 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDustin Wright
Understanding Fine-grained Distortions in Reports of Scientific Findings
Feb 19, 2024
Distorted science communication harms individuals and society as it can lead to unhealthy behavior change and decrease trust in scientific institutions. Given the rapidly increasing volume of science communication in recent years, a fine-grained understanding of how findings from scientific publications are reported to the general public, and methods to detect distortions from the original work automatically, are crucial. Prior work focused on individual aspects of distortions or worked with unpaired data. In this work, we make three foundational contributions towards addressing this problem: (1) annotating 1,600 instances of scientific findings from academic papers paired with corresponding findings as reported in news articles and tweets wrt. four characteristics: causality, certainty, generality and sensationalism; (2) establishing baselines for automatically detecting these characteristics; and (3) analyzing the prevalence of changes in these characteristics in both human-annotated and large-scale unlabeled data. Our results show that scientific findings frequently undergo subtle distortions when reported. Tweets distort findings more often than science news reports. Detecting fine-grained distortions automatically poses a challenging task. In our experiments, fine-tuned task-specific models consistently outperform few-shot LLM prompting.
Efficiency is Not Enough: A Critical Perspective of Environmentally Sustainable AI
Sep 05, 2023Artificial Intelligence (AI) is currently spearheaded by machine learning (ML) methods such as deep learning (DL) which have accelerated progress on many tasks thought to be out of reach of AI. These ML methods can often be compute hungry, energy intensive, and result in significant carbon emissions, a known driver of anthropogenic climate change. Additionally, the platforms on which ML systems run are associated with environmental impacts including and beyond carbon emissions. The solution lionized by both industry and the ML community to improve the environmental sustainability of ML is to increase the efficiency with which ML systems operate in terms of both compute and energy consumption. In this perspective, we argue that efficiency alone is not enough to make ML as a technology environmentally sustainable. We do so by presenting three high level discrepancies between the effect of efficiency on the environmental sustainability of ML when considering the many variables which it interacts with. In doing so, we comprehensively demonstrate, at multiple levels of granularity both technical and non-technical reasons, why efficiency is not enough to fully remedy the environmental impacts of ML. Based on this, we present and argue for systems thinking as a viable path towards improving the environmental sustainability of ML holistically.
Multi-View Knowledge Distillation from Crowd Annotations for Out-of-Domain Generalization
Dec 19, 2022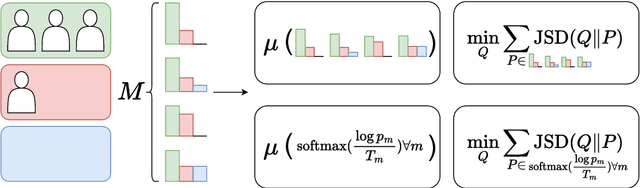


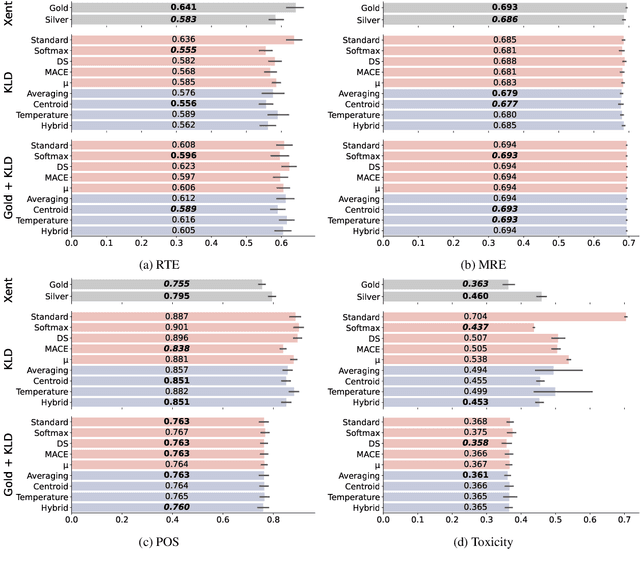
Selecting an effective training signal for tasks in natural language processing is difficult: collecting expert annotations is expensive, and crowd-sourced annotations may not be reliable. At the same time, recent work in machine learning has demonstrated that learning from soft-labels acquired from crowd annotations can be effective, especially when there is distribution shift in the test set. However, the best method for acquiring these soft labels is inconsistent across tasks. This paper proposes new methods for acquiring soft-labels from crowd-annotations by aggregating the distributions produced by existing methods. In particular, we propose to find a distribution over classes by learning from multiple-views of crowd annotations via temperature scaling and finding the Jensen-Shannon centroid of their distributions. We demonstrate that using these aggregation methods leads to best or near-best performance across four NLP tasks on out-of-domain test sets, mitigating fluctuations in performance when using the constituent methods on their own. Additionally, these methods result in best or near-best uncertainty estimation across tasks. We argue that aggregating different views of crowd-annotations as soft-labels is an effective way to ensure performance which is as good or better than the best individual view, which is useful given the inconsistency in performance of the individual methods.
Revisiting Softmax for Uncertainty Approximation in Text Classification
Oct 25, 2022
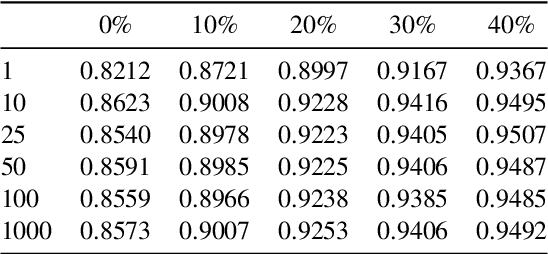
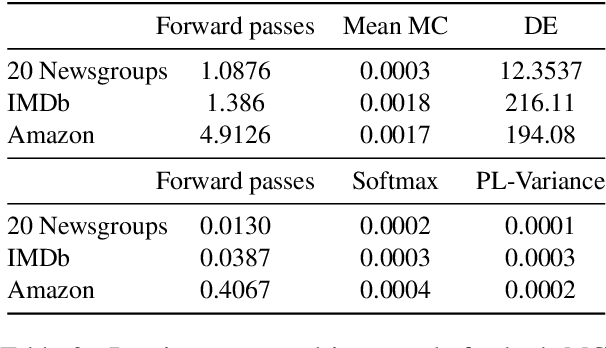
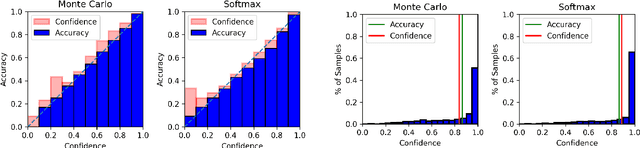
Uncertainty approximation in text classification is an important area with applications in domain adaptation and interpretability. The most widely used uncertainty approximation method is Monte Carlo Dropout, which is computationally expensive as it requires multiple forward passes through the model. A cheaper alternative is to simply use a softmax to estimate model uncertainty. However, prior work has indicated that the softmax can generate overconfident uncertainty estimates and can thus be tricked into producing incorrect predictions. In this paper, we perform a thorough empirical analysis of both methods on five datasets with two base neural architectures in order to reveal insight into the trade-offs between the two. We compare the methods' uncertainty approximations and downstream text classification performance, while weighing their performance against their computational complexity as a cost-benefit analysis, by measuring runtime (cost) and the downstream performance (benefit). We find that, while Monte Carlo produces the best uncertainty approximations, using a simple softmax leads to competitive uncertainty estimation for text classification at a much lower computational cost, suggesting that softmax can in fact be a sufficient uncertainty estimate when computational resources are a concern.
Modeling Information Change in Science Communication with Semantically Matched Paraphrases
Oct 24, 2022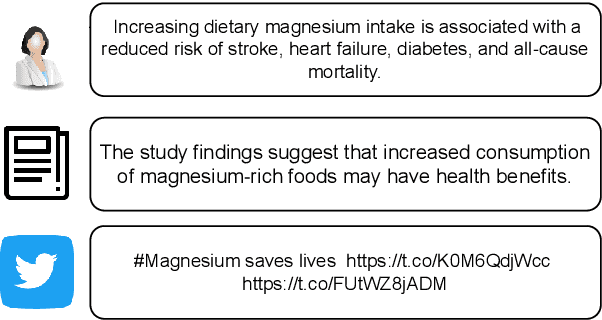


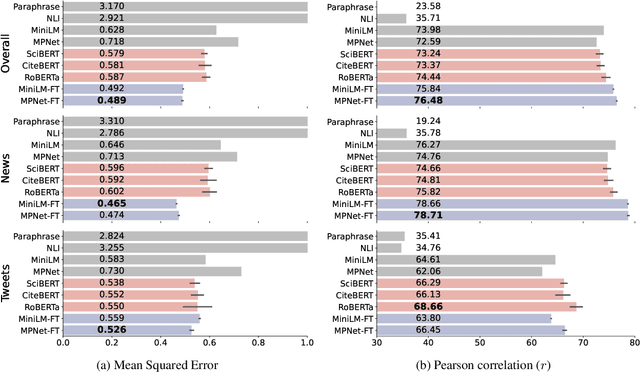
Whether the media faithfully communicate scientific information has long been a core issue to the science community. Automatically identifying paraphrased scientific findings could enable large-scale tracking and analysis of information changes in the science communication process, but this requires systems to understand the similarity between scientific information across multiple domains. To this end, we present the SCIENTIFIC PARAPHRASE AND INFORMATION CHANGE DATASET (SPICED), the first paraphrase dataset of scientific findings annotated for degree of information change. SPICED contains 6,000 scientific finding pairs extracted from news stories, social media discussions, and full texts of original papers. We demonstrate that SPICED poses a challenging task and that models trained on SPICED improve downstream performance on evidence retrieval for fact checking of real-world scientific claims. Finally, we show that models trained on SPICED can reveal large-scale trends in the degrees to which people and organizations faithfully communicate new scientific findings. Data, code, and pre-trained models are available at http://www.copenlu.com/publication/2022_emnlp_wright/.
Generating Scientific Claims for Zero-Shot Scientific Fact Checking
Mar 24, 2022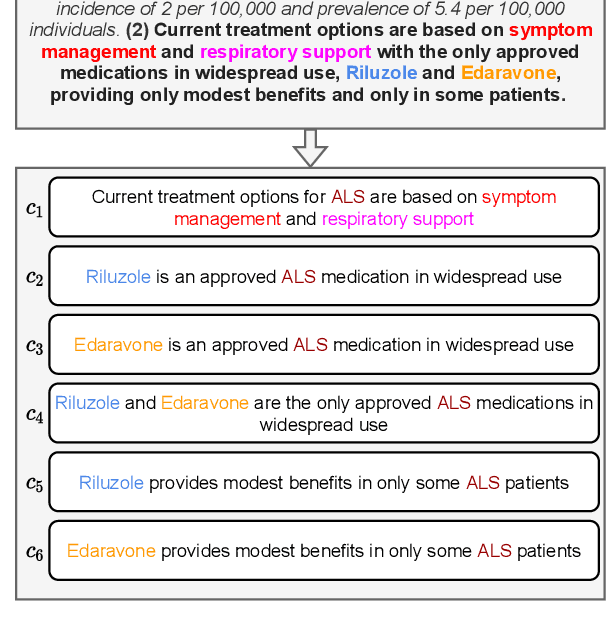
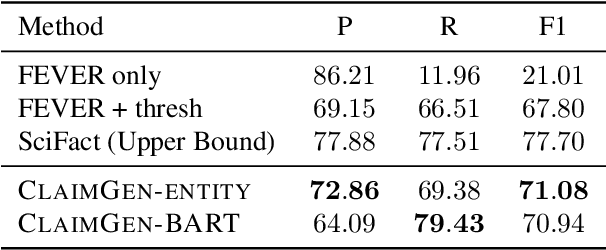
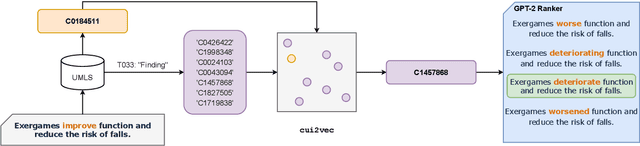

Automated scientific fact checking is difficult due to the complexity of scientific language and a lack of significant amounts of training data, as annotation requires domain expertise. To address this challenge, we propose scientific claim generation, the task of generating one or more atomic and verifiable claims from scientific sentences, and demonstrate its usefulness in zero-shot fact checking for biomedical claims. We propose CLAIMGEN-BART, a new supervised method for generating claims supported by the literature, as well as KBIN, a novel method for generating claim negations. Additionally, we adapt an existing unsupervised entity-centric method of claim generation to biomedical claims, which we call CLAIMGEN-ENTITY. Experiments on zero-shot fact checking demonstrate that both CLAIMGEN-ENTITY and CLAIMGEN-BART, coupled with KBIN, achieve up to 90% performance of fully supervised models trained on manually annotated claims and evidence. A rigorous evaluation study demonstrates significant improvement in generated claim and negation quality over existing baselines
Semi-Supervised Exaggeration Detection of Health Science Press Releases
Aug 30, 2021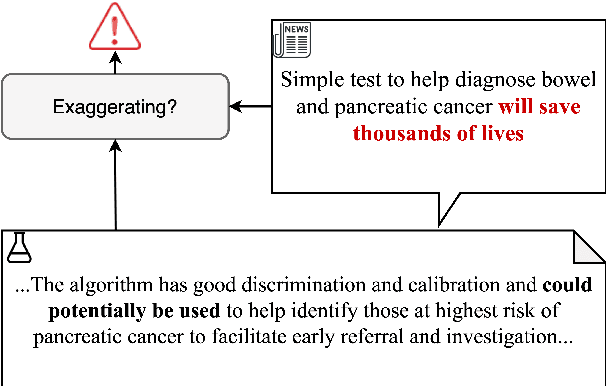

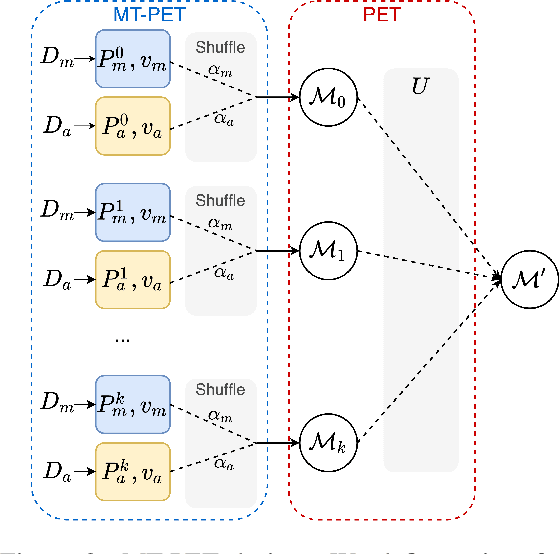
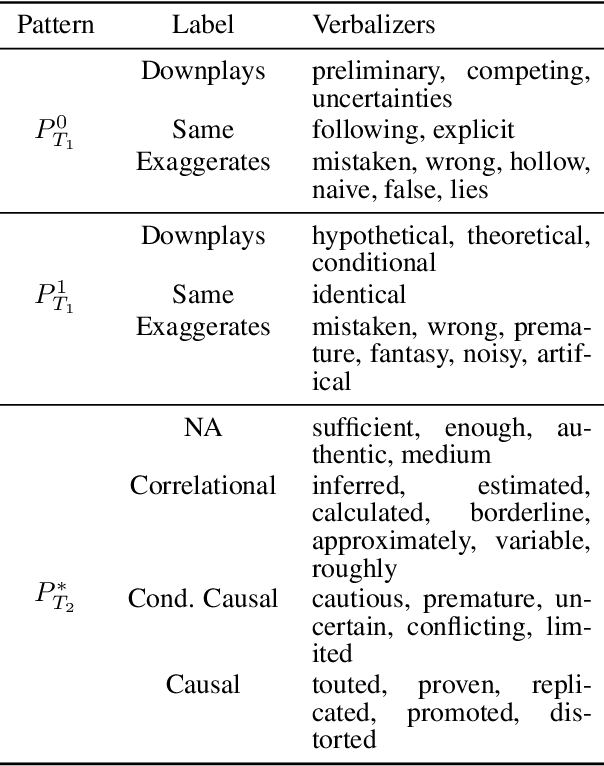
Public trust in science depends on honest and factual communication of scientific papers. However, recent studies have demonstrated a tendency of news media to misrepresent scientific papers by exaggerating their findings. Given this, we present a formalization of and study into the problem of exaggeration detection in science communication. While there are an abundance of scientific papers and popular media articles written about them, very rarely do the articles include a direct link to the original paper, making data collection challenging. We address this by curating a set of labeled press release/abstract pairs from existing expert annotated studies on exaggeration in press releases of scientific papers suitable for benchmarking the performance of machine learning models on the task. Using limited data from this and previous studies on exaggeration detection in science, we introduce MT-PET, a multi-task version of Pattern Exploiting Training (PET), which leverages knowledge from complementary cloze-style QA tasks to improve few-shot learning. We demonstrate that MT-PET outperforms PET and supervised learning both when data is limited, as well as when there is an abundance of data for the main task.
CiteWorth: Cite-Worthiness Detection for Improved Scientific Document Understanding
May 25, 2021
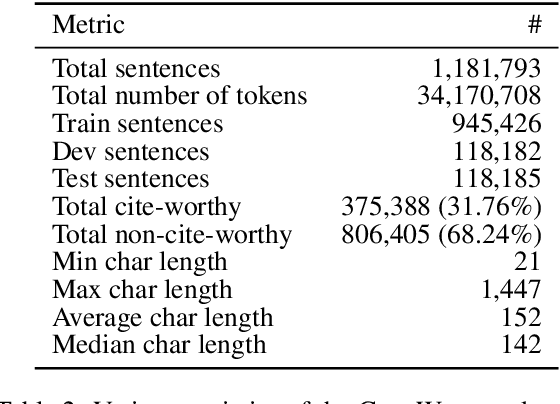

Scientific document understanding is challenging as the data is highly domain specific and diverse. However, datasets for tasks with scientific text require expensive manual annotation and tend to be small and limited to only one or a few fields. At the same time, scientific documents contain many potential training signals, such as citations, which can be used to build large labelled datasets. Given this, we present an in-depth study of cite-worthiness detection in English, where a sentence is labelled for whether or not it cites an external source. To accomplish this, we introduce CiteWorth, a large, contextualized, rigorously cleaned labelled dataset for cite-worthiness detection built from a massive corpus of extracted plain-text scientific documents. We show that CiteWorth is high-quality, challenging, and suitable for studying problems such as domain adaptation. Our best performing cite-worthiness detection model is a paragraph-level contextualized sentence labelling model based on Longformer, exhibiting a 5 F1 point improvement over SciBERT which considers only individual sentences. Finally, we demonstrate that language model fine-tuning with cite-worthiness as a secondary task leads to improved performance on downstream scientific document understanding tasks.
* 12 pages, 9 tables, 1 figure
Longitudinal Citation Prediction using Temporal Graph Neural Networks
Dec 10, 2020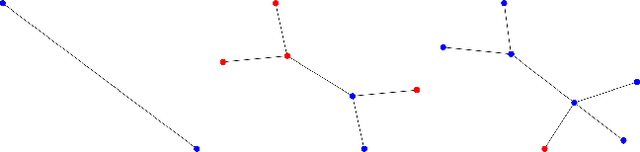
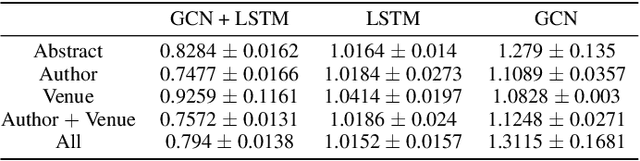
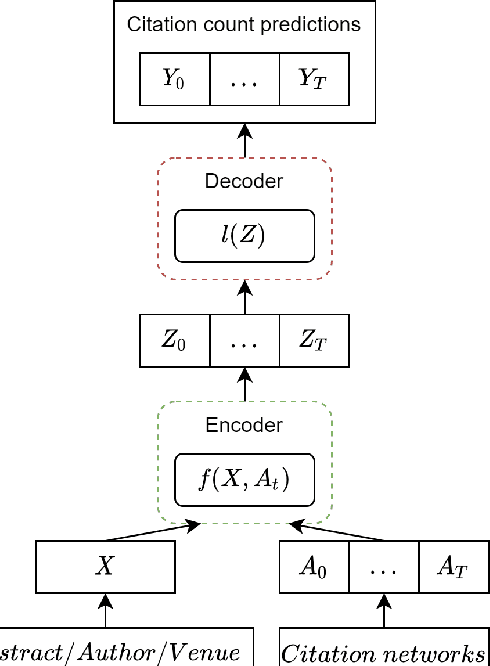
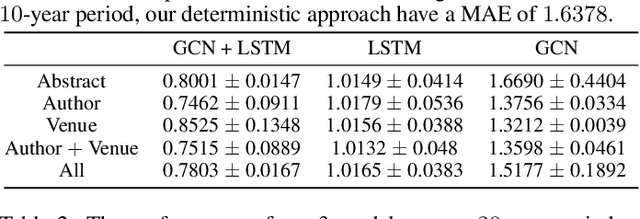
Citation count prediction is the task of predicting the number of citations a paper has gained after a period of time. Prior work viewed this as a static prediction task. As papers and their citations evolve over time, considering the dynamics of the number of citations a paper will receive would seem logical. Here, we introduce the task of sequence citation prediction, where the goal is to accurately predict the trajectory of the number of citations a scholarly work receives over time. We propose to view papers as a structured network of citations, allowing us to use topological information as a learning signal. Additionally, we learn how this dynamic citation network changes over time and the impact of paper meta-data such as authors, venues and abstracts. To approach the introduced task, we derive a dynamic citation network from Semantic Scholar which spans over 42 years. We present a model which exploits topological and temporal information using graph convolution networks paired with sequence prediction, and compare it against multiple baselines, testing the importance of topological and temporal information and analyzing model performance. Our experiments show that leveraging both the temporal and topological information greatly increases the performance of predicting citation counts over time.
Generating Label Cohesive and Well-Formed Adversarial Claims
Sep 17, 2020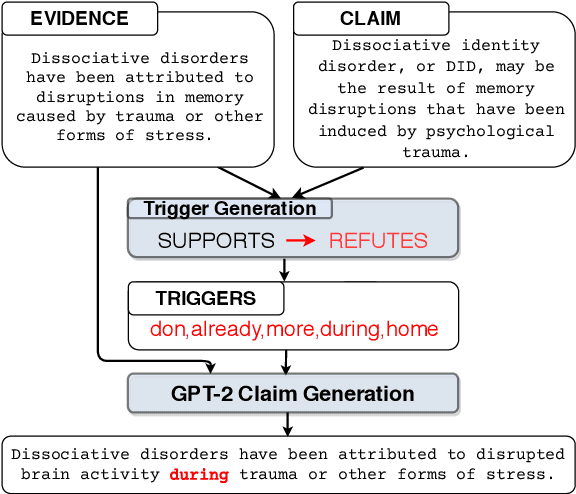
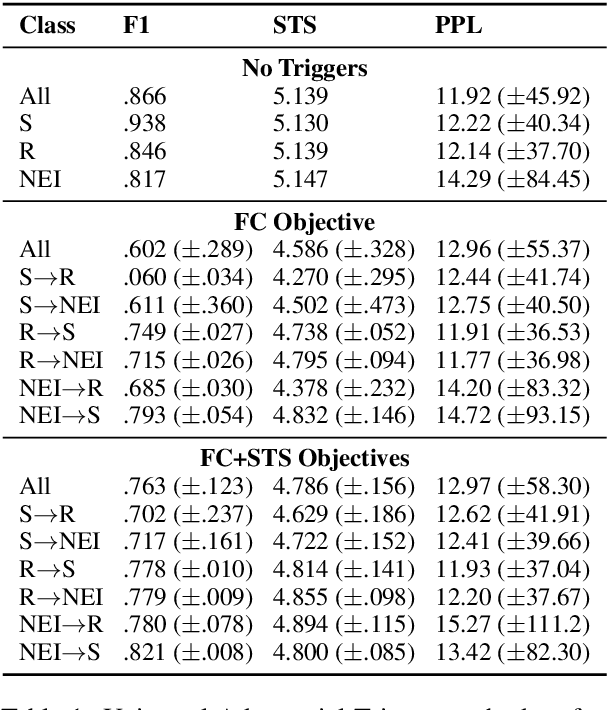
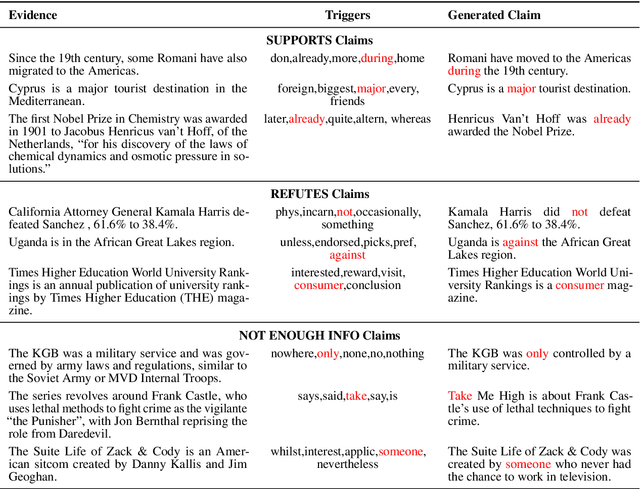
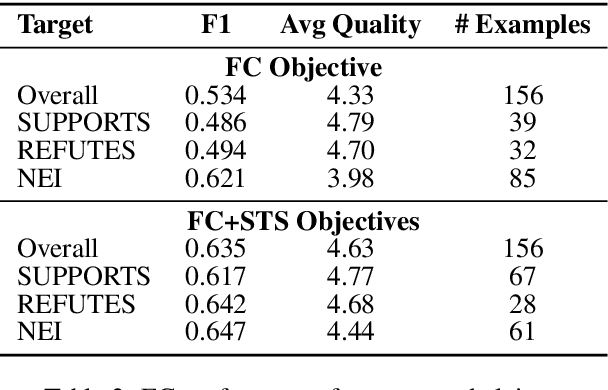
Adversarial attacks reveal important vulnerabilities and flaws of trained models. One potent type of attack are universal adversarial triggers, which are individual n-grams that, when appended to instances of a class under attack, can trick a model into predicting a target class. However, for inference tasks such as fact checking, these triggers often inadvertently invert the meaning of instances they are inserted in. In addition, such attacks produce semantically nonsensical inputs, as they simply concatenate triggers to existing samples. Here, we investigate how to generate adversarial attacks against fact checking systems that preserve the ground truth meaning and are semantically valid. We extend the HotFlip attack algorithm used for universal trigger generation by jointly minimising the target class loss of a fact checking model and the entailment class loss of an auxiliary natural language inference model. We then train a conditional language model to generate semantically valid statements, which include the found universal triggers. We find that the generated attacks maintain the directionality and semantic validity of the claim better than previous work.