 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDong Zhao
G3R: Generating Rich and Fine-grained mmWave Radar Data from 2D Videos for Generalized Gesture Recognition
Apr 23, 2024
Millimeter wave radar is gaining traction recently as a promising modality for enabling pervasive and privacy-preserving gesture recognition. However, the lack of rich and fine-grained radar datasets hinders progress in developing generalized deep learning models for gesture recognition across various user postures (e.g., standing, sitting), positions, and scenes. To remedy this, we resort to designing a software pipeline that exploits wealthy 2D videos to generate realistic radar data, but it needs to address the challenge of simulating diversified and fine-grained reflection properties of user gestures. To this end, we design G3R with three key components: (i) a gesture reflection point generator expands the arm's skeleton points to form human reflection points; (ii) a signal simulation model simulates the multipath reflection and attenuation of radar signals to output the human intensity map; (iii) an encoder-decoder model combines a sampling module and a fitting module to address the differences in number and distribution of points between generated and real-world radar data for generating realistic radar data. We implement and evaluate G3R using 2D videos from public data sources and self-collected real-world radar data, demonstrating its superiority over other state-of-the-art approaches for gesture recognition.
Semantic Connectivity-Driven Pseudo-labeling for Cross-domain Segmentation
Dec 11, 2023Presently, self-training stands as a prevailing approach in cross-domain semantic segmentation, enhancing model efficacy by training with pixels assigned with reliable pseudo-labels. However, we find two critical limitations in this paradigm. (1) The majority of reliable pixels exhibit a speckle-shaped pattern and are primarily located in the central semantic region. This presents challenges for the model in accurately learning semantics. (2) Category noise in speckle pixels is difficult to locate and correct, leading to error accumulation in self-training. To address these limitations, we propose a novel approach called Semantic Connectivity-driven pseudo-labeling (SeCo). This approach formulates pseudo-labels at the connectivity level and thus can facilitate learning structured and low-noise semantics. Specifically, SeCo comprises two key components: Pixel Semantic Aggregation (PSA) and Semantic Connectivity Correction (SCC). Initially, PSA divides semantics into 'stuff' and 'things' categories and aggregates speckled pseudo-labels into semantic connectivity through efficient interaction with the Segment Anything Model (SAM). This enables us not only to obtain accurate boundaries but also simplifies noise localization. Subsequently, SCC introduces a simple connectivity classification task, which enables locating and correcting connectivity noise with the guidance of loss distribution. Extensive experiments demonstrate that SeCo can be flexibly applied to various cross-domain semantic segmentation tasks, including traditional unsupervised, source-free, and black-box domain adaptation, significantly improving the performance of existing state-of-the-art methods. The code is available at https://github.com/DZhaoXd/SeCo.
FedAIoT: A Federated Learning Benchmark for Artificial Intelligence of Things
Sep 29, 2023There is a significant relevance of federated learning (FL) in the realm of Artificial Intelligence of Things (AIoT). However, most existing FL works are not conducted on datasets collected from authentic IoT devices that capture unique modalities and inherent challenges of IoT data. In this work, we introduce FedAIoT, an FL benchmark for AIoT to fill this critical gap. FedAIoT includes eight datatsets collected from a wide range of IoT devices. These datasets cover unique IoT modalities and target representative applications of AIoT. FedAIoT also includes a unified end-to-end FL framework for AIoT that simplifies benchmarking the performance of the datasets. Our benchmark results shed light on the opportunities and challenges of FL for AIoT. We hope FedAIoT could serve as an invaluable resource to foster advancements in the important field of FL for AIoT. The repository of FedAIoT is maintained at https://github.com/AIoT-MLSys-Lab/FedAIoT.
The Outcome of the 2022 Landslide4Sense Competition: Advanced Landslide Detection from Multi-Source Satellite Imagery
Sep 12, 2022
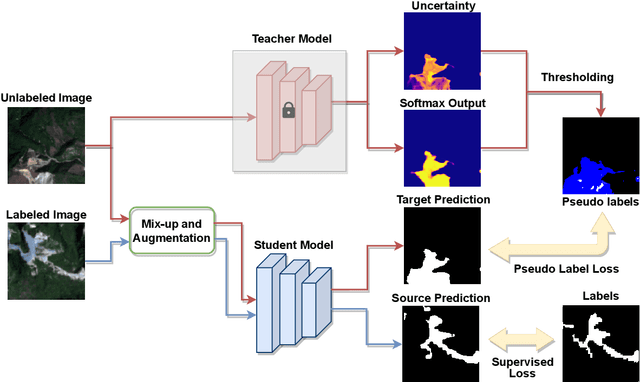
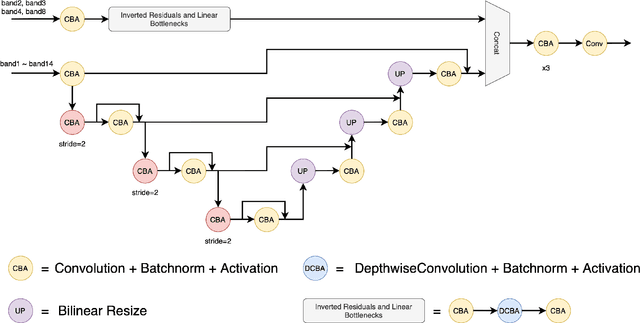
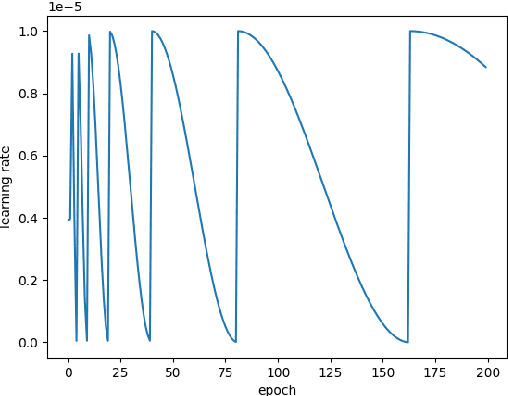
The scientific outcomes of the 2022 Landslide4Sense (L4S) competition organized by the Institute of Advanced Research in Artificial Intelligence (IARAI) are presented here. The objective of the competition is to automatically detect landslides based on large-scale multiple sources of satellite imagery collected globally. The 2022 L4S aims to foster interdisciplinary research on recent developments in deep learning (DL) models for the semantic segmentation task using satellite imagery. In the past few years, DL-based models have achieved performance that meets expectations on image interpretation, due to the development of convolutional neural networks (CNNs). The main objective of this article is to present the details and the best-performing algorithms featured in this competition. The winning solutions are elaborated with state-of-the-art models like the Swin Transformer, SegFormer, and U-Net. Advanced machine learning techniques and strategies such as hard example mining, self-training, and mix-up data augmentation are also considered. Moreover, we describe the L4S benchmark data set in order to facilitate further comparisons, and report the results of the accuracy assessment online. The data is accessible on \textit{Future Development Leaderboard} for future evaluation at \url{https://www.iarai.ac.at/landslide4sense/challenge/}, and researchers are invited to submit more prediction results, evaluate the accuracy of their methods, compare them with those of other users, and, ideally, improve the landslide detection results reported in this article.
Learning to Help Emergency Vehicles Arrive Faster: A Cooperative Vehicle-Road Scheduling Approach
Feb 20, 2022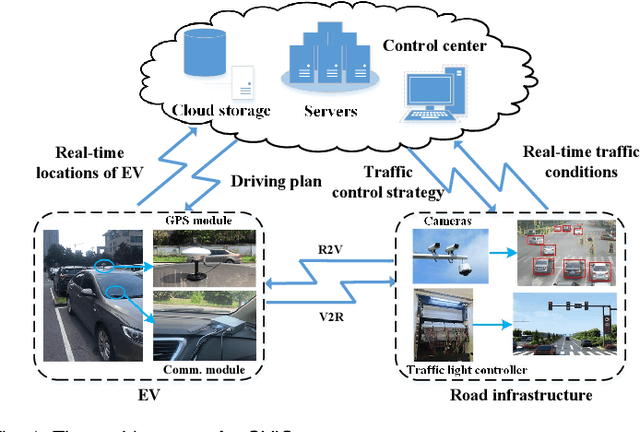
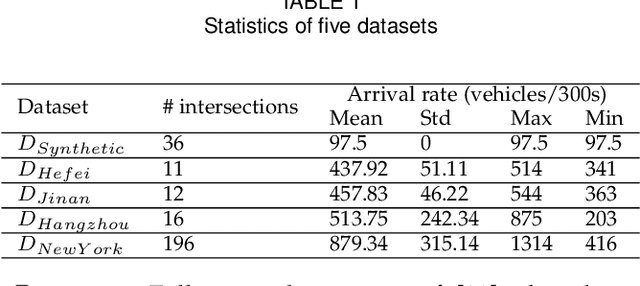


The ever-increasing heavy traffic congestion potentially impedes the accessibility of emergency vehicles (EVs), resulting in detrimental impacts on critical services and even safety of people's lives. Hence, it is significant to propose an efficient scheduling approach to help EVs arrive faster. Existing vehicle-centric scheduling approaches aim to recommend the optimal paths for EVs based on the current traffic status while the road-centric scheduling approaches aim to improve the traffic condition and assign a higher priority for EVs to pass an intersection. With the intuition that real-time vehicle-road information interaction and strategy coordination can bring more benefits, we propose LEVID, a LEarning-based cooperative VehIcle-roaD scheduling approach including a real-time route planning module and a collaborative traffic signal control module, which interact with each other and make decisions iteratively. The real-time route planning module adapts the artificial potential field method to address the real-time changes of traffic signals and avoid falling into a local optimum. The collaborative traffic signal control module leverages a graph attention reinforcement learning framework to extract the latent features of different intersections and abstract their interplay to learn cooperative policies. Extensive experiments based on multiple real-world datasets show that our approach outperforms the state-of-the-art baselines.
SPAP: Simultaneous Demand Prediction and Planning for Electric Vehicle Chargers in a New City
Oct 18, 2021



For a new city that is committed to promoting Electric Vehicles (EVs), it is significant to plan the public charging infrastructure where charging demands are high. However, it is difficult to predict charging demands before the actual deployment of EV chargers for lack of operational data, resulting in a deadlock. A direct idea is to leverage the urban transfer learning paradigm to learn the knowledge from a source city, then exploit it to predict charging demands, and meanwhile determine locations and amounts of slow/fast chargers for charging stations in the target city. However, the demand prediction and charger planning depend on each other, and it is required to re-train the prediction model to eliminate the negative transfer between cities for each varied charger plan, leading to the unacceptable time complexity. To this end, we propose the concept and an effective solution of Simultaneous Demand Prediction And Planning (SPAP): discriminative features are extracted from multi-source data, and fed into an Attention-based Spatial-Temporal City Domain Adaptation Network (AST-CDAN) for cross-city demand prediction; a novel Transfer Iterative Optimization (TIO) algorithm is designed for charger planning by iteratively utilizing AST-CDAN and a charger plan fine-tuning algorithm. Extensive experiments on real-world datasets collected from three cities in China validate the effectiveness and efficiency of SPAP. Specially, SPAP improves at most 72.5% revenue compared with the real-world charger deployment.
Hybrid Local-Global Transformer for Image Dehazing
Sep 18, 2021



Recently, the Vision Transformer (ViT) has shown impressive performance on high-level and low-level vision tasks. In this paper, we propose a new ViT architecture, named Hybrid Local-Global Vision Transformer (HyLoG-ViT), for single image dehazing. The HyLoG-ViT block consists of two paths, the local ViT path and the global ViT path, which are used to capture local and global dependencies. The hybrid features are fused via convolution layers. As a result, the HyLoG-ViT reduces the computational complexity and introduces locality in the networks. Then, the HyLoG-ViT blocks are incorporated within our dehazing networks, which jointly learn the intrinsic image decomposition and image dehazing. Specifically, the network consists of one shared encoder and three decoders for reflectance prediction, shading prediction, and haze-free image generation. The tasks of reflectance and shading prediction can produce meaningful intermediate features that can serve as complementary features for haze-free image generation. To effectively aggregate the complementary features, we propose a complementary features selection module (CFSM) to select the useful ones for image dehazing. Extensive experiments on homogeneous, non-homogeneous, and nighttime dehazing tasks reveal that our proposed Transformer-based dehazing network can achieve comparable or even better performance than CNNs-based dehazing models.
Hybrid and dynamic policy gradient optimization for bipedal robot locomotion
Jul 05, 2021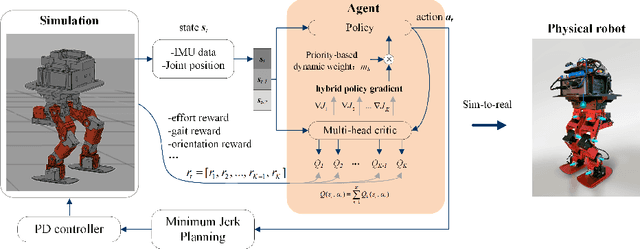
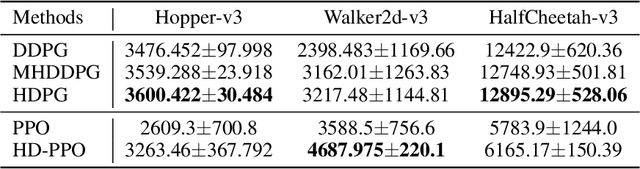
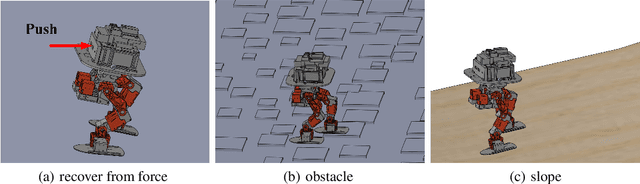
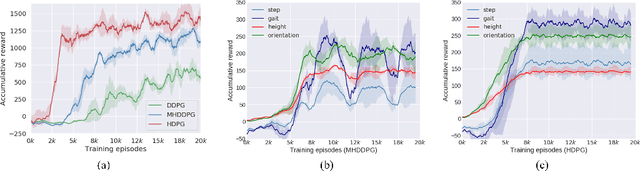
Controlling a non-statically bipedal robot is challenging due to the complex dynamics and multi-criterion optimization involved. Recent works have demonstrated the effectiveness of deep reinforcement learning (DRL) for simulation and physically implemented bipeds. In these methods, the rewards from different criteria are normally summed to learn a single value function. However, this may cause the loss of dependency information between hybrid rewards and lead to a sub-optimal policy. In this work, we propose a novel policy gradient reinforcement learning for biped locomotion, allowing the control policy to be simultaneously optimized by multiple criteria using a dynamic mechanism. Our proposed method applies a multi-head critic to learn a separate value function for each component reward function. This also leads to hybrid policy gradients. We further propose dynamic weight for hybrid policy gradients to optimize the policy with different priorities. This hybrid and dynamic policy gradient (HDPG) design makes the agent learn more efficiently. We showed that the proposed method outperforms summed-up-reward approaches and is able to transfer to physical robots. The MuJoCo results further demonstrate the effectiveness and generalization of our HDPG.
More Separable and Easier to Segment: A Cluster Alignment Method for Cross-Domain Semantic Segmentation
May 07, 2021
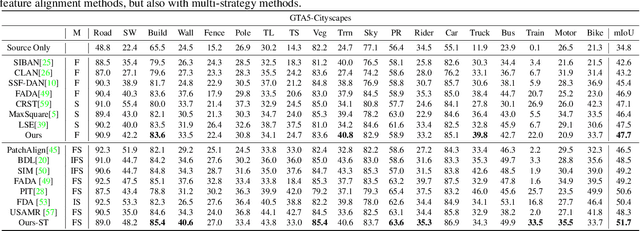
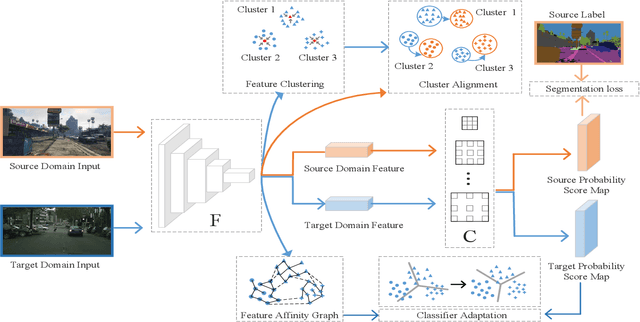
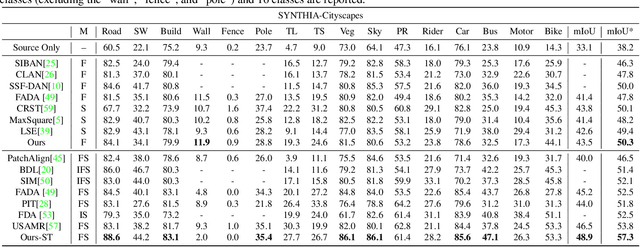
Feature alignment between domains is one of the mainstream methods for Unsupervised Domain Adaptation (UDA) semantic segmentation. Existing feature alignment methods for semantic segmentation learn domain-invariant features by adversarial training to reduce domain discrepancy, but they have two limits: 1) associations among pixels are not maintained, 2) the classifier trained on the source domain couldn't adapted well to the target. In this paper, we propose a new UDA semantic segmentation approach based on domain closeness assumption to alleviate the above problems. Specifically, a prototype clustering strategy is applied to cluster pixels with the same semantic, which will better maintain associations among target domain pixels during the feature alignment. After clustering, to make the classifier more adaptive, a normalized cut loss based on the affinity graph of the target domain is utilized, which will make the decision boundary target-specific. Sufficient experiments conducted on GTA5 $\rightarrow$ Cityscapes and SYNTHIA $\rightarrow$ Cityscapes proved the effectiveness of our method, which illustrated that our results achieved the new state-of-the-art.