 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDidier Stricker
End-to-End Semi-Supervised approach with Modulated Object Queries for Table Detection in Documents
May 08, 2024
Table detection, a pivotal task in document analysis, aims to precisely recognize and locate tables within document images. Although deep learning has shown remarkable progress in this realm, it typically requires an extensive dataset of labeled data for proficient training. Current CNN-based semi-supervised table detection approaches use the anchor generation process and Non-Maximum Suppression (NMS) in their detection process, limiting training efficiency. Meanwhile, transformer-based semi-supervised techniques adopted a one-to-one match strategy that provides noisy pseudo-labels, limiting overall efficiency. This study presents an innovative transformer-based semi-supervised table detector. It improves the quality of pseudo-labels through a novel matching strategy combining one-to-one and one-to-many assignment techniques. This approach significantly enhances training efficiency during the early stages, ensuring superior pseudo-labels for further training. Our semi-supervised approach is comprehensively evaluated on benchmark datasets, including PubLayNet, ICADR-19, and TableBank. It achieves new state-of-the-art results, with a mAP of 95.7% and 97.9% on TableBank (word) and PubLaynet with 30% label data, marking a 7.4 and 7.6 point improvement over previous semi-supervised table detection approach, respectively. The results clearly show the superiority of our semi-supervised approach, surpassing all existing state-of-the-art methods by substantial margins. This research represents a significant advancement in semi-supervised table detection methods, offering a more efficient and accurate solution for practical document analysis tasks.
CICA: Content-Injected Contrastive Alignment for Zero-Shot Document Image Classification
May 06, 2024Zero-shot learning has been extensively investigated in the broader field of visual recognition, attracting significant interest recently. However, the current work on zero-shot learning in document image classification remains scarce. The existing studies either focus exclusively on zero-shot inference, or their evaluation does not align with the established criteria of zero-shot evaluation in the visual recognition domain. We provide a comprehensive document image classification analysis in Zero-Shot Learning (ZSL) and Generalized Zero-Shot Learning (GZSL) settings to address this gap. Our methodology and evaluation align with the established practices of this domain. Additionally, we propose zero-shot splits for the RVL-CDIP dataset. Furthermore, we introduce CICA (pronounced 'ki-ka'), a framework that enhances the zero-shot learning capabilities of CLIP. CICA consists of a novel 'content module' designed to leverage any generic document-related textual information. The discriminative features extracted by this module are aligned with CLIP's text and image features using a novel 'coupled-contrastive' loss. Our module improves CLIP's ZSL top-1 accuracy by 6.7% and GZSL harmonic mean by 24% on the RVL-CDIP dataset. Our module is lightweight and adds only 3.3% more parameters to CLIP. Our work sets the direction for future research in zero-shot document classification.
A Hybrid Approach for Document Layout Analysis in Document images
Apr 30, 2024Document layout analysis involves understanding the arrangement of elements within a document. This paper navigates the complexities of understanding various elements within document images, such as text, images, tables, and headings. The approach employs an advanced Transformer-based object detection network as an innovative graphical page object detector for identifying tables, figures, and displayed elements. We introduce a query encoding mechanism to provide high-quality object queries for contrastive learning, enhancing efficiency in the decoder phase. We also present a hybrid matching scheme that integrates the decoder's original one-to-one matching strategy with the one-to-many matching strategy during the training phase. This approach aims to improve the model's accuracy and versatility in detecting various graphical elements on a page. Our experiments on PubLayNet, DocLayNet, and PubTables benchmarks show that our approach outperforms current state-of-the-art methods. It achieves an average precision of 97.3% on PubLayNet, 81.6% on DocLayNet, and 98.6 on PubTables, demonstrating its superior performance in layout analysis. These advancements not only enhance the conversion of document images into editable and accessible formats but also streamline information retrieval and data extraction processes.
Sparse Semi-DETR: Sparse Learnable Queries for Semi-Supervised Object Detection
Apr 02, 2024In this paper, we address the limitations of the DETR-based semi-supervised object detection (SSOD) framework, particularly focusing on the challenges posed by the quality of object queries. In DETR-based SSOD, the one-to-one assignment strategy provides inaccurate pseudo-labels, while the one-to-many assignments strategy leads to overlapping predictions. These issues compromise training efficiency and degrade model performance, especially in detecting small or occluded objects. We introduce Sparse Semi-DETR, a novel transformer-based, end-to-end semi-supervised object detection solution to overcome these challenges. Sparse Semi-DETR incorporates a Query Refinement Module to enhance the quality of object queries, significantly improving detection capabilities for small and partially obscured objects. Additionally, we integrate a Reliable Pseudo-Label Filtering Module that selectively filters high-quality pseudo-labels, thereby enhancing detection accuracy and consistency. On the MS-COCO and Pascal VOC object detection benchmarks, Sparse Semi-DETR achieves a significant improvement over current state-of-the-art methods that highlight Sparse Semi-DETR's effectiveness in semi-supervised object detection, particularly in challenging scenarios involving small or partially obscured objects.
SG-PGM: Partial Graph Matching Network with Semantic Geometric Fusion for 3D Scene Graph Alignment and Its Downstream Tasks
Mar 28, 2024



Scene graphs have been recently introduced into 3D spatial understanding as a comprehensive representation of the scene. The alignment between 3D scene graphs is the first step of many downstream tasks such as scene graph aided point cloud registration, mosaicking, overlap checking, and robot navigation. In this work, we treat 3D scene graph alignment as a partial graph-matching problem and propose to solve it with a graph neural network. We reuse the geometric features learned by a point cloud registration method and associate the clustered point-level geometric features with the node-level semantic feature via our designed feature fusion module. Partial matching is enabled by using a learnable method to select the top-k similar node pairs. Subsequent downstream tasks such as point cloud registration are achieved by running a pre-trained registration network within the matched regions. We further propose a point-matching rescoring method, that uses the node-wise alignment of the 3D scene graph to reweight the matching candidates from a pre-trained point cloud registration method. It reduces the false point correspondences estimated especially in low-overlapping cases. Experiments show that our method improves the alignment accuracy by 10~20% in low-overlap and random transformation scenarios and outperforms the existing work in multiple downstream tasks.
FocusCLIP: Multimodal Subject-Level Guidance for Zero-Shot Transfer in Human-Centric Tasks
Mar 11, 2024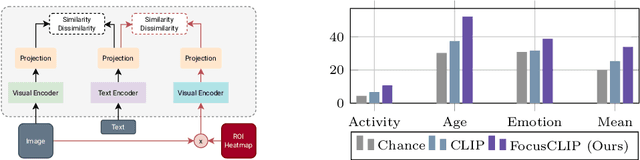
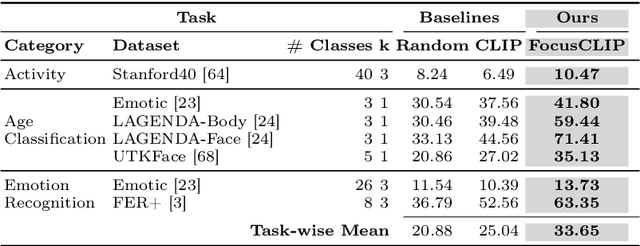
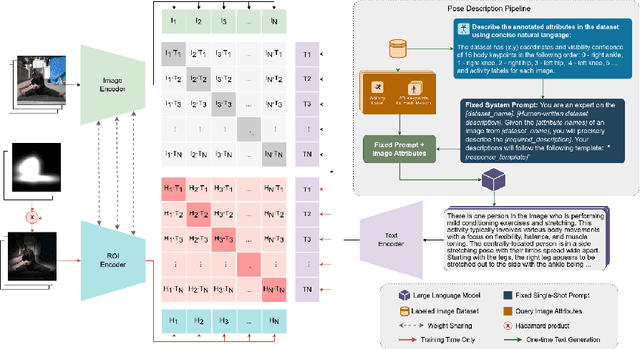
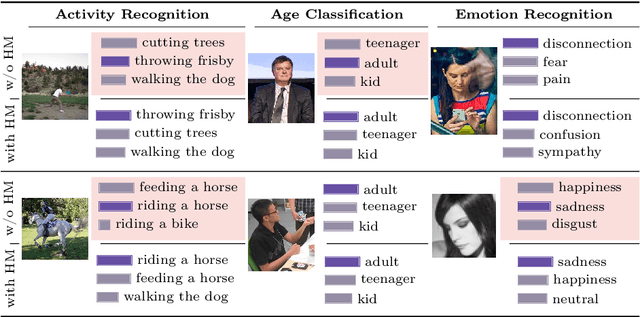
We propose FocusCLIP, integrating subject-level guidance--a specialized mechanism for target-specific supervision--into the CLIP framework for improved zero-shot transfer on human-centric tasks. Our novel contributions enhance CLIP on both the vision and text sides. On the vision side, we incorporate ROI heatmaps emulating human visual attention mechanisms to emphasize subject-relevant image regions. On the text side, we introduce human pose descriptions to provide rich contextual information. For human-centric tasks, FocusCLIP is trained with images from the MPII Human Pose dataset. The proposed approach surpassed CLIP by an average of 8.61% across five previously unseen datasets covering three human-centric tasks. FocusCLIP achieved an average accuracy of 33.65% compared to 25.04% by CLIP. We observed a 3.98% improvement in activity recognition, a 14.78% improvement in age classification, and a 7.06% improvement in emotion recognition. Moreover, using our proposed single-shot LLM prompting strategy, we release a high-quality MPII Pose Descriptions dataset to encourage further research in multimodal learning for human-centric tasks. Furthermore, we also demonstrate the effectiveness of our subject-level supervision on non-human-centric tasks. FocusCLIP shows a 2.47% improvement over CLIP in zero-shot bird classification using the CUB dataset. Our findings emphasize the potential of integrating subject-level guidance with general pretraining methods for enhanced downstream performance.
MiKASA: Multi-Key-Anchor & Scene-Aware Transformer for 3D Visual Grounding
Mar 11, 2024



3D visual grounding involves matching natural language descriptions with their corresponding objects in 3D spaces. Existing methods often face challenges with accuracy in object recognition and struggle in interpreting complex linguistic queries, particularly with descriptions that involve multiple anchors or are view-dependent. In response, we present the MiKASA (Multi-Key-Anchor Scene-Aware) Transformer. Our novel end-to-end trained model integrates a self-attention-based scene-aware object encoder and an original multi-key-anchor technique, enhancing object recognition accuracy and the understanding of spatial relationships. Furthermore, MiKASA improves the explainability of decision-making, facilitating error diagnosis. Our model achieves the highest overall accuracy in the Referit3D challenge for both the Sr3D and Nr3D datasets, particularly excelling by a large margin in categories that require viewpoint-dependent descriptions. The source code and additional resources for this project are available on GitHub: https://github.com/birdy666/MiKASA-3DVG
ShapeAug: Occlusion Augmentation for Event Camera Data
Jan 04, 2024Recently, Dynamic Vision Sensors (DVSs) sparked a lot of interest due to their inherent advantages over conventional RGB cameras. These advantages include a low latency, a high dynamic range and a low energy consumption. Nevertheless, the processing of DVS data using Deep Learning (DL) methods remains a challenge, particularly since the availability of event training data is still limited. This leads to a need for event data augmentation techniques in order to improve accuracy as well as to avoid over-fitting on the training data. Another challenge especially in real world automotive applications is occlusion, meaning one object is hindering the view onto the object behind it. In this paper, we present a novel event data augmentation approach, which addresses this problem by introducing synthetic events for randomly moving objects in a scene. We test our method on multiple DVS classification datasets, resulting in an relative improvement of up to 6.5 % in top1-accuracy. Moreover, we apply our augmentation technique on the real world Gen1 Automotive Event Dataset for object detection, where we especially improve the detection of pedestrians by up to 5 %.
Learned Fusion: 3D Object Detection using Calibration-Free Transformer Feature Fusion
Dec 14, 2023The state of the art in 3D object detection using sensor fusion heavily relies on calibration quality, which is difficult to maintain in large scale deployment outside a lab environment. We present the first calibration-free approach for 3D object detection. Thus, eliminating the need for complex and costly calibration procedures. Our approach uses transformers to map the features between multiple views of different sensors at multiple abstraction levels. In an extensive evaluation for object detection, we not only show that our approach outperforms single modal setups by 14.1% in BEV mAP, but also that the transformer indeed learns mapping. By showing calibration is not necessary for sensor fusion, we hope to motivate other researchers following the direction of calibration-free fusion. Additionally, resulting approaches have a substantial resilience against rotation and translation changes.
JPPF: Multi-task Fusion for Consistent Panoptic-Part Segmentation
Nov 30, 2023



Part-aware panoptic segmentation is a problem of computer vision that aims to provide a semantic understanding of the scene at multiple levels of granularity. More precisely, semantic areas, object instances, and semantic parts are predicted simultaneously. In this paper, we present our Joint Panoptic Part Fusion (JPPF) that combines the three individual segmentations effectively to obtain a panoptic-part segmentation. Two aspects are of utmost importance for this: First, a unified model for the three problems is desired that allows for mutually improved and consistent representation learning. Second, balancing the combination so that it gives equal importance to all individual results during fusion. Our proposed JPPF is parameter-free and dynamically balances its input. The method is evaluated and compared on the Cityscapes Panoptic Parts (CPP) and Pascal Panoptic Parts (PPP) datasets in terms of PartPQ and Part-Whole Quality (PWQ). In extensive experiments, we verify the importance of our fair fusion, highlight its most significant impact for areas that can be further segmented into parts, and demonstrate the generalization capabilities of our design without fine-tuning on 5 additional datasets.