 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDonglin Zhan
Meta-Learning Linear Quadratic Regulators: A Policy Gradient MAML Approach for the Model-free LQR
Jan 25, 2024
We investigate the problem of learning Linear Quadratic Regulators (LQR) in a multi-task, heterogeneous, and model-free setting. We characterize the stability and personalization guarantees of a Policy Gradient-based (PG) Model-Agnostic Meta-Learning (MAML) (Finn et al., 2017) approach for the LQR problem under different task-heterogeneity settings. We show that the MAML-LQR approach produces a stabilizing controller close to each task-specific optimal controller up to a task-heterogeneity bias for both model-based and model-free settings. Moreover, in the model-based setting, we show that this controller is achieved with a linear convergence rate, which improves upon sub-linear rates presented in existing MAML-LQR work. In contrast to existing MAML-LQR results, our theoretical guarantees demonstrate that the learned controller can efficiently adapt to unseen LQR tasks.
Meta-Learning with Less Forgetting on Large-Scale Non-Stationary Task Distributions
Sep 03, 2022

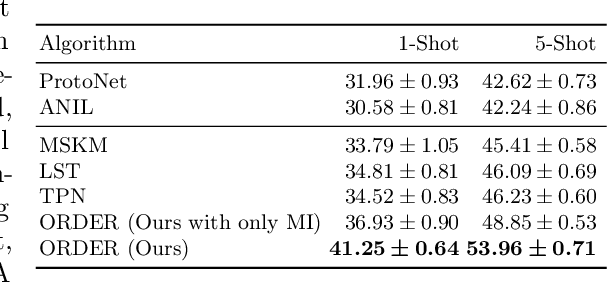
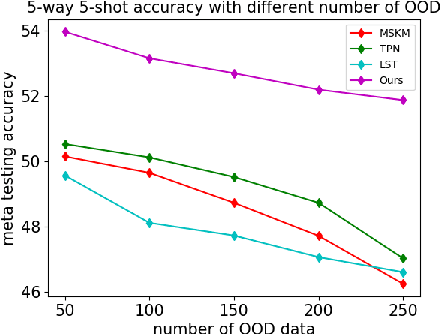
The paradigm of machine intelligence moves from purely supervised learning to a more practical scenario when many loosely related unlabeled data are available and labeled data is scarce. Most existing algorithms assume that the underlying task distribution is stationary. Here we consider a more realistic and challenging setting in that task distributions evolve over time. We name this problem as Semi-supervised meta-learning with Evolving Task diStributions, abbreviated as SETS. Two key challenges arise in this more realistic setting: (i) how to use unlabeled data in the presence of a large amount of unlabeled out-of-distribution (OOD) data; and (ii) how to prevent catastrophic forgetting on previously learned task distributions due to the task distribution shift. We propose an OOD Robust and knowleDge presErved semi-supeRvised meta-learning approach (ORDER), to tackle these two major challenges. Specifically, our ORDER introduces a novel mutual information regularization to robustify the model with unlabeled OOD data and adopts an optimal transport regularization to remember previously learned knowledge in feature space. In addition, we test our method on a very challenging dataset: SETS on large-scale non-stationary semi-supervised task distributions consisting of (at least) 72K tasks. With extensive experiments, we demonstrate the proposed ORDER alleviates forgetting on evolving task distributions and is more robust to OOD data than related strong baselines.
Adaptive Transfer Learning of Multi-View Time Series Classification
Oct 14, 2019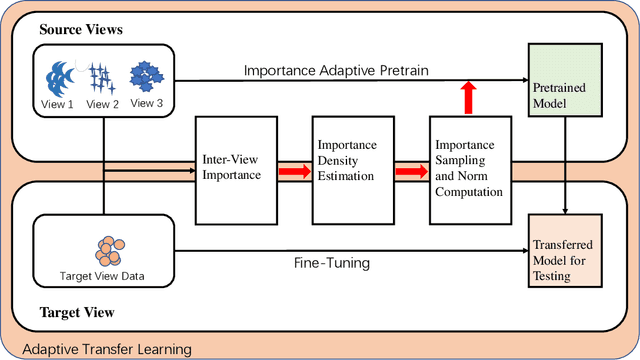


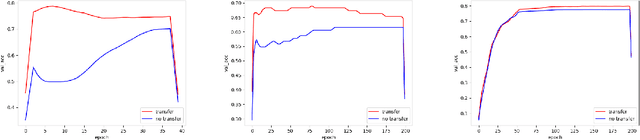
Time Series Classification (TSC) has been an important and challenging task in data mining, especially on multivariate time series and multi-view time series data sets. Meanwhile, transfer learning has been widely applied in computer vision and natural language processing applications to improve deep neural network's generalization capabilities. However, very few previous works applied transfer learning framework to time series mining problems. Particularly, the technique of measuring similarities between source domain and target domain based on dynamic representation such as density estimation with importance sampling has never been combined with transfer learning framework. In this paper, we first proposed a general adaptive transfer learning framework for multi-view time series data, which shows strong ability in storing inter-view importance value in the process of knowledge transfer. Next, we represented inter-view importance through some time series similarity measurements and approximated the posterior distribution in latent space for the importance sampling via density estimation techniques. We then computed the matrix norm of sampled importance value, which controls the degree of knowledge transfer in pre-training process. We further evaluated our work, applied it to many other time series classification tasks, and observed that our architecture maintained desirable generalization ability. Finally, we concluded that our framework could be adapted with deep learning techniques to receive significant model performance improvements.
FIS-GAN: GAN with Flow-based Importance Sampling
Oct 06, 2019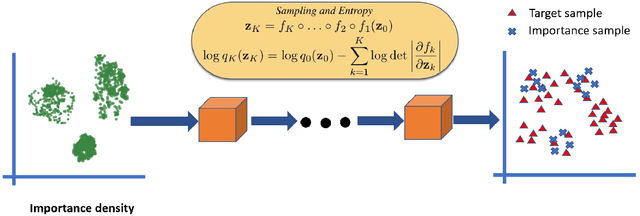
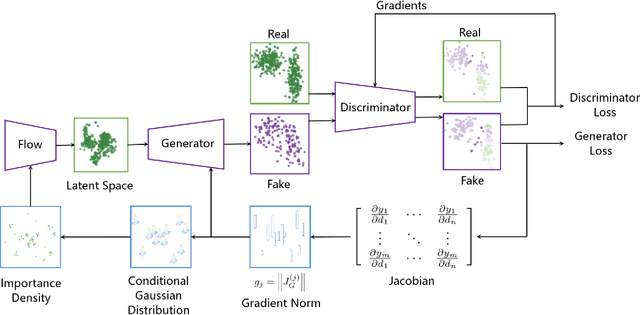
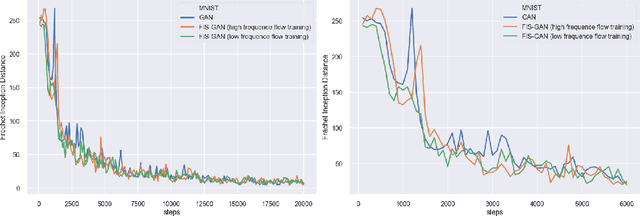
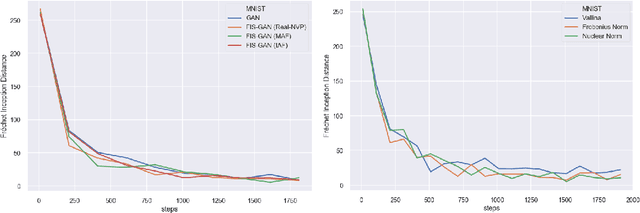
Generative Adversarial Networks (GAN) training process, in most cases, apply uniform and Gaussian sampling methods in latent space, which probably spends most of the computation on examples that can be properly handled and easy to generate. Theoretically, importance sampling speeds up stochastic gradient algorithms for supervised learning by prioritizing training examples. In this paper, we explore the possibility for adapting importance sampling into adversarial learning. We use importance sampling to replace uniform and Gaussian sampling methods in latent space and combine normalizing flow with importance sampling to approximate latent space posterior distribution by density estimation. Empirically, results on MNIST and Fashion-MNIST demonstrate that our method significantly accelerates the convergence of generative process while retaining visual fidelity in generated samples.