 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDavid Held
Learning Distributional Demonstration Spaces for Task-Specific Cross-Pose Estimation
May 07, 2024
Relative placement tasks are an important category of tasks in which one object needs to be placed in a desired pose relative to another object. Previous work has shown success in learning relative placement tasks from just a small number of demonstrations when using relational reasoning networks with geometric inductive biases. However, such methods cannot flexibly represent multimodal tasks, like a mug hanging on any of n racks. We propose a method that incorporates additional properties that enable learning multimodal relative placement solutions, while retaining the provably translation-invariant and relational properties of prior work. We show that our method is able to learn precise relative placement tasks with only 10-20 multimodal demonstrations with no human annotations across a diverse set of objects within a category.
Deep SE(3)-Equivariant Geometric Reasoning for Precise Placement Tasks
Apr 20, 2024Many robot manipulation tasks can be framed as geometric reasoning tasks, where an agent must be able to precisely manipulate an object into a position that satisfies the task from a set of initial conditions. Often, task success is defined based on the relationship between two objects - for instance, hanging a mug on a rack. In such cases, the solution should be equivariant to the initial position of the objects as well as the agent, and invariant to the pose of the camera. This poses a challenge for learning systems which attempt to solve this task by learning directly from high-dimensional demonstrations: the agent must learn to be both equivariant as well as precise, which can be challenging without any inductive biases about the problem. In this work, we propose a method for precise relative pose prediction which is provably SE(3)-equivariant, can be learned from only a few demonstrations, and can generalize across variations in a class of objects. We accomplish this by factoring the problem into learning an SE(3) invariant task-specific representation of the scene and then interpreting this representation with novel geometric reasoning layers which are provably SE(3) equivariant. We demonstrate that our method can yield substantially more precise placement predictions in simulated placement tasks than previous methods trained with the same amount of data, and can accurately represent relative placement relationships data collected from real-world demonstrations. Supplementary information and videos can be found at https://sites.google.com/view/reldist-iclr-2023.
RL-VLM-F: Reinforcement Learning from Vision Language Foundation Model Feedback
Feb 10, 2024Reward engineering has long been a challenge in Reinforcement Learning (RL) research, as it often requires extensive human effort and iterative processes of trial-and-error to design effective reward functions. In this paper, we propose RL-VLM-F, a method that automatically generates reward functions for agents to learn new tasks, using only a text description of the task goal and the agent's visual observations, by leveraging feedbacks from vision language foundation models (VLMs). The key to our approach is to query these models to give preferences over pairs of the agent's image observations based on the text description of the task goal, and then learn a reward function from the preference labels, rather than directly prompting these models to output a raw reward score, which can be noisy and inconsistent. We demonstrate that RL-VLM-F successfully produces effective rewards and policies across various domains - including classic control, as well as manipulation of rigid, articulated, and deformable objects - without the need for human supervision, outperforming prior methods that use large pretrained models for reward generation under the same assumptions.
DiffTOP: Differentiable Trajectory Optimization for Deep Reinforcement and Imitation Learning
Feb 08, 2024This paper introduces DiffTOP, which utilizes Differentiable Trajectory OPtimization as the policy representation to generate actions for deep reinforcement and imitation learning. Trajectory optimization is a powerful and widely used algorithm in control, parameterized by a cost and a dynamics function. The key to our approach is to leverage the recent progress in differentiable trajectory optimization, which enables computing the gradients of the loss with respect to the parameters of trajectory optimization. As a result, the cost and dynamics functions of trajectory optimization can be learned end-to-end. DiffTOP addresses the ``objective mismatch'' issue of prior model-based RL algorithms, as the dynamics model in DiffTOP is learned to directly maximize task performance by differentiating the policy gradient loss through the trajectory optimization process. We further benchmark DiffTOP for imitation learning on standard robotic manipulation task suites with high-dimensional sensory observations and compare our method to feed-forward policy classes as well as Energy-Based Models (EBM) and Diffusion. Across 15 model-based RL tasks and 13 imitation learning tasks with high-dimensional image and point cloud inputs, DiffTOP outperforms prior state-of-the-art methods in both domains.
On Time-Indexing as Inductive Bias in Deep RL for Sequential Manipulation Tasks
Jan 03, 2024While solving complex manipulation tasks, manipulation policies often need to learn a set of diverse skills to accomplish these tasks. The set of skills is often quite multimodal - each one may have a quite distinct distribution of actions and states. Standard deep policy-learning algorithms often model policies as deep neural networks with a single output head (deterministic or stochastic). This structure requires the network to learn to switch between modes internally, which can lead to lower sample efficiency and poor performance. In this paper we explore a simple structure which is conducive to skill learning required for so many of the manipulation tasks. Specifically, we propose a policy architecture that sequentially executes different action heads for fixed durations, enabling the learning of primitive skills such as reaching and grasping. Our empirical evaluation on the Metaworld tasks reveals that this simple structure outperforms standard policy learning methods, highlighting its potential for improved skill acquisition.
Object Importance Estimation using Counterfactual Reasoning for Intelligent Driving
Dec 05, 2023The ability to identify important objects in a complex and dynamic driving environment is essential for autonomous driving agents to make safe and efficient driving decisions. It also helps assistive driving systems decide when to alert drivers. We tackle object importance estimation in a data-driven fashion and introduce HOIST - Human-annotated Object Importance in Simulated Traffic. HOIST contains driving scenarios with human-annotated importance labels for vehicles and pedestrians. We additionally propose a novel approach that relies on counterfactual reasoning to estimate an object's importance. We generate counterfactual scenarios by modifying the motion of objects and ascribe importance based on how the modifications affect the ego vehicle's driving. Our approach outperforms strong baselines for the task of object importance estimation on HOIST. We also perform ablation studies to justify our design choices and show the significance of the different components of our proposed approach.
RoboGen: Towards Unleashing Infinite Data for Automated Robot Learning via Generative Simulation
Nov 13, 2023We present RoboGen, a generative robotic agent that automatically learns diverse robotic skills at scale via generative simulation. RoboGen leverages the latest advancements in foundation and generative models. Instead of directly using or adapting these models to produce policies or low-level actions, we advocate for a generative scheme, which uses these models to automatically generate diversified tasks, scenes, and training supervisions, thereby scaling up robotic skill learning with minimal human supervision. Our approach equips a robotic agent with a self-guided propose-generate-learn cycle: the agent first proposes interesting tasks and skills to develop, and then generates corresponding simulation environments by populating pertinent objects and assets with proper spatial configurations. Afterwards, the agent decomposes the proposed high-level task into sub-tasks, selects the optimal learning approach (reinforcement learning, motion planning, or trajectory optimization), generates required training supervision, and then learns policies to acquire the proposed skill. Our work attempts to extract the extensive and versatile knowledge embedded in large-scale models and transfer them to the field of robotics. Our fully generative pipeline can be queried repeatedly, producing an endless stream of skill demonstrations associated with diverse tasks and environments.
Force-Constrained Visual Policy: Safe Robot-Assisted Dressing via Multi-Modal Sensing
Nov 07, 2023Robot-assisted dressing could profoundly enhance the quality of life of adults with physical disabilities. To achieve this, a robot can benefit from both visual and force sensing. The former enables the robot to ascertain human body pose and garment deformations, while the latter helps maintain safety and comfort during the dressing process. In this paper, we introduce a new technique that leverages both vision and force modalities for this assistive task. Our approach first trains a vision-based dressing policy using reinforcement learning in simulation with varying body sizes, poses, and types of garments. We then learn a force dynamics model for action planning to ensure safety. Due to limitations of simulating accurate force data when deformable garments interact with the human body, we learn a force dynamics model directly from real-world data. Our proposed method combines the vision-based policy, trained in simulation, with the force dynamics model, learned in the real world, by solving a constrained optimization problem to infer actions that facilitate the dressing process without applying excessive force on the person. We evaluate our system in simulation and in a real-world human study with 10 participants across 240 dressing trials, showing it greatly outperforms prior baselines. Video demonstrations are available on our project website\footnote{\url{https://sites.google.com/view/dressing-fcvp}}.
Reinforcement Learning in a Safety-Embedded MDP with Trajectory Optimization
Oct 10, 2023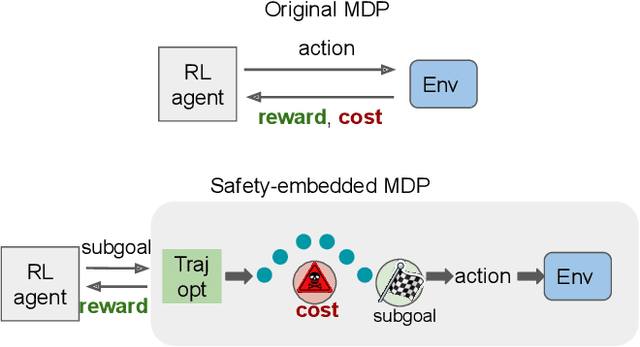
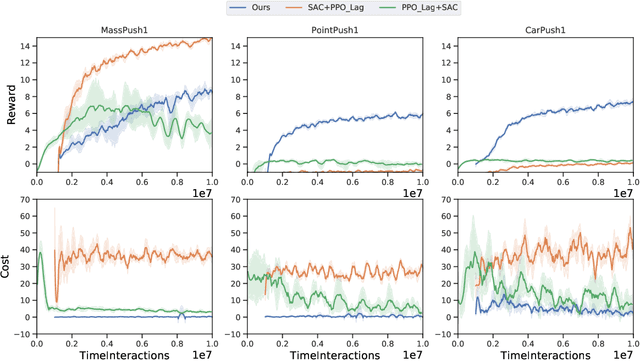
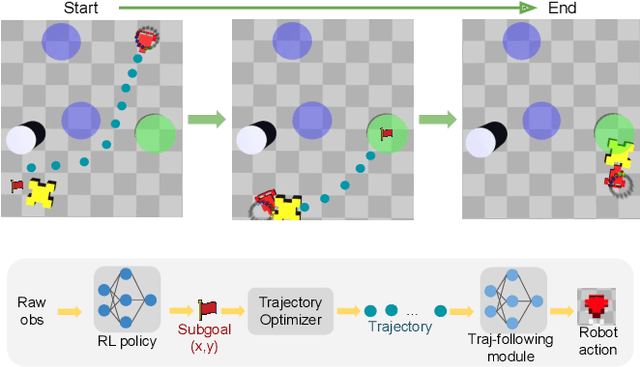
Safe Reinforcement Learning (RL) plays an important role in applying RL algorithms to safety-critical real-world applications, addressing the trade-off between maximizing rewards and adhering to safety constraints. This work introduces a novel approach that combines RL with trajectory optimization to manage this trade-off effectively. Our approach embeds safety constraints within the action space of a modified Markov Decision Process (MDP). The RL agent produces a sequence of actions that are transformed into safe trajectories by a trajectory optimizer, thereby effectively ensuring safety and increasing training stability. This novel approach excels in its performance on challenging Safety Gym tasks, achieving significantly higher rewards and near-zero safety violations during inference. The method's real-world applicability is demonstrated through a safe and effective deployment in a real robot task of box-pushing around obstacles.
Learning Generalizable Tool-use Skills through Trajectory Generation
Oct 06, 2023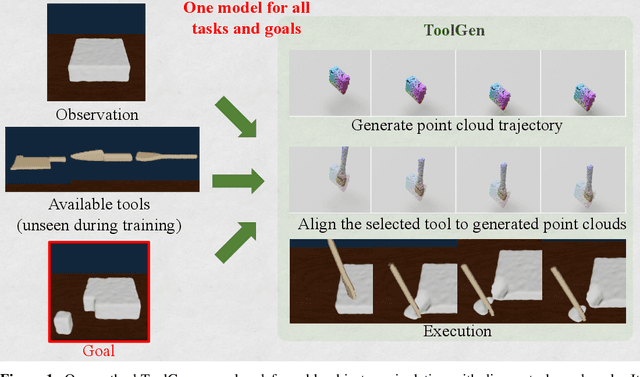



Autonomous systems that efficiently utilize tools can assist humans in completing many common tasks such as cooking and cleaning. However, current systems fall short of matching human-level of intelligence in terms of adapting to novel tools. Prior works based on affordance often make strong assumptions about the environments and cannot scale to more complex, contact-rich tasks. In this work, we tackle this challenge and explore how agents can learn to use previously unseen tools to manipulate deformable objects. We propose to learn a generative model of the tool-use trajectories as a sequence of point clouds, which generalizes to different tool shapes. Given any novel tool, we first generate a tool-use trajectory and then optimize the sequence of tool poses to align with the generated trajectory. We train a single model for four different challenging deformable object manipulation tasks. Our model is trained with demonstration data from just a single tool for each task and is able to generalize to various novel tools, significantly outperforming baselines. Additional materials can be found on our project website: https://sites.google.com/view/toolgen.