 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEunjeong Stella Koh
Mugeetion: Musical Interface Using Facial Gesture and Emotion
Oct 07, 2018
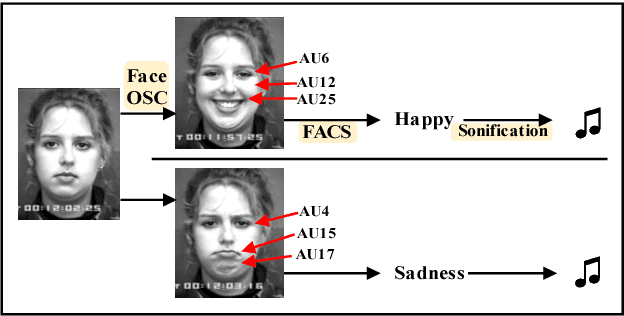
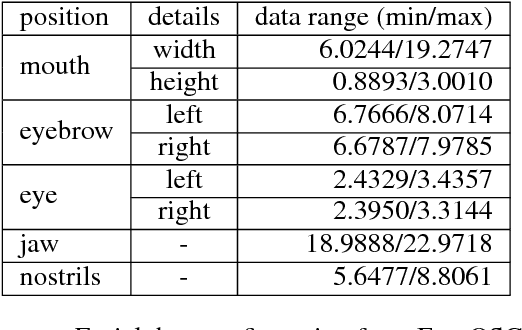
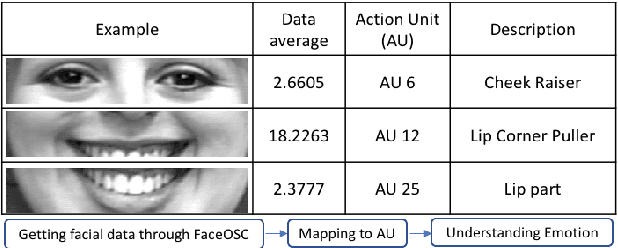

People feel emotions when listening to music. However, emotions are not tangible objects that can be exploited in the music composition process as they are difficult to capture and quantify in algorithms. We present a novel musical interface, Mugeetion, designed to capture occurring instances of emotional states from users' facial gestures and relay that data to associated musical features. Mugeetion can translate qualitative data of emotional states into quantitative data, which can be utilized in the sound generation process. We also presented and tested this work in the exhibition of sound installation, Hearing Seascape, using the audiences' facial expressions. Audiences heard changes in the background sound based on their emotional state. The process contributes multiple research areas, such as gesture tracking systems, emotion-sound modeling, and the connection between sound and facial gesture.
Rethinking Recurrent Latent Variable Model for Music Composition
Oct 07, 2018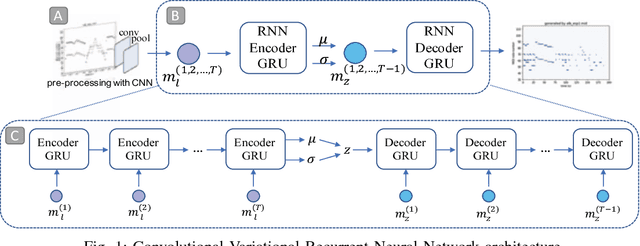
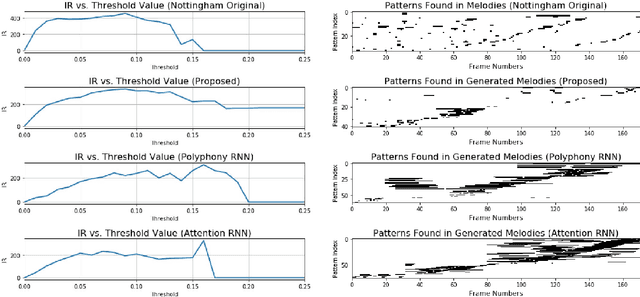

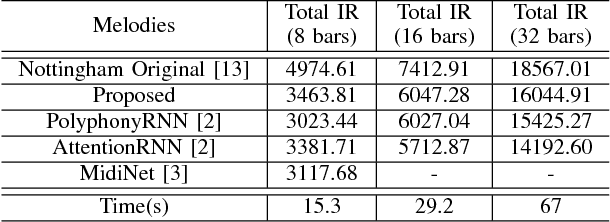
We present a model for capturing musical features and creating novel sequences of music, called the Convolutional Variational Recurrent Neural Network. To generate sequential data, the model uses an encoder-decoder architecture with latent probabilistic connections to capture the hidden structure of music. Using the sequence-to-sequence model, our generative model can exploit samples from a prior distribution and generate a longer sequence of music. We compare the performance of our proposed model with other types of Neural Networks using the criteria of Information Rate that is implemented by Variable Markov Oracle, a method that allows statistical characterization of musical information dynamics and detection of motifs in a song. Our results suggest that the proposed model has a better statistical resemblance to the musical structure of the training data, which improves the creation of new sequences of music in the style of the originals.