Efficient version of QGDM (RE-QGDM), which minimizes the need for auxiliary qubits while maintaining impressive generative capabilities for tasks involving up to 8 qubits. These results showcase the proposed models' potential for tackling challenging quantum generation problems.
Expressivity Enhancement with Efficient Quadratic Neurons for Convolutional Neural Networks
Jun 10, 2023



Convolutional neural networks (CNNs) have been successfully applied in a range of fields such as image classification and object segmentation. To improve their expressivity, various techniques, such as novel CNN architectures, have been explored. However, the performance gain from such techniques tends to diminish. To address this challenge, many researchers have shifted their focus to increasing the non-linearity of neurons, the fundamental building blocks of neural networks, to enhance the network expressivity. Nevertheless, most of these approaches incur a large number of parameters and thus formidable computation cost inevitably, impairing their efficiency to be deployed in practice. In this work, an efficient quadratic neuron structure is proposed to preserve the non-linearity with only negligible parameter and computation cost overhead. The proposed quadratic neuron can maximize the utilization of second-order computation information to improve the network performance. The experimental results have demonstrated that the proposed quadratic neuron can achieve a higher accuracy and a better computation efficiency in classification tasks compared with both linear neurons and non-linear neurons from previous works.