 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdward Sun
Towards Improving Learning from Demonstration Algorithms via MCMC Methods
May 03, 2024
Behavioral cloning, or more broadly, learning from demonstrations (LfD) is a priomising direction for robot policy learning in complex scenarios. Albeit being straightforward to implement and data-efficient, behavioral cloning has its own drawbacks, limiting its efficacy in real robot setups. In this work, we take one step towards improving learning from demonstration algorithms by leveraging implicit energy-based policy models. Results suggest that in selected complex robot policy learning scenarios, treating supervised policy learning with an implicit model generally performs better, on average, than commonly used neural network-based explicit models, especially in the cases of approximating potentially discontinuous and multimodal functions.
Data Cross-Segmentation for Improved Generalization in Reinforcement Learning Based Algorithmic Trading
Jul 18, 2023The use of machine learning in algorithmic trading systems is increasingly common. In a typical set-up, supervised learning is used to predict the future prices of assets, and those predictions drive a simple trading and execution strategy. This is quite effective when the predictions have sufficient signal, markets are liquid, and transaction costs are low. However, those conditions often do not hold in thinly traded financial markets and markets for differentiated assets such as real estate or vehicles. In these markets, the trading strategy must consider the long-term effects of taking positions that are relatively more difficult to change. In this work, we propose a Reinforcement Learning (RL) algorithm that trades based on signals from a learned predictive model and addresses these challenges. We test our algorithm on 20+ years of equity data from Bursa Malaysia.
D2S: Document-to-Slide Generation Via Query-Based Text Summarization
May 08, 2021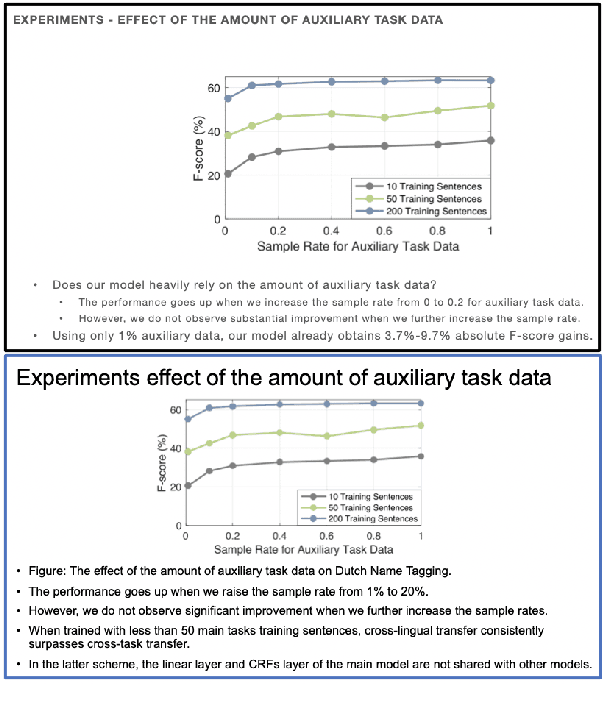


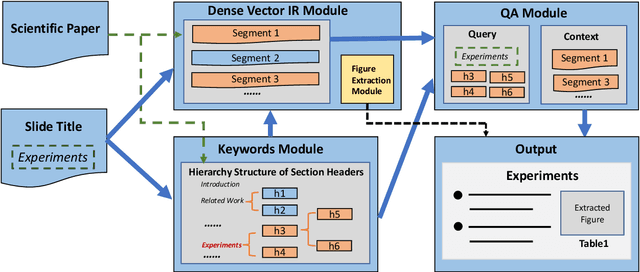
Presentations are critical for communication in all areas of our lives, yet the creation of slide decks is often tedious and time-consuming. There has been limited research aiming to automate the document-to-slides generation process and all face a critical challenge: no publicly available dataset for training and benchmarking. In this work, we first contribute a new dataset, SciDuet, consisting of pairs of papers and their corresponding slides decks from recent years' NLP and ML conferences (e.g., ACL). Secondly, we present D2S, a novel system that tackles the document-to-slides task with a two-step approach: 1) Use slide titles to retrieve relevant and engaging text, figures, and tables; 2) Summarize the retrieved context into bullet points with long-form question answering. Our evaluation suggests that long-form QA outperforms state-of-the-art summarization baselines on both automated ROUGE metrics and qualitative human evaluation.