 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTiantian Feng
LOG-LIO2: A LiDAR-Inertial Odometry with Efficient Uncertainty Analysis
May 02, 2024
Uncertainty in LiDAR measurements, stemming from factors such as range sensing, is crucial for LIO (LiDAR-Inertial Odometry) systems as it affects the accurate weighting in the loss function. While recent LIO systems address uncertainty related to range sensing, the impact of incident angle on uncertainty is often overlooked by the community. Moreover, the existing uncertainty propagation methods suffer from computational inefficiency. This paper proposes a comprehensive point uncertainty model that accounts for both the uncertainties from LiDAR measurements and surface characteristics, along with an efficient local uncertainty analytical method for LiDAR-based state estimation problem. We employ a projection operator that separates the uncertainty into the ray direction and its orthogonal plane. Then, we derive incremental Jacobian matrices of eigenvalues and eigenvectors w.r.t. points, which enables a fast approximation of uncertainty propagation. This approach eliminates the requirement for redundant traversal of points, significantly reducing the time complexity of uncertainty propagation from $\mathcal{O} (n)$ to $\mathcal{O} (1)$ when a new point is added. Simulations and experiments on public datasets are conducted to validate the accuracy and efficiency of our formulations. The proposed methods have been integrated into a LIO system, which is available at https://github.com/tiev-tongji/LOG-LIO2.
TI-ASU: Toward Robust Automatic Speech Understanding through Text-to-speech Imputation Against Missing Speech Modality
Apr 27, 2024Automatic Speech Understanding (ASU) aims at human-like speech interpretation, providing nuanced intent, emotion, sentiment, and content understanding from speech and language (text) content conveyed in speech. Typically, training a robust ASU model relies heavily on acquiring large-scale, high-quality speech and associated transcriptions. However, it is often challenging to collect or use speech data for training ASU due to concerns such as privacy. To approach this setting of enabling ASU when speech (audio) modality is missing, we propose TI-ASU, using a pre-trained text-to-speech model to impute the missing speech. We report extensive experiments evaluating TI-ASU on various missing scales, both multi- and single-modality settings, and the use of LLMs. Our findings show that TI-ASU yields substantial benefits to improve ASU in scenarios where even up to 95% of training speech is missing. Moreover, we show that TI-ASU is adaptive to dropout training, improving model robustness in addressing missing speech during inference.
Partial Federated Learning
Mar 03, 2024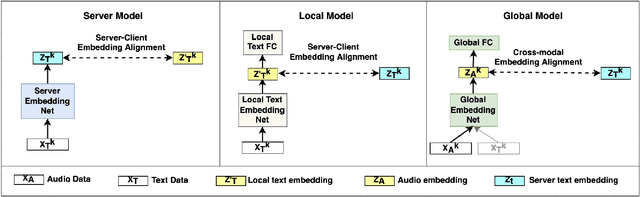
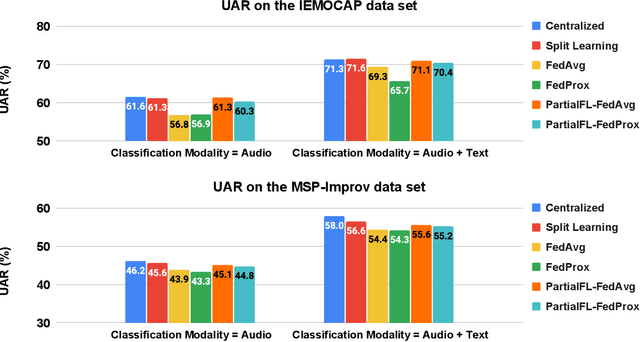
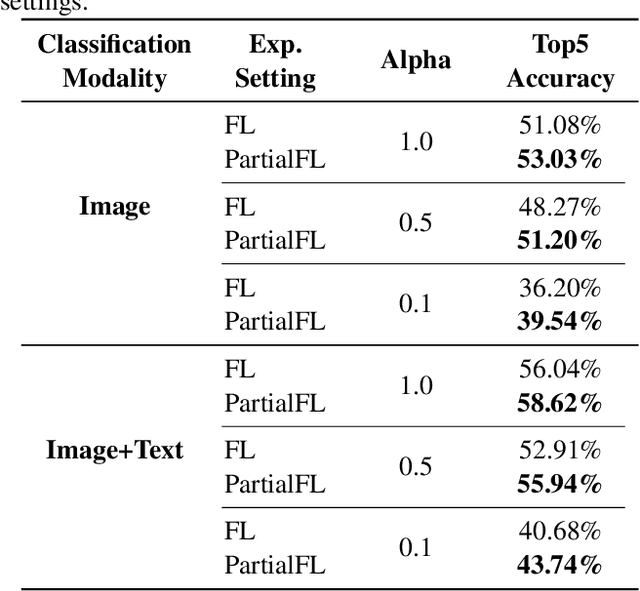
Federated Learning (FL) is a popular algorithm to train machine learning models on user data constrained to edge devices (for example, mobile phones) due to privacy concerns. Typically, FL is trained with the assumption that no part of the user data can be egressed from the edge. However, in many production settings, specific data-modalities/meta-data are limited to be on device while others are not. For example, in commercial SLU systems, it is typically desired to prevent transmission of biometric signals (such as audio recordings of the input prompt) to the cloud, but egress of locally (i.e. on the edge device) transcribed text to the cloud may be possible. In this work, we propose a new algorithm called Partial Federated Learning (PartialFL), where a machine learning model is trained using data where a subset of data modalities or their intermediate representations can be made available to the server. We further restrict our model training by preventing the egress of data labels to the cloud for better privacy, and instead use a contrastive learning based model objective. We evaluate our approach on two different multi-modal datasets and show promising results with our proposed approach.
Can Text-to-image Model Assist Multi-modal Learning for Visual Recognition with Visual Modality Missing?
Feb 14, 2024Multi-modal learning has emerged as an increasingly promising avenue in vision recognition, driving innovations across diverse domains ranging from media and education to healthcare and transportation. Despite its success, the robustness of multi-modal learning for visual recognition is often challenged by the unavailability of a subset of modalities, especially the visual modality. Conventional approaches to mitigate missing modalities in multi-modal learning rely heavily on algorithms and modality fusion schemes. In contrast, this paper explores the use of text-to-image models to assist multi-modal learning. Specifically, we propose a simple but effective multi-modal learning framework GTI-MM to enhance the data efficiency and model robustness against missing visual modality by imputing the missing data with generative transformers. Using multiple multi-modal datasets with visual recognition tasks, we present a comprehensive analysis of diverse conditions involving missing visual modality in data, including model training. Our findings reveal that synthetic images benefit training data efficiency with visual data missing in training and improve model robustness with visual data missing involving training and testing. Moreover, we demonstrate GTI-MM is effective with lower generation quantity and simple prompt techniques.
N$^{3}$-Mapping: Normal Guided Neural Non-Projective Signed Distance Fields for Large-scale 3D Mapping
Jan 07, 2024Accurate and dense mapping in large-scale environments is essential for various robot applications. Recently, implicit neural signed distance fields (SDFs) have shown promising advances in this task. However, most existing approaches employ projective distances from range data as SDF supervision, introducing approximation errors and thus degrading the mapping quality. To address this problem, we introduce N3-Mapping, an implicit neural mapping system featuring normal-guided neural non-projective signed distance fields. Specifically, we directly sample points along the surface normal, instead of the ray, to obtain more accurate non-projective distance values from range data. Then these distance values are used as supervision to train the implicit map. For large-scale mapping, we apply a voxel-oriented sliding window mechanism to alleviate the forgetting issue with a bounded memory footprint. Besides, considering the uneven distribution of measured point clouds, a hierarchical sampling strategy is designed to improve training efficiency. Experiments demonstrate that our method effectively mitigates SDF approximation errors and achieves state-of-the-art mapping quality compared to existing approaches.
Audio-visual child-adult speaker classification in dyadic interactions
Oct 09, 2023Interactions involving children span a wide range of important domains from learning to clinical diagnostic and therapeutic contexts. Automated analyses of such interactions are motivated by the need to seek accurate insights and offer scale and robustness across diverse and wide-ranging conditions. Identifying the speech segments belonging to the child is a critical step in such modeling. Conventional child-adult speaker classification typically relies on audio modeling approaches, overlooking visual signals that convey speech articulation information, such as lip motion. Building on the foundation of an audio-only child-adult speaker classification pipeline, we propose incorporating visual cues through active speaker detection and visual processing models. Our framework involves video pre-processing, utterance-level child-adult speaker detection, and late fusion of modality-specific predictions. We demonstrate from extensive experiments that a visually aided classification pipeline enhances the accuracy and robustness of the classification. We show relative improvements of 2.38% and 3.97% in F1 macro score when one face and two faces are visible, respectively.
FedAIoT: A Federated Learning Benchmark for Artificial Intelligence of Things
Sep 29, 2023There is a significant relevance of federated learning (FL) in the realm of Artificial Intelligence of Things (AIoT). However, most existing FL works are not conducted on datasets collected from authentic IoT devices that capture unique modalities and inherent challenges of IoT data. In this work, we introduce FedAIoT, an FL benchmark for AIoT to fill this critical gap. FedAIoT includes eight datatsets collected from a wide range of IoT devices. These datasets cover unique IoT modalities and target representative applications of AIoT. FedAIoT also includes a unified end-to-end FL framework for AIoT that simplifies benchmarking the performance of the datasets. Our benchmark results shed light on the opportunities and challenges of FL for AIoT. We hope FedAIoT could serve as an invaluable resource to foster advancements in the important field of FL for AIoT. The repository of FedAIoT is maintained at https://github.com/AIoT-MLSys-Lab/FedAIoT.
Scaling Representation Learning from Ubiquitous ECG with State-Space Models
Sep 26, 2023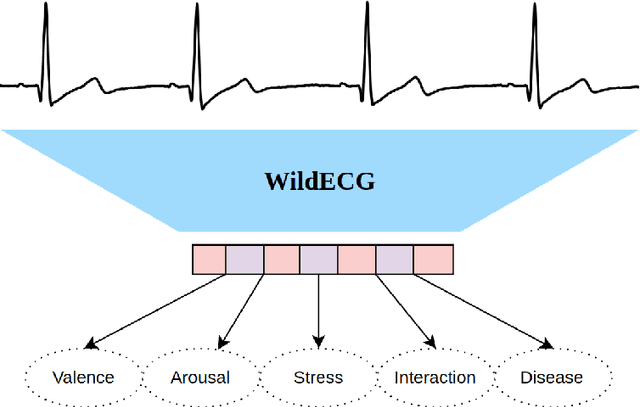
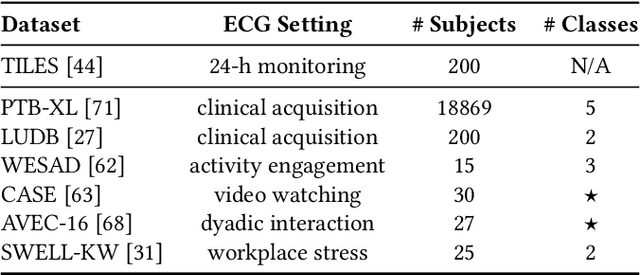
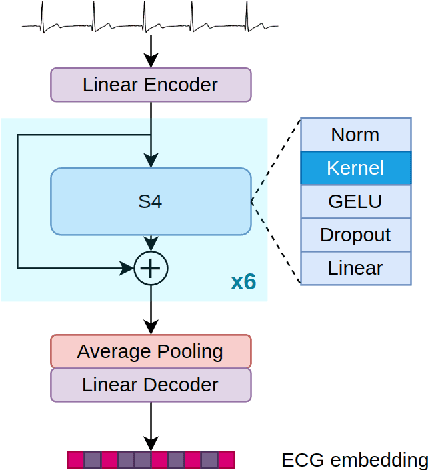
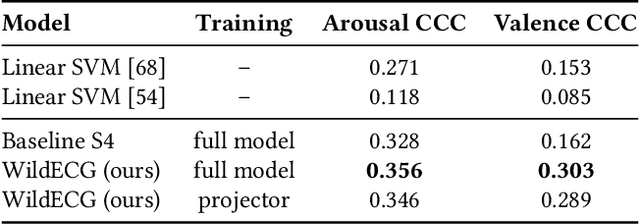
Ubiquitous sensing from wearable devices in the wild holds promise for enhancing human well-being, from diagnosing clinical conditions and measuring stress to building adaptive health promoting scaffolds. But the large volumes of data therein across heterogeneous contexts pose challenges for conventional supervised learning approaches. Representation Learning from biological signals is an emerging realm catalyzed by the recent advances in computational modeling and the abundance of publicly shared databases. The electrocardiogram (ECG) is the primary researched modality in this context, with applications in health monitoring, stress and affect estimation. Yet, most studies are limited by small-scale controlled data collection and over-parameterized architecture choices. We introduce \textbf{WildECG}, a pre-trained state-space model for representation learning from ECG signals. We train this model in a self-supervised manner with 275,000 10s ECG recordings collected in the wild and evaluate it on a range of downstream tasks. The proposed model is a robust backbone for ECG analysis, providing competitive performance on most of the tasks considered, while demonstrating efficacy in low-resource regimes. The code and pre-trained weights are shared publicly at https://github.com/klean2050/tiles_ecg_model.
Directional Source Separation for Robust Speech Recognition on Smart Glasses
Sep 20, 2023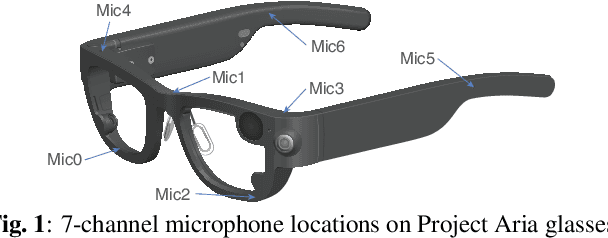
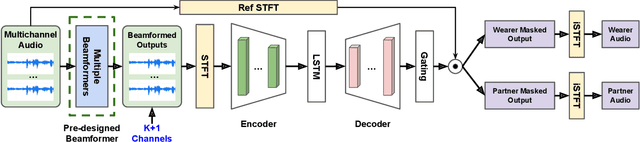
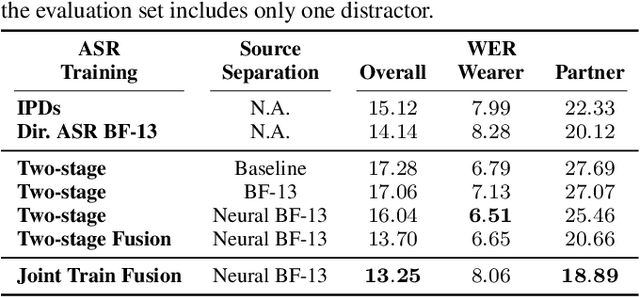
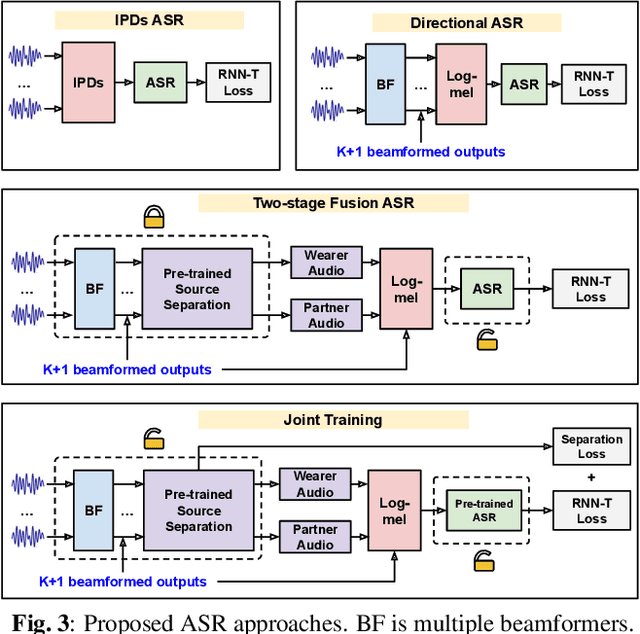
Modern smart glasses leverage advanced audio sensing and machine learning technologies to offer real-time transcribing and captioning services, considerably enriching human experiences in daily communications. However, such systems frequently encounter challenges related to environmental noises, resulting in degradation to speech recognition and speaker change detection. To improve voice quality, this work investigates directional source separation using the multi-microphone array. We first explore multiple beamformers to assist source separation modeling by strengthening the directional properties of speech signals. In addition to relying on predetermined beamformers, we investigate neural beamforming in multi-channel source separation, demonstrating that automatic learning directional characteristics effectively improves separation quality. We further compare the ASR performance leveraging separated outputs to noisy inputs. Our results show that directional source separation benefits ASR for the wearer but not for the conversation partner. Lastly, we perform the joint training of the directional source separation and ASR model, achieving the best overall ASR performance.
Foundation Model Assisted Automatic Speech Emotion Recognition: Transcribing, Annotating, and Augmenting
Sep 15, 2023

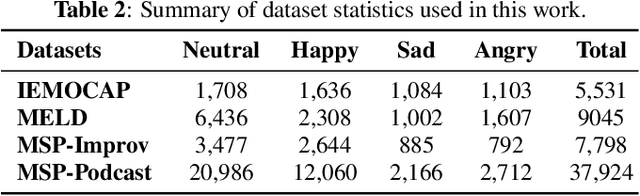

Significant advances are being made in speech emotion recognition (SER) using deep learning models. Nonetheless, training SER systems remains challenging, requiring both time and costly resources. Like many other machine learning tasks, acquiring datasets for SER requires substantial data annotation efforts, including transcription and labeling. These annotation processes present challenges when attempting to scale up conventional SER systems. Recent developments in foundational models have had a tremendous impact, giving rise to applications such as ChatGPT. These models have enhanced human-computer interactions including bringing unique possibilities for streamlining data collection in fields like SER. In this research, we explore the use of foundational models to assist in automating SER from transcription and annotation to augmentation. Our study demonstrates that these models can generate transcriptions to enhance the performance of SER systems that rely solely on speech data. Furthermore, we note that annotating emotions from transcribed speech remains a challenging task. However, combining outputs from multiple LLMs enhances the quality of annotations. Lastly, our findings suggest the feasibility of augmenting existing speech emotion datasets by annotating unlabeled speech samples.