 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChun-Hao Paul Huang
ActAnywhere: Subject-Aware Video Background Generation
Jan 19, 2024
Generating video background that tailors to foreground subject motion is an important problem for the movie industry and visual effects community. This task involves synthesizing background that aligns with the motion and appearance of the foreground subject, while also complies with the artist's creative intention. We introduce ActAnywhere, a generative model that automates this process which traditionally requires tedious manual efforts. Our model leverages the power of large-scale video diffusion models, and is specifically tailored for this task. ActAnywhere takes a sequence of foreground subject segmentation as input and an image that describes the desired scene as condition, to produce a coherent video with realistic foreground-background interactions while adhering to the condition frame. We train our model on a large-scale dataset of human-scene interaction videos. Extensive evaluations demonstrate the superior performance of our model, significantly outperforming baselines. Moreover, we show that ActAnywhere generalizes to diverse out-of-distribution samples, including non-human subjects. Please visit our project webpage at https://actanywhere.github.io.
Generative Rendering: Controllable 4D-Guided Video Generation with 2D Diffusion Models
Dec 03, 2023Traditional 3D content creation tools empower users to bring their imagination to life by giving them direct control over a scene's geometry, appearance, motion, and camera path. Creating computer-generated videos, however, is a tedious manual process, which can be automated by emerging text-to-video diffusion models. Despite great promise, video diffusion models are difficult to control, hindering a user to apply their own creativity rather than amplifying it. To address this challenge, we present a novel approach that combines the controllability of dynamic 3D meshes with the expressivity and editability of emerging diffusion models. For this purpose, our approach takes an animated, low-fidelity rendered mesh as input and injects the ground truth correspondence information obtained from the dynamic mesh into various stages of a pre-trained text-to-image generation model to output high-quality and temporally consistent frames. We demonstrate our approach on various examples where motion can be obtained by animating rigged assets or changing the camera path.
BLiSS: Bootstrapped Linear Shape Space
Sep 04, 2023Morphable models are fundamental to numerous human-centered processes as they offer a simple yet expressive shape space. Creating such morphable models, however, is both tedious and expensive. The main challenge is establishing dense correspondences across raw scans that capture sufficient shape variation. This is often addressed using a mix of significant manual intervention and non-rigid registration. We observe that creating a shape space and solving for dense correspondence are tightly coupled -- while dense correspondence is needed to build shape spaces, an expressive shape space provides a reduced dimensional space to regularize the search. We introduce BLiSS, a method to solve both progressively. Starting from a small set of manually registered scans to bootstrap the process, we enrich the shape space and then use that to get new unregistered scans into correspondence automatically. The critical component of BLiSS is a non-linear deformation model that captures details missed by the low-dimensional shape space, thus allowing progressive enrichment of the space.
Pix2Video: Video Editing using Image Diffusion
Mar 22, 2023

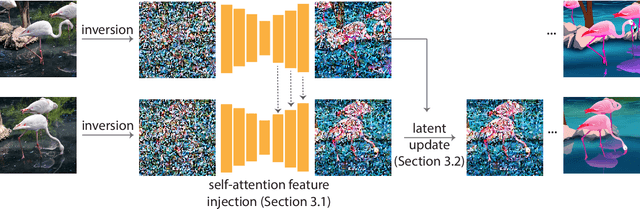
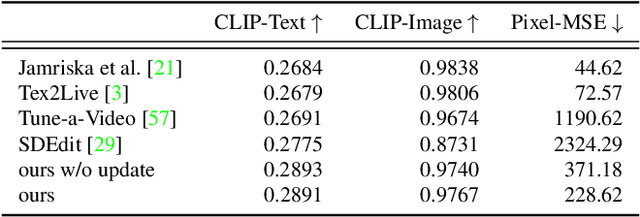
Image diffusion models, trained on massive image collections, have emerged as the most versatile image generator model in terms of quality and diversity. They support inverting real images and conditional (e.g., text) generation, making them attractive for high-quality image editing applications. We investigate how to use such pre-trained image models for text-guided video editing. The critical challenge is to achieve the target edits while still preserving the content of the source video. Our method works in two simple steps: first, we use a pre-trained structure-guided (e.g., depth) image diffusion model to perform text-guided edits on an anchor frame; then, in the key step, we progressively propagate the changes to the future frames via self-attention feature injection to adapt the core denoising step of the diffusion model. We then consolidate the changes by adjusting the latent code for the frame before continuing the process. Our approach is training-free and generalizes to a wide range of edits. We demonstrate the effectiveness of the approach by extensive experimentation and compare it against four different prior and parallel efforts (on ArXiv). We demonstrate that realistic text-guided video edits are possible, without any compute-intensive preprocessing or video-specific finetuning.
Blowing in the Wind: CycleNet for Human Cinemagraphs from Still Images
Mar 15, 2023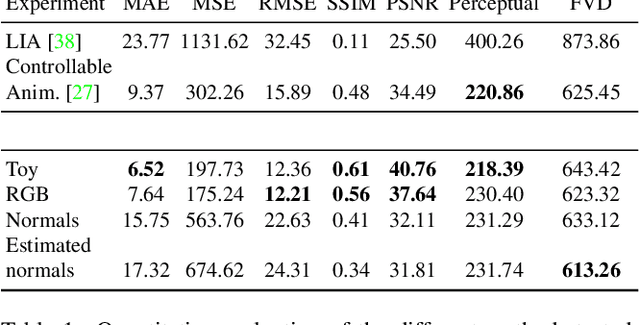
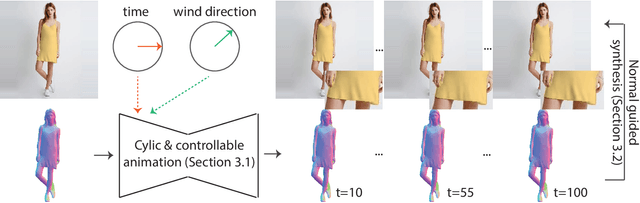
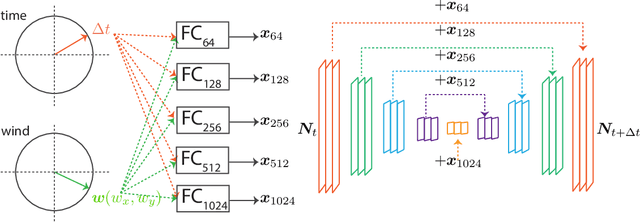

Cinemagraphs are short looping videos created by adding subtle motions to a static image. This kind of media is popular and engaging. However, automatic generation of cinemagraphs is an underexplored area and current solutions require tedious low-level manual authoring by artists. In this paper, we present an automatic method that allows generating human cinemagraphs from single RGB images. We investigate the problem in the context of dressed humans under the wind. At the core of our method is a novel cyclic neural network that produces looping cinemagraphs for the target loop duration. To circumvent the problem of collecting real data, we demonstrate that it is possible, by working in the image normal space, to learn garment motion dynamics on synthetic data and generalize to real data. We evaluate our method on both synthetic and real data and demonstrate that it is possible to create compelling and plausible cinemagraphs from single RGB images.