 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDawei Dai
Multi-Granularity Representation Learning for Sketch-based Dynamic Face Image Retrieval
Dec 31, 2023
In specific scenarios, face sketch can be used to identify a person. However, drawing a face sketch often requires exceptional skill and is time-consuming, limiting its widespread applications in actual scenarios. The new framework of sketch less face image retrieval (SLFIR)[1] attempts to overcome the barriers by providing a means for humans and machines to interact during the drawing process. Considering SLFIR problem, there is a large gap between a partial sketch with few strokes and any whole face photo, resulting in poor performance at the early stages. In this study, we propose a multigranularity (MG) representation learning (MGRL) method to address the SLFIR problem, in which we learn the representation of different granularity regions for a partial sketch, and then, by combining all MG regions of the sketches and images, the final distance was determined. In the experiments, our method outperformed state-of-the-art baselines in terms of early retrieval on two accessible datasets. Codes are available at https://github.com/ddw2AIGROUP2CQUPT/MGRL.
Sketch Less Face Image Retrieval: A New Challenge
Feb 11, 2023
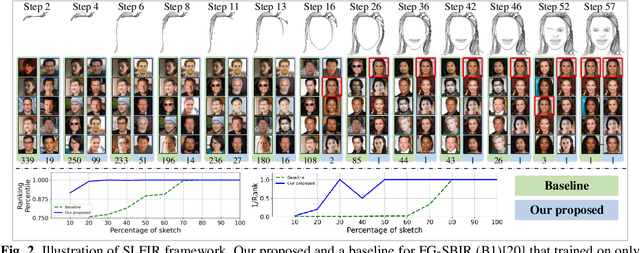
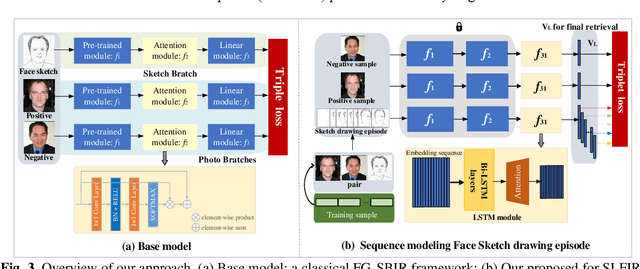
In some specific scenarios, face sketch was used to identify a person. However, drawing a complete face sketch often needs skills and takes time, which hinder its widespread applicability in the practice. In this study, we proposed a new task named sketch less face image retrieval (SLFIR), in which the retrieval was carried out at each stroke and aim to retrieve the target face photo using a partial sketch with as few strokes as possible (see Fig.1). Firstly, we developed a method to generate the data of sketch with drawing process, and opened such dataset; Secondly, we proposed a two-stage method as the baseline for SLFIR that (1) A triplet network, was first adopt to learn the joint embedding space shared between the complete sketch and its target face photo; (2) Regarding the sketch drawing episode as a sequence, we designed a LSTM module to optimize the representation of the incomplete face sketch. Experiments indicate that the new framework can finish the retrieval using a partial or pool drawing sketch.
A Study of Deep CNN Model with Labeling Noise Based on Granular-ball Computing
Jul 17, 2022


In supervised learning, the presence of noise can have a significant impact on decision making. Since many classifiers do not take label noise into account in the derivation of the loss function, including the loss functions of logistic regression, SVM, and AdaBoost, especially the AdaBoost iterative algorithm, whose core idea is to continuously increase the weight value of the misclassified samples, the weight of samples in many presence of label noise will be increased, leading to a decrease in model accuracy. In addition, the learning process of BP neural network and decision tree will also be affected by label noise. Therefore, solving the label noise problem is an important element of maintaining the robustness of the network model, which is of great practical significance. Granular ball computing is an important modeling method developed in the field of granular computing in recent years, which is an efficient, robust and scalable learning method. In this paper, we pioneered a granular ball neural network algorithm model, which adopts the idea of multi-granular to filter label noise samples during model training, solving the current problem of model instability caused by label noise in the field of deep learning, greatly reducing the proportion of label noise in training samples and improving the robustness of neural network models.
One-Stage Deep Edge Detection Based on Dense-Scale Feature Fusion and Pixel-Level Imbalance Learning
Mar 17, 2022



Edge detection, a basic task in the field of computer vision, is an important preprocessing operation for the recognition and understanding of a visual scene. In conventional models, the edge image generated is ambiguous, and the edge lines are also very thick, which typically necessitates the use of non-maximum suppression (NMS) and morphological thinning operations to generate clear and thin edge images. In this paper, we aim to propose a one-stage neural network model that can generate high-quality edge images without postprocessing. The proposed model adopts a classic encoder-decoder framework in which a pre-trained neural model is used as the encoder and a multi-feature-fusion mechanism that merges the features of each level with each other functions as a learnable decoder. Further, we propose a new loss function that addresses the pixel-level imbalance in the edge image by suppressing the false positive (FP) edge information near the true positive (TP) edge and the false negative (FN) non-edge. The results of experiments conducted on several benchmark datasets indicate that the proposed method achieves state-of-the-art results without using NMS and morphological thinning operations.
Multi-granularity Association Learning Framework for on-the-fly Fine-Grained Sketch-based Image Retrieval
Jan 13, 2022



Fine-grained sketch-based image retrieval (FG-SBIR) addresses the problem of retrieving a particular photo in a given query sketch. However, its widespread applicability is limited by the fact that it is difficult to draw a complete sketch for most people, and the drawing process often takes time. In this study, we aim to retrieve the target photo with the least number of strokes possible (incomplete sketch), named on-the-fly FG-SBIR (Bhunia et al. 2020), which starts retrieving at each stroke as soon as the drawing begins. We consider that there is a significant correlation among these incomplete sketches in the sketch drawing episode of each photo. To learn more efficient joint embedding space shared between the photo and its incomplete sketches, we propose a multi-granularity association learning framework that further optimizes the embedding space of all incomplete sketches. Specifically, based on the integrity of the sketch, we can divide a complete sketch episode into several stages, each of which corresponds to a simple linear mapping layer. Moreover, our framework guides the vector space representation of the current sketch to approximate that of its later sketches to realize the retrieval performance of the sketch with fewer strokes to approach that of the sketch with more strokes. In the experiments, we proposed more realistic challenges, and our method achieved superior early retrieval efficiency over the state-of-the-art methods and alternative baselines on two publicly available fine-grained sketch retrieval datasets.
Rethinking the Image Feature Biases Exhibited by Deep CNN Models
Nov 03, 2021



In recent years, convolutional neural networks (CNNs) have been applied successfully in many fields. However, such deep neural models are still regarded as black box in most tasks. One of the fundamental issues underlying this problem is understanding which features are most influential in image recognition tasks and how they are processed by CNNs. It is widely accepted that CNN models combine low-level features to form complex shapes until the object can be readily classified, however, several recent studies have argued that texture features are more important than other features. In this paper, we assume that the importance of certain features varies depending on specific tasks, i.e., specific tasks exhibit a feature bias. We designed two classification tasks based on human intuition to train deep neural models to identify anticipated biases. We devised experiments comprising many tasks to test these biases for the ResNet and DenseNet models. From the results, we conclude that (1) the combined effect of certain features is typically far more influential than any single feature; (2) in different tasks, neural models can perform different biases, that is, we can design a specific task to make a neural model biased toward a specific anticipated feature.
Understanding the Feedforward Artificial Neural Network Model From the Perspective of Network Flow
Apr 26, 2017



In recent years, deep learning based on artificial neural network (ANN) has achieved great success in pattern recognition. However, there is no clear understanding of such neural computational models. In this paper, we try to unravel "black-box" structure of Ann model from network flow. Specifically, we consider the feed forward Ann as a network flow model, which consists of many directional class-pathways. Each class-pathway encodes one class. The class-pathway of a class is obtained by connecting the activated neural nodes in each layer from input to output, where activation value of neural node (node-value) is defined by the weights of each layer in a trained ANN-classifier. From the perspective of the class-pathway, training an ANN-classifier can be regarded as the formulation process of class-pathways of different classes. By analyzing the the distances of each two class-pathways in a trained ANN-classifiers, we try to answer the questions, why the classifier performs so? At last, from the neural encodes view, we define the importance of each neural node through the class-pathways, which is helpful to optimize the structure of a classifier. Experiments for two types of ANN model including multi-layer MLP and CNN verify that the network flow based on class-pathway is a reasonable explanation for ANN models.