 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDaniel Justus
BESS: Balanced Entity Sampling and Sharing for Large-Scale Knowledge Graph Completion
Nov 22, 2022

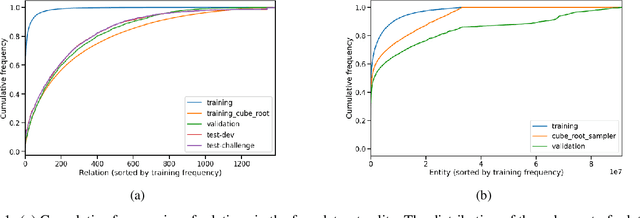

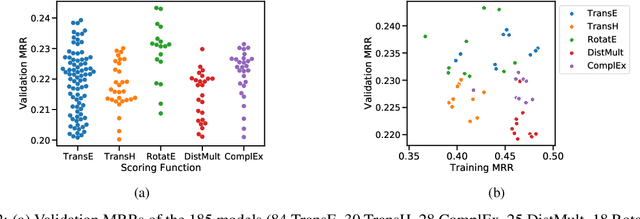
We present the award-winning submission to the WikiKG90Mv2 track of OGB-LSC@NeurIPS 2022. The task is link-prediction on the large-scale knowledge graph WikiKG90Mv2, consisting of 90M+ nodes and 600M+ edges. Our solution uses a diverse ensemble of $85$ Knowledge Graph Embedding models combining five different scoring functions (TransE, TransH, RotatE, DistMult, ComplEx) and two different loss functions (log-sigmoid, sampled softmax cross-entropy). Each individual model is trained in parallel on a Graphcore Bow Pod$_{16}$ using BESS (Balanced Entity Sampling and Sharing), a new distribution framework for KGE training and inference based on balanced collective communications between workers. Our final model achieves a validation MRR of 0.2922 and a test-challenge MRR of 0.2562, winning the first place in the competition. The code is publicly available at: https://github.com/graphcore/distributed-kge-poplar/tree/2022-ogb-submission.
8-bit Numerical Formats for Deep Neural Networks
Jun 06, 2022



Given the current trend of increasing size and complexity of machine learning architectures, it has become of critical importance to identify new approaches to improve the computational efficiency of model training. In this context, we address the advantages of floating-point over fixed-point representation, and present an in-depth study on the use of 8-bit floating-point number formats for activations, weights, and gradients for both training and inference. We explore the effect of different bit-widths for exponents and significands and different exponent biases. The experimental results demonstrate that a suitable choice of these low-precision formats enables faster training and reduced power consumption without any degradation in accuracy for a range of deep learning models for image classification and language processing.
Towards Structured Dynamic Sparse Pre-Training of BERT
Aug 13, 2021



Identifying algorithms for computational efficient unsupervised training of large language models is an important and active area of research. In this work, we develop and study a straightforward, dynamic always-sparse pre-training approach for BERT language modeling task, which leverages periodic compression steps based on magnitude pruning followed by random parameter re-allocation. This approach enables us to achieve Pareto improvements in terms of the number of floating-point operations (FLOPs) over statically sparse and dense models across a broad spectrum of network sizes. Furthermore, we demonstrate that training remains FLOP-efficient when using coarse-grained block sparsity, making it particularly promising for efficient execution on modern hardware accelerators.
GroupBERT: Enhanced Transformer Architecture with Efficient Grouped Structures
Jun 10, 2021



Attention based language models have become a critical component in state-of-the-art natural language processing systems. However, these models have significant computational requirements, due to long training times, dense operations and large parameter count. In this work we demonstrate a set of modifications to the structure of a Transformer layer, producing a more efficient architecture. First, we add a convolutional module to complement the self-attention module, decoupling the learning of local and global interactions. Secondly, we rely on grouped transformations to reduce the computational cost of dense feed-forward layers and convolutions, while preserving the expressivity of the model. We apply the resulting architecture to language representation learning and demonstrate its superior performance compared to BERT models of different scales. We further highlight its improved efficiency, both in terms of floating-point operations (FLOPs) and time-to-train.
Predicting the Computational Cost of Deep Learning Models
Nov 28, 2018



Deep learning is rapidly becoming a go-to tool for many artificial intelligence problems due to its ability to outperform other approaches and even humans at many problems. Despite its popularity we are still unable to accurately predict the time it will take to train a deep learning network to solve a given problem. This training time can be seen as the product of the training time per epoch and the number of epochs which need to be performed to reach the desired level of accuracy. Some work has been carried out to predict the training time for an epoch -- most have been based around the assumption that the training time is linearly related to the number of floating point operations required. However, this relationship is not true and becomes exacerbated in cases where other activities start to dominate the execution time. Such as the time to load data from memory or loss of performance due to non-optimal parallel execution. In this work we propose an alternative approach in which we train a deep learning network to predict the execution time for parts of a deep learning network. Timings for these individual parts can then be combined to provide a prediction for the whole execution time. This has advantages over linear approaches as it can model more complex scenarios. But, also, it has the ability to predict execution times for scenarios unseen in the training data. Therefore, our approach can be used not only to infer the execution time for a batch, or entire epoch, but it can also support making a well-informed choice for the appropriate hardware and model.