 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRichard Zemel
Toward Informal Language Processing: Knowledge of Slang in Large Language Models
Apr 13, 2024
Recent advancement in large language models (LLMs) has offered a strong potential for natural language systems to process informal language. A representative form of informal language is slang, used commonly in daily conversations and online social media. To date, slang has not been comprehensively evaluated in LLMs due partly to the absence of a carefully designed and publicly accessible benchmark. Using movie subtitles, we construct a dataset that supports evaluation on a diverse set of tasks pertaining to automatic processing of slang. For both evaluation and finetuning, we show the effectiveness of our dataset on two core applications: 1) slang detection, and 2) identification of regional and historical sources of slang from natural sentences. We also show how our dataset can be used to probe the output distributions of LLMs for interpretive insights. We find that while LLMs such as GPT-4 achieve good performance in a zero-shot setting, smaller BERT-like models finetuned on our dataset achieve comparable performance. Furthermore, we show that our dataset enables finetuning of LLMs such as GPT-3.5 that achieve substantially better performance than strong zero-shot baselines. Our work offers a comprehensive evaluation and a high-quality benchmark on English slang based on the OpenSubtitles corpus, serving both as a publicly accessible resource and a platform for applying tools for informal language processing.
Partial Federated Learning
Mar 03, 2024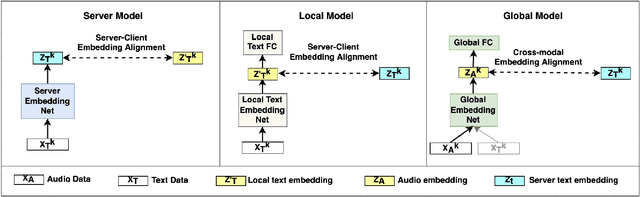
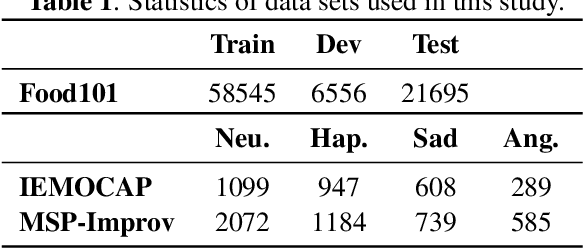
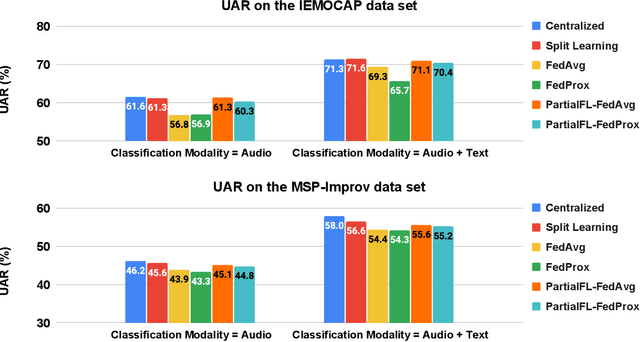
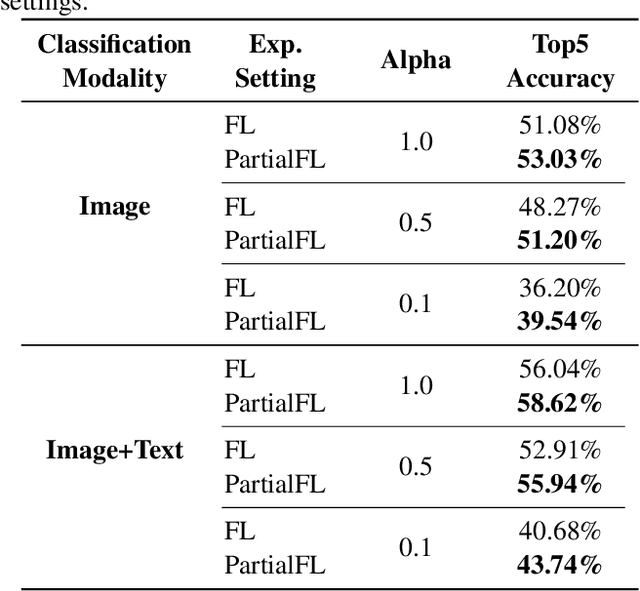
Federated Learning (FL) is a popular algorithm to train machine learning models on user data constrained to edge devices (for example, mobile phones) due to privacy concerns. Typically, FL is trained with the assumption that no part of the user data can be egressed from the edge. However, in many production settings, specific data-modalities/meta-data are limited to be on device while others are not. For example, in commercial SLU systems, it is typically desired to prevent transmission of biometric signals (such as audio recordings of the input prompt) to the cloud, but egress of locally (i.e. on the edge device) transcribed text to the cloud may be possible. In this work, we propose a new algorithm called Partial Federated Learning (PartialFL), where a machine learning model is trained using data where a subset of data modalities or their intermediate representations can be made available to the server. We further restrict our model training by preventing the egress of data labels to the cloud for better privacy, and instead use a contrastive learning based model objective. We evaluate our approach on two different multi-modal datasets and show promising results with our proposed approach.
Online Algorithmic Recourse by Collective Action
Dec 29, 2023Research on algorithmic recourse typically considers how an individual can reasonably change an unfavorable automated decision when interacting with a fixed decision-making system. This paper focuses instead on the online setting, where system parameters are updated dynamically according to interactions with data subjects. Beyond the typical individual-level recourse, the online setting opens up new ways for groups to shape system decisions by leveraging the parameter update rule. We show empirically that recourse can be improved when users coordinate by jointly computing their feature perturbations, underscoring the importance of collective action in mitigating adverse automated decisions.
Out of the Ordinary: Spectrally Adapting Regression for Covariate Shift
Dec 29, 2023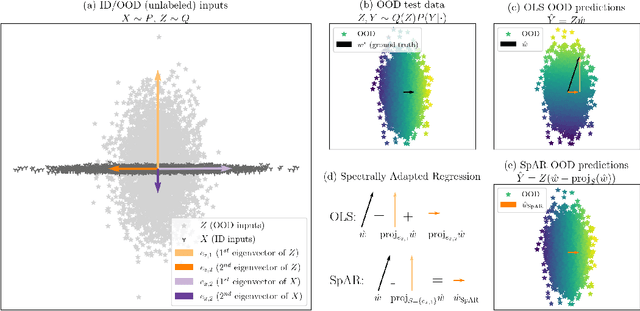
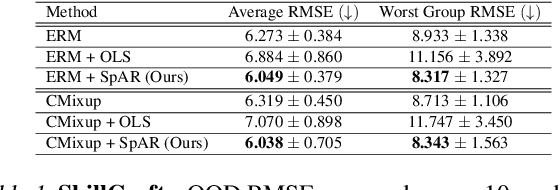
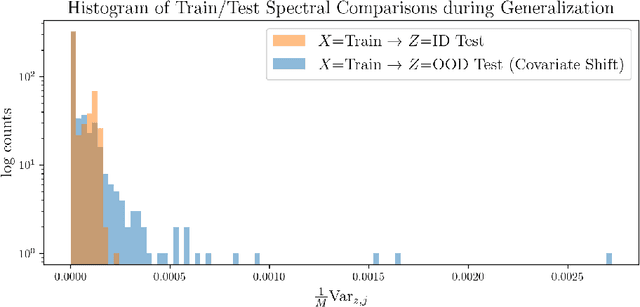

Designing deep neural network classifiers that perform robustly on distributions differing from the available training data is an active area of machine learning research. However, out-of-distribution generalization for regression-the analogous problem for modeling continuous targets-remains relatively unexplored. To tackle this problem, we return to first principles and analyze how the closed-form solution for Ordinary Least Squares (OLS) regression is sensitive to covariate shift. We characterize the out-of-distribution risk of the OLS model in terms of the eigenspectrum decomposition of the source and target data. We then use this insight to propose a method for adapting the weights of the last layer of a pre-trained neural regression model to perform better on input data originating from a different distribution. We demonstrate how this lightweight spectral adaptation procedure can improve out-of-distribution performance for synthetic and real-world datasets.
Are you talking to ['xem'] or ['x', 'em']? On Tokenization and Addressing Misgendering in LLMs with Pronoun Tokenization Parity
Dec 21, 2023A large body of NLP research has documented the ways gender biases manifest and amplify within large language models (LLMs), though this research has predominantly operated within a gender binary-centric context. A growing body of work has identified the harmful limitations of this gender-exclusive framing; many LLMs cannot correctly and consistently refer to persons outside the gender binary, especially if they use neopronouns. While data scarcity has been identified as a possible culprit, the precise mechanisms through which it influences LLM misgendering remain underexplored. Our work addresses this gap by studying data scarcity's role in subword tokenization and, consequently, the formation of LLM word representations. We uncover how the Byte-Pair Encoding (BPE) tokenizer, a backbone for many popular LLMs, contributes to neopronoun misgendering through out-of-vocabulary behavior. We introduce pronoun tokenization parity (PTP), a novel approach to reduce LLM neopronoun misgendering by preserving a token's functional structure. We evaluate PTP's efficacy using pronoun consistency-based metrics and a novel syntax-based metric. Through several controlled experiments, finetuning LLMs with PTP improves neopronoun consistency from 14.5% to 58.4%, highlighting the significant role tokenization plays in LLM pronoun consistency.
ICL Markup: Structuring In-Context Learning using Soft-Token Tags
Dec 12, 2023Large pretrained language models (LLMs) can be rapidly adapted to a wide variety of tasks via a text-to-text approach, where the instruction and input are fed to the model in natural language. Combined with in-context learning (ICL), this paradigm is impressively flexible and powerful. However, it also burdens users with an overwhelming number of choices, many of them arbitrary. Inspired by markup languages like HTML, we contribute a method of using soft-token tags to compose prompt templates. This approach reduces arbitrary decisions and streamlines the application of ICL. Our method is a form of meta-learning for ICL; it learns these tags in advance during a parameter-efficient fine-tuning ``warm-up'' process. The tags can subsequently be used in templates for ICL on new, unseen tasks without any additional fine-tuning. Our experiments with this approach yield promising initial results, improving LLM performance on important enterprise applications such as few-shot and open-world intent detection, as well as text classification in news and legal domains.
Prompt Risk Control: A Rigorous Framework for Responsible Deployment of Large Language Models
Nov 22, 2023The recent explosion in the capabilities of large language models has led to a wave of interest in how best to prompt a model to perform a given task. While it may be tempting to simply choose a prompt based on average performance on a validation set, this can lead to a deployment where unexpectedly poor responses are generated, especially for the worst-off users. To mitigate this prospect, we propose Prompt Risk Control, a lightweight framework for selecting a prompt based on rigorous upper bounds on families of informative risk measures. We offer methods for producing bounds on a diverse set of metrics, including quantities that measure worst-case responses and disparities in generation quality across the population of users. In addition, we extend the underlying statistical bounding techniques to accommodate the possibility of distribution shifts in deployment. Experiments on applications such as open-ended chat, medical question summarization, and code generation highlight how such a framework can foster responsible deployment by reducing the risk of the worst outcomes.
JAB: Joint Adversarial Prompting and Belief Augmentation
Nov 16, 2023With the recent surge of language models in different applications, attention to safety and robustness of these models has gained significant importance. Here we introduce a joint framework in which we simultaneously probe and improve the robustness of a black-box target model via adversarial prompting and belief augmentation using iterative feedback loops. This framework utilizes an automated red teaming approach to probe the target model, along with a belief augmenter to generate instructions for the target model to improve its robustness to those adversarial probes. Importantly, the adversarial model and the belief generator leverage the feedback from past interactions to improve the effectiveness of the adversarial prompts and beliefs, respectively. In our experiments, we demonstrate that such a framework can reduce toxic content generation both in dynamic cases where an adversary directly interacts with a target model and static cases where we use a static benchmark dataset to evaluate our model.
On the steerability of large language models toward data-driven personas
Nov 08, 2023The recent surge in Large Language Model (LLM) related applications has led to a concurrent escalation in expectations for LLMs to accommodate a myriad of personas and encompass a broad spectrum of perspectives. An important first step towards addressing this demand is to align language models with specific personas, be it groups of users or individuals. Towards this goal, we first present a new conceptualization of a persona. Moving beyond the traditional reliance on demographics like age, gender, or political party affiliation, we introduce a data-driven persona definition methodology built on collaborative-filtering. In this methodology, users are embedded into a continuous vector space based on their opinions and clustered into cohorts that manifest coherent views across specific inquiries. This methodology allows for a more nuanced understanding of different latent social groups present in the overall population (as opposed to simply using demographic groups) and enhances the applicability of model steerability. Finally, we present an efficient method to steer LLMs towards a particular persona. We learn a soft-prompting model to map the continuous representation of users into sequences of virtual tokens which, when prepended to the LLM input, enables the LLM to produce responses aligned with a given user. Our results show that our steerability algorithm is superior in performance compared to a collection of baselines.