 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrank Seide
Effective internal language model training and fusion for factorized transducer model
Apr 02, 2024
The internal language model (ILM) of the neural transducer has been widely studied. In most prior work, it is mainly used for estimating the ILM score and is subsequently subtracted during inference to facilitate improved integration with external language models. Recently, various of factorized transducer models have been proposed, which explicitly embrace a standalone internal language model for non-blank token prediction. However, even with the adoption of factorized transducer models, limited improvement has been observed compared to shallow fusion. In this paper, we propose a novel ILM training and decoding strategy for factorized transducer models, which effectively combines the blank, acoustic and ILM scores. Our experiments show a 17% relative improvement over the standard decoding method when utilizing a well-trained ILM and the proposed decoding strategy on LibriSpeech datasets. Furthermore, when compared to a strong RNN-T baseline enhanced with external LM fusion, the proposed model yields a 5.5% relative improvement on general-sets and an 8.9% WER reduction for rare words. The proposed model can achieve superior performance without relying on external language models, rendering it highly efficient for production use-cases. To further improve the performance, we propose a novel and memory-efficient ILM-fusion-aware minimum word error rate (MWER) training method which improves ILM integration significantly.
AGADIR: Towards Array-Geometry Agnostic Directional Speech Recognition
Jan 18, 2024Wearable devices like smart glasses are approaching the compute capability to seamlessly generate real-time closed captions for live conversations. We build on our recently introduced directional Automatic Speech Recognition (ASR) for smart glasses that have microphone arrays, which fuses multi-channel ASR with serialized output training, for wearer/conversation-partner disambiguation as well as suppression of cross-talk speech from non-target directions and noise. When ASR work is part of a broader system-development process, one may be faced with changes to microphone geometries as system development progresses. This paper aims to make multi-channel ASR insensitive to limited variations of microphone-array geometry. We show that a model trained on multiple similar geometries is largely agnostic and generalizes well to new geometries, as long as they are not too different. Furthermore, training the model this way improves accuracy for seen geometries by 15 to 28\% relative. Lastly, we refine the beamforming by a novel Non-Linearly Constrained Minimum Variance criterion.
Directional Source Separation for Robust Speech Recognition on Smart Glasses
Sep 20, 2023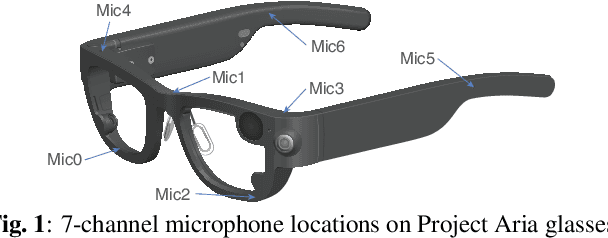
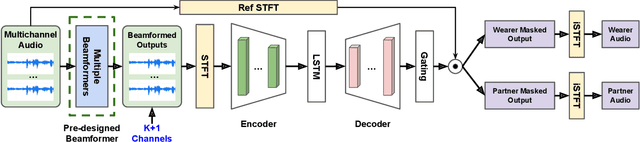
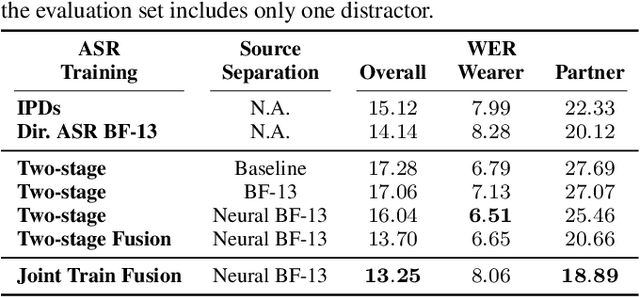
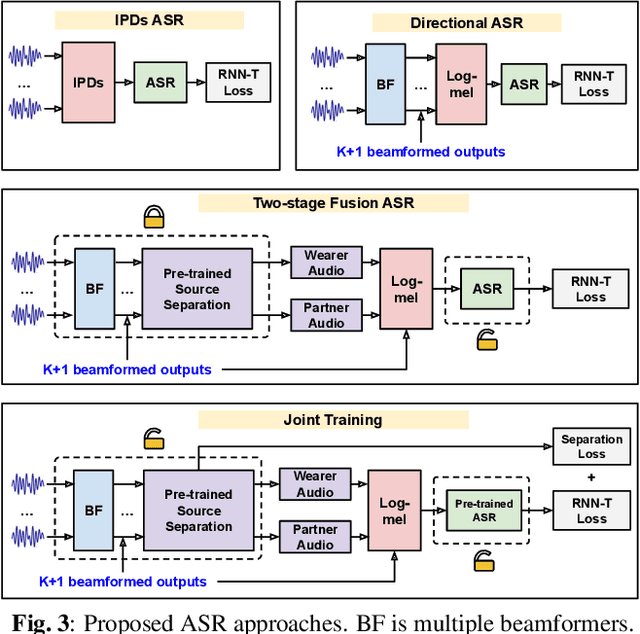
Modern smart glasses leverage advanced audio sensing and machine learning technologies to offer real-time transcribing and captioning services, considerably enriching human experiences in daily communications. However, such systems frequently encounter challenges related to environmental noises, resulting in degradation to speech recognition and speaker change detection. To improve voice quality, this work investigates directional source separation using the multi-microphone array. We first explore multiple beamformers to assist source separation modeling by strengthening the directional properties of speech signals. In addition to relying on predetermined beamformers, we investigate neural beamforming in multi-channel source separation, demonstrating that automatic learning directional characteristics effectively improves separation quality. We further compare the ASR performance leveraging separated outputs to noisy inputs. Our results show that directional source separation benefits ASR for the wearer but not for the conversation partner. Lastly, we perform the joint training of the directional source separation and ASR model, achieving the best overall ASR performance.
DISGO: Automatic End-to-End Evaluation for Scene Text OCR
Aug 25, 2023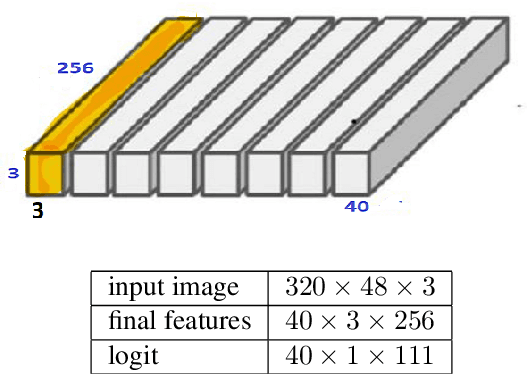


This paper discusses the challenges of optical character recognition (OCR) on natural scenes, which is harder than OCR on documents due to the wild content and various image backgrounds. We propose to uniformly use word error rates (WER) as a new measurement for evaluating scene-text OCR, both end-to-end (e2e) performance and individual system component performances. Particularly for the e2e metric, we name it DISGO WER as it considers Deletion, Insertion, Substitution, and Grouping/Ordering errors. Finally we propose to utilize the concept of super blocks to automatically compute BLEU scores for e2e OCR machine translation. The small SCUT public test set is used to demonstrate WER performance by a modularized OCR system.
Factorized Blank Thresholding for Improved Runtime Efficiency of Neural Transducers
Nov 02, 2022

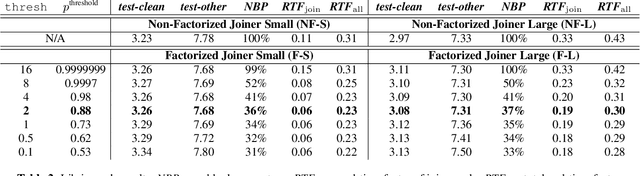
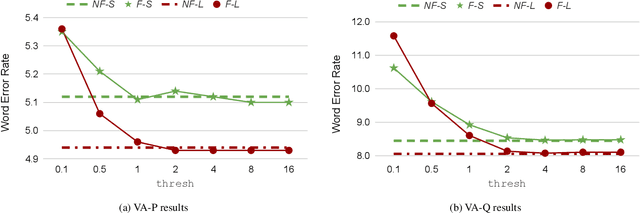
We show how factoring the RNN-T's output distribution can significantly reduce the computation cost and power consumption for on-device ASR inference with no loss in accuracy. With the rise in popularity of neural-transducer type models like the RNN-T for on-device ASR, optimizing RNN-T's runtime efficiency is of great interest. While previous work has primarily focused on the optimization of RNN-T's acoustic encoder and predictor, this paper focuses the attention on the joiner. We show that despite being only a small part of RNN-T, the joiner has a large impact on the overall model's runtime efficiency. We propose to factorize the joiner into blank and non-blank portions for the purpose of skipping the more expensive non-blank computation when the blank probability exceeds a certain threshold. Since the blank probability can be computed very efficiently and the RNN-T output is dominated by blanks, our proposed method leads to a 26-30% decoding speed-up and 43-53% reduction in on-device power consumption, all the while incurring no accuracy degradation and being relatively simple to implement.
An Investigation of Monotonic Transducers for Large-Scale Automatic Speech Recognition
Apr 19, 2022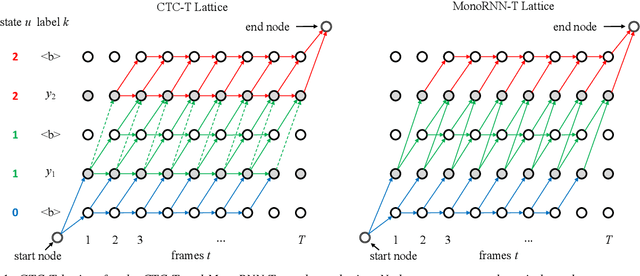
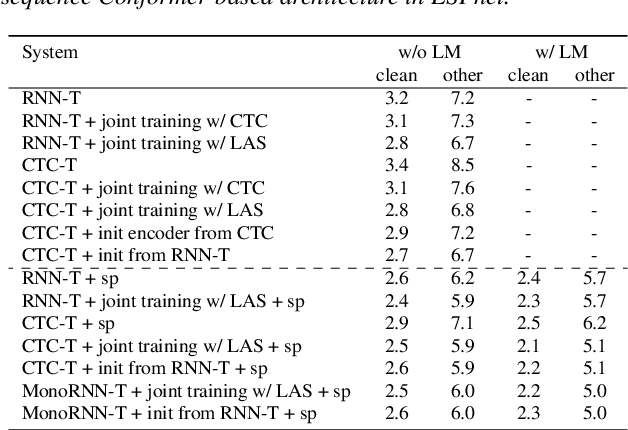
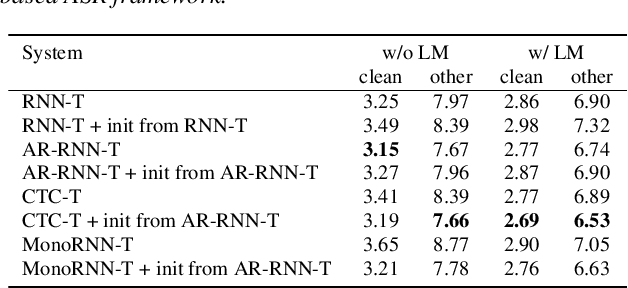
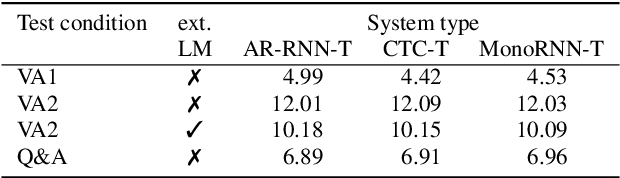
The two most popular loss functions for streaming end-to-end automatic speech recognition (ASR) are the RNN-Transducer (RNN-T) and the connectionist temporal classification (CTC) objectives. Both perform an alignment-free training by marginalizing over all possible alignments, but use different transition rules. Between these two loss types we can classify the monotonic RNN-T (MonoRNN-T) and the recently proposed CTC-like Transducer (CTC-T), which both can be realized using the graph temporal classification-transducer (GTC-T) loss function. Monotonic transducers have a few advantages. First, RNN-T can suffer from runaway hallucination, where a model keeps emitting non-blank symbols without advancing in time, often in an infinite loop. Secondly, monotonic transducers consume exactly one model score per time step and are therefore more compatible and unifiable with traditional FST-based hybrid ASR decoders. However, the MonoRNN-T so far has been found to have worse accuracy than RNN-T. It does not have to be that way, though: By regularizing the training - via joint LAS training or parameter initialization from RNN-T - both MonoRNN-T and CTC-T perform as well - or better - than RNN-T. This is demonstrated for LibriSpeech and for a large-scale in-house data set.
Federated Domain Adaptation for ASR with Full Self-Supervision
Apr 05, 2022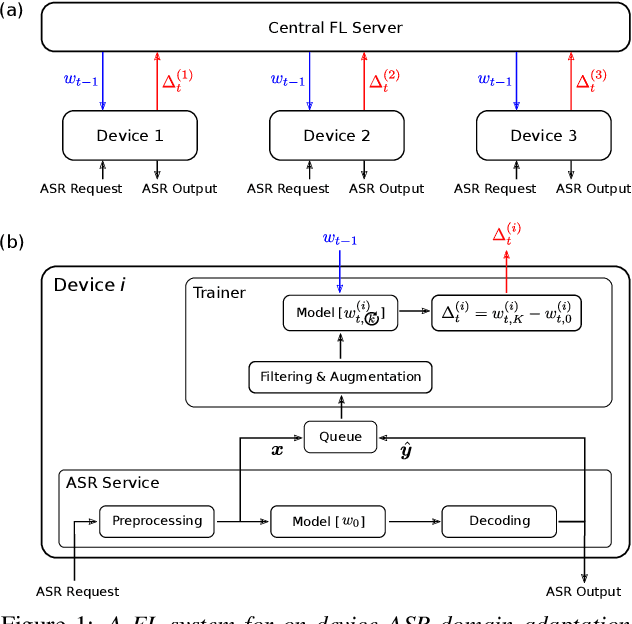
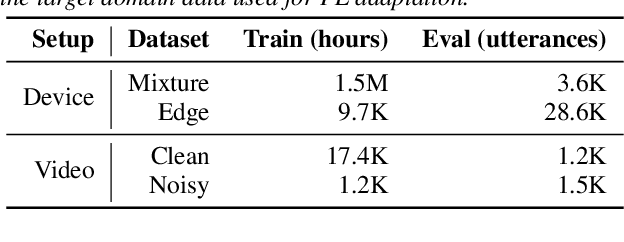
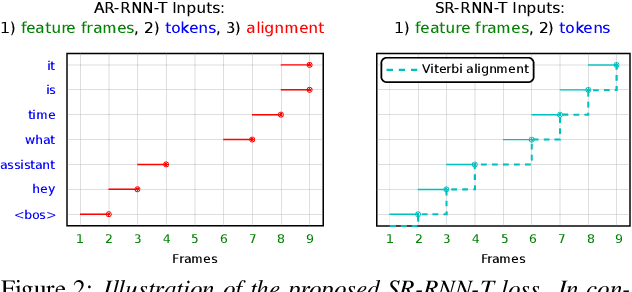
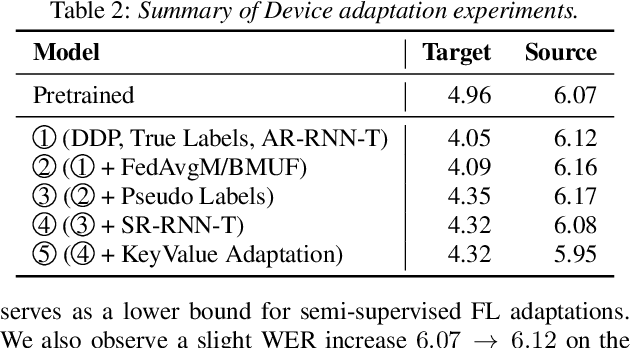
Cross-device federated learning (FL) protects user privacy by collaboratively training a model on user devices, therefore eliminating the need for collecting, storing, and manually labeling user data. While important topics such as the FL training algorithm, non-IID-ness, and Differential Privacy have been well studied in the literature, this paper focuses on two challenges of practical importance for improving on-device ASR: the lack of ground-truth transcriptions and the scarcity of compute resource and network bandwidth on edge devices. First, we propose a FL system for on-device ASR domain adaptation with full self-supervision, which uses self-labeling together with data augmentation and filtering techniques. The system can improve a strong Emformer-Transducer based ASR model pretrained on out-of-domain data, using in-domain audio without any ground-truth transcriptions. Second, to reduce the training cost, we propose a self-restricted RNN Transducer (SR-RNN-T) loss, a variant of alignment-restricted RNN-T that uses Viterbi alignments from self-supervision. To further reduce the compute and network cost, we systematically explore adapting only a subset of weights in the Emformer-Transducer. Our best training recipe achieves a $12.9\%$ relative WER reduction over the strong out-of-domain baseline, which equals $70\%$ of the reduction achievable with full human supervision and centralized training.
Achieving Human Parity on Automatic Chinese to English News Translation
Jun 29, 2018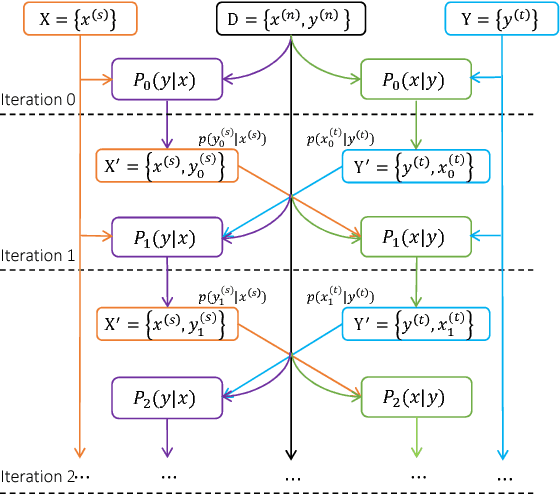

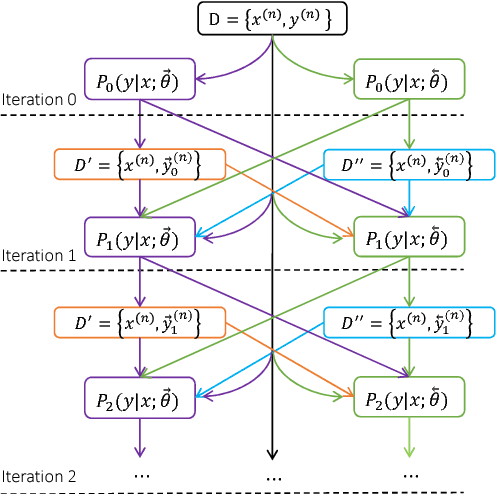

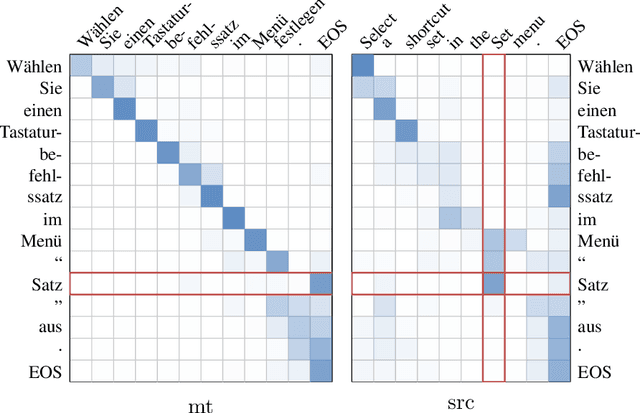
Machine translation has made rapid advances in recent years. Millions of people are using it today in online translation systems and mobile applications in order to communicate across language barriers. The question naturally arises whether such systems can approach or achieve parity with human translations. In this paper, we first address the problem of how to define and accurately measure human parity in translation. We then describe Microsoft's machine translation system and measure the quality of its translations on the widely used WMT 2017 news translation task from Chinese to English. We find that our latest neural machine translation system has reached a new state-of-the-art, and that the translation quality is at human parity when compared to professional human translations. We also find that it significantly exceeds the quality of crowd-sourced non-professional translations.
Marian: Fast Neural Machine Translation in C++
Apr 04, 2018

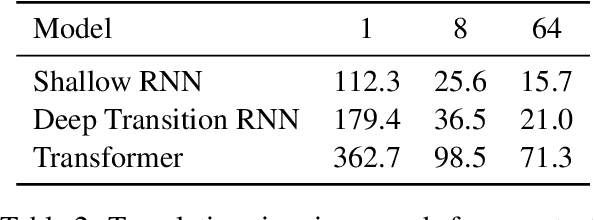
We present Marian, an efficient and self-contained Neural Machine Translation framework with an integrated automatic differentiation engine based on dynamic computation graphs. Marian is written entirely in C++. We describe the design of the encoder-decoder framework and demonstrate that a research-friendly toolkit can achieve high training and translation speed.
Feature Learning in Deep Neural Networks - Studies on Speech Recognition Tasks
Mar 08, 2013
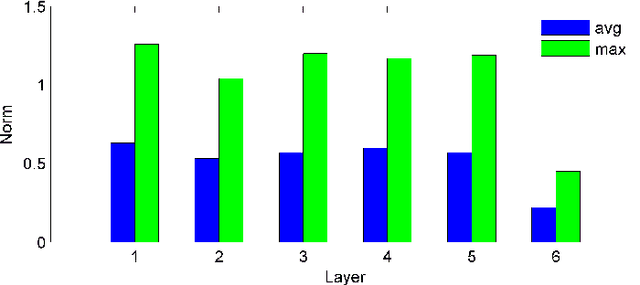
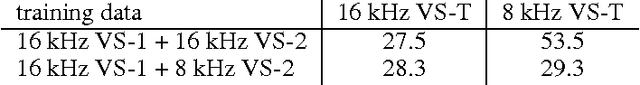
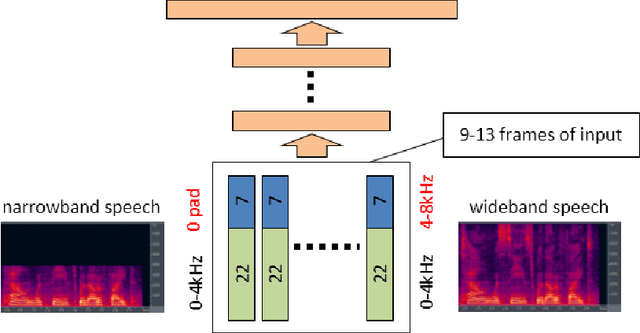
Recent studies have shown that deep neural networks (DNNs) perform significantly better than shallow networks and Gaussian mixture models (GMMs) on large vocabulary speech recognition tasks. In this paper, we argue that the improved accuracy achieved by the DNNs is the result of their ability to extract discriminative internal representations that are robust to the many sources of variability in speech signals. We show that these representations become increasingly insensitive to small perturbations in the input with increasing network depth, which leads to better speech recognition performance with deeper networks. We also show that DNNs cannot extrapolate to test samples that are substantially different from the training examples. If the training data are sufficiently representative, however, internal features learned by the DNN are relatively stable with respect to speaker differences, bandwidth differences, and environment distortion. This enables DNN-based recognizers to perform as well or better than state-of-the-art systems based on GMMs or shallow networks without the need for explicit model adaptation or feature normalization.