 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePepa Atanasova
Revealing the Parametric Knowledge of Language Models: A Unified Framework for Attribution Methods
Apr 29, 2024
Language Models (LMs) acquire parametric knowledge from their training process, embedding it within their weights. The increasing scalability of LMs, however, poses significant challenges for understanding a model's inner workings and further for updating or correcting this embedded knowledge without the significant cost of retraining. This underscores the importance of unveiling exactly what knowledge is stored and its association with specific model components. Instance Attribution (IA) and Neuron Attribution (NA) offer insights into this training-acquired knowledge, though they have not been compared systematically. Our study introduces a novel evaluation framework to quantify and compare the knowledge revealed by IA and NA. To align the results of the methods we introduce the attribution method NA-Instances to apply NA for retrieving influential training instances, and IA-Neurons to discover important neurons of influential instances discovered by IA. We further propose a comprehensive list of faithfulness tests to evaluate the comprehensiveness and sufficiency of the explanations provided by both methods. Through extensive experiments and analysis, we demonstrate that NA generally reveals more diverse and comprehensive information regarding the LM's parametric knowledge compared to IA. Nevertheless, IA provides unique and valuable insights into the LM's parametric knowledge, which are not revealed by NA. Our findings further suggest the potential of a synergistic approach of combining the diverse findings of IA and NA for a more holistic understanding of an LM's parametric knowledge.
Explaining Interactions Between Text Spans
Oct 20, 2023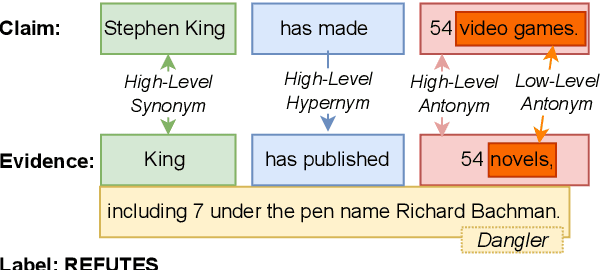
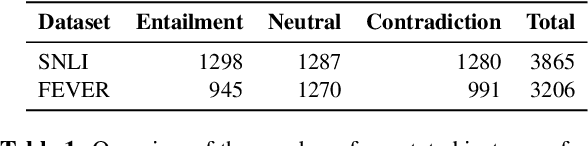
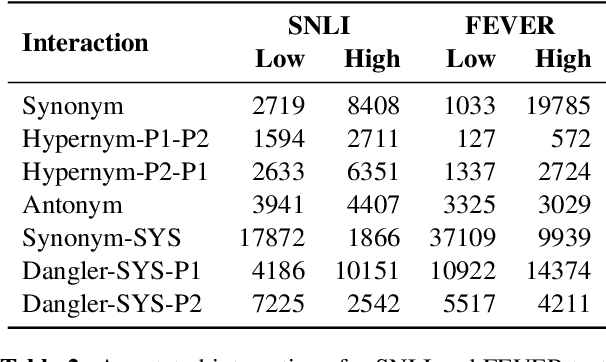
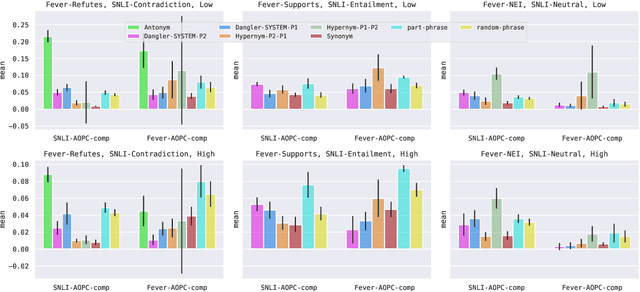
Reasoning over spans of tokens from different parts of the input is essential for natural language understanding (NLU) tasks such as fact-checking (FC), machine reading comprehension (MRC) or natural language inference (NLI). However, existing highlight-based explanations primarily focus on identifying individual important tokens or interactions only between adjacent tokens or tuples of tokens. Most notably, there is a lack of annotations capturing the human decision-making process w.r.t. the necessary interactions for informed decision-making in such tasks. To bridge this gap, we introduce SpanEx, a multi-annotator dataset of human span interaction explanations for two NLU tasks: NLI and FC. We then investigate the decision-making processes of multiple fine-tuned large language models in terms of the employed connections between spans in separate parts of the input and compare them to the human reasoning processes. Finally, we present a novel community detection based unsupervised method to extract such interaction explanations from a model's inner workings.
bgGLUE: A Bulgarian General Language Understanding Evaluation Benchmark
Jun 07, 2023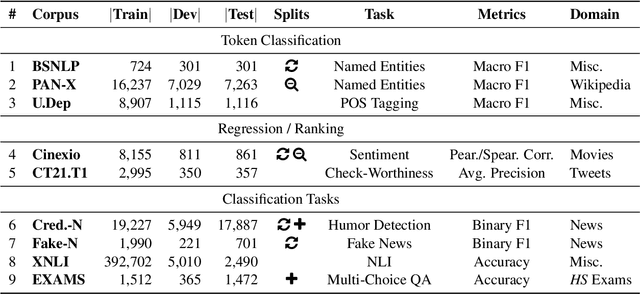
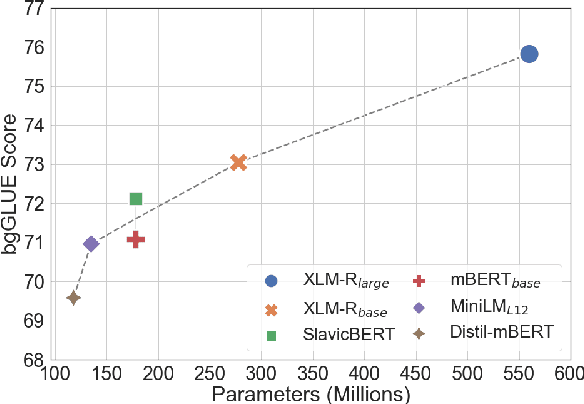

We present bgGLUE(Bulgarian General Language Understanding Evaluation), a benchmark for evaluating language models on Natural Language Understanding (NLU) tasks in Bulgarian. Our benchmark includes NLU tasks targeting a variety of NLP problems (e.g., natural language inference, fact-checking, named entity recognition, sentiment analysis, question answering, etc.) and machine learning tasks (sequence labeling, document-level classification, and regression). We run the first systematic evaluation of pre-trained language models for Bulgarian, comparing and contrasting results across the nine tasks in the benchmark. The evaluation results show strong performance on sequence labeling tasks, but there is a lot of room for improvement for tasks that require more complex reasoning. We make bgGLUE publicly available together with the fine-tuning and the evaluation code, as well as a public leaderboard at https://bgglue.github.io/, and we hope that it will enable further advancements in developing NLU models for Bulgarian.
* Accepted to ACL 2023 (Main Conference)
Faithfulness Tests for Natural Language Explanations
May 29, 2023
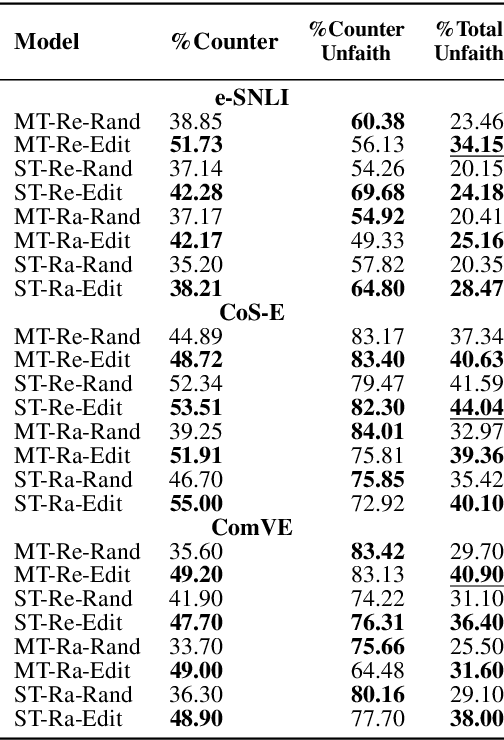
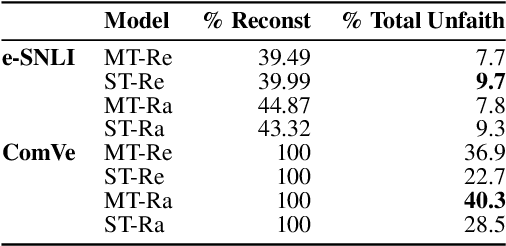
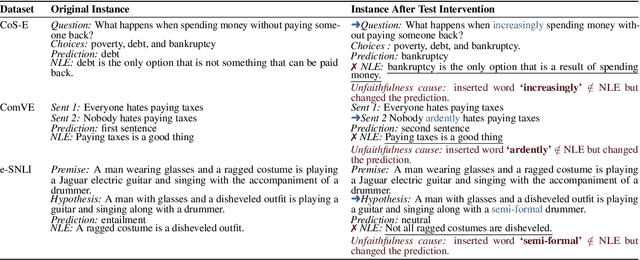
Explanations of neural models aim to reveal a model's decision-making process for its predictions. However, recent work shows that current methods giving explanations such as saliency maps or counterfactuals can be misleading, as they are prone to present reasons that are unfaithful to the model's inner workings. This work explores the challenging question of evaluating the faithfulness of natural language explanations (NLEs). To this end, we present two tests. First, we propose a counterfactual input editor for inserting reasons that lead to counterfactual predictions but are not reflected by the NLEs. Second, we reconstruct inputs from the reasons stated in the generated NLEs and check how often they lead to the same predictions. Our tests can evaluate emerging NLE models, proving a fundamental tool in the development of faithful NLEs.
Accountable and Explainable Methods for Complex Reasoning over Text
Nov 09, 2022

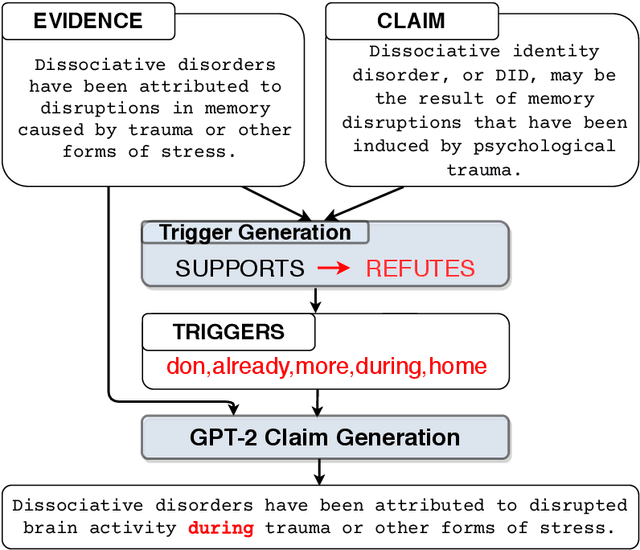
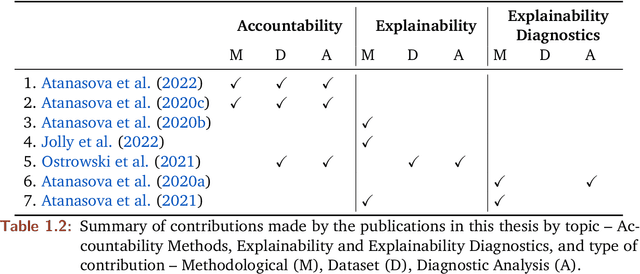
A major concern of Machine Learning (ML) models is their opacity. They are deployed in an increasing number of applications where they often operate as black boxes that do not provide explanations for their predictions. Among others, the potential harms associated with the lack of understanding of the models' rationales include privacy violations, adversarial manipulations, and unfair discrimination. As a result, the accountability and transparency of ML models have been posed as critical desiderata by works in policy and law, philosophy, and computer science. In computer science, the decision-making process of ML models has been studied by developing accountability and transparency methods. Accountability methods, such as adversarial attacks and diagnostic datasets, expose vulnerabilities of ML models that could lead to malicious manipulations or systematic faults in their predictions. Transparency methods explain the rationales behind models' predictions gaining the trust of relevant stakeholders and potentially uncovering mistakes and unfairness in models' decisions. To this end, transparency methods have to meet accountability requirements as well, e.g., being robust and faithful to the underlying rationales of a model. This thesis presents my research that expands our collective knowledge in the areas of accountability and transparency of ML models developed for complex reasoning tasks over text.
Fact Checking with Insufficient Evidence
Apr 05, 2022



Automating the fact checking (FC) process relies on information obtained from external sources. In this work, we posit that it is crucial for FC models to make veracity predictions only when there is sufficient evidence and otherwise indicate when it is not enough. To this end, we are the first to study what information FC models consider sufficient by introducing a novel task and advancing it with three main contributions. First, we conduct an in-depth empirical analysis of the task with a new fluency-preserving method for omitting information from the evidence at the constituent and sentence level. We identify when models consider the remaining evidence (in)sufficient for FC, based on three trained models with different Transformer architectures and three FC datasets. Second, we ask annotators whether the omitted evidence was important for FC, resulting in a novel diagnostic dataset, SufficientFacts, for FC with omitted evidence. We find that models are least successful in detecting missing evidence when adverbial modifiers are omitted (21% accuracy), whereas it is easiest for omitted date modifiers (63% accuracy). Finally, we propose a novel data augmentation strategy for contrastive self-learning of missing evidence by employing the proposed omission method combined with tri-training. It improves performance for Evidence Sufficiency Prediction by up to 17.8 F1 score, which in turn improves FC performance by up to 2.6 F1 score.
Generating Fluent Fact Checking Explanations with Unsupervised Post-Editing
Dec 13, 2021

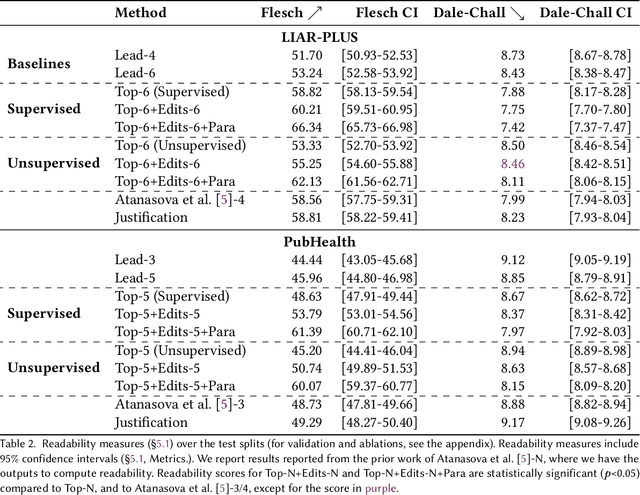
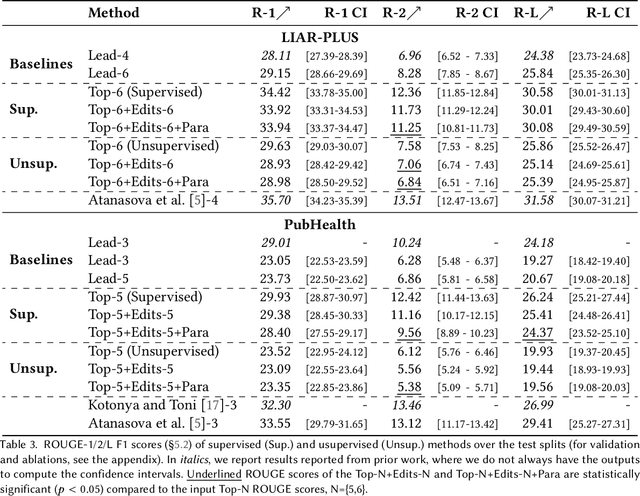
Fact-checking systems have become important tools to verify fake and misguiding news. These systems become more trustworthy when human-readable explanations accompany the veracity labels. However, manual collection of such explanations is expensive and time-consuming. Recent works frame explanation generation as extractive summarization, and propose to automatically select a sufficient subset of the most important facts from the ruling comments (RCs) of a professional journalist to obtain fact-checking explanations. However, these explanations lack fluency and sentence coherence. In this work, we present an iterative edit-based algorithm that uses only phrase-level edits to perform unsupervised post-editing of disconnected RCs. To regulate our editing algorithm, we use a scoring function with components including fluency and semantic preservation. In addition, we show the applicability of our approach in a completely unsupervised setting. We experiment with two benchmark datasets, LIAR-PLUS and PubHealth. We show that our model generates explanations that are fluent, readable, non-redundant, and cover important information for the fact check.
Overview of the CLEF-2019 CheckThat!: Automatic Identification and Verification of Claims
Sep 25, 2021
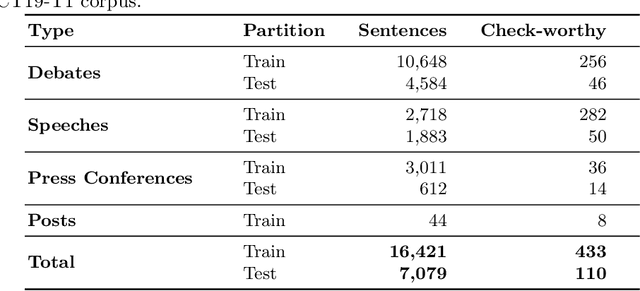


We present an overview of the second edition of the CheckThat! Lab at CLEF 2019. The lab featured two tasks in two different languages: English and Arabic. Task 1 (English) challenged the participating systems to predict which claims in a political debate or speech should be prioritized for fact-checking. Task 2 (Arabic) asked to (A) rank a given set of Web pages with respect to a check-worthy claim based on their usefulness for fact-checking that claim, (B) classify these same Web pages according to their degree of usefulness for fact-checking the target claim, (C) identify useful passages from these pages, and (D) use the useful pages to predict the claim's factuality. CheckThat! provided a full evaluation framework, consisting of data in English (derived from fact-checking sources) and Arabic (gathered and annotated from scratch) and evaluation based on mean average precision (MAP) and normalized discounted cumulative gain (nDCG) for ranking, and F1 for classification. A total of 47 teams registered to participate in this lab, and fourteen of them actually submitted runs (compared to nine last year). The evaluation results show that the most successful approaches to Task 1 used various neural networks and logistic regression. As for Task 2, learning-to-rank was used by the highest scoring runs for subtask A, while different classifiers were used in the other subtasks. We release to the research community all datasets from the lab as well as the evaluation scripts, which should enable further research in the important tasks of check-worthiness estimation and automatic claim verification.
* Check-worthiness Estimation, Fact-Checking, Veracity, Evidence-based Verification, Fake News Detection, Computational Journalism, Disinformation, Misinformation. arXiv admin note: text overlap with arXiv:2012.09263 by other authors
Diagnostics-Guided Explanation Generation
Sep 08, 2021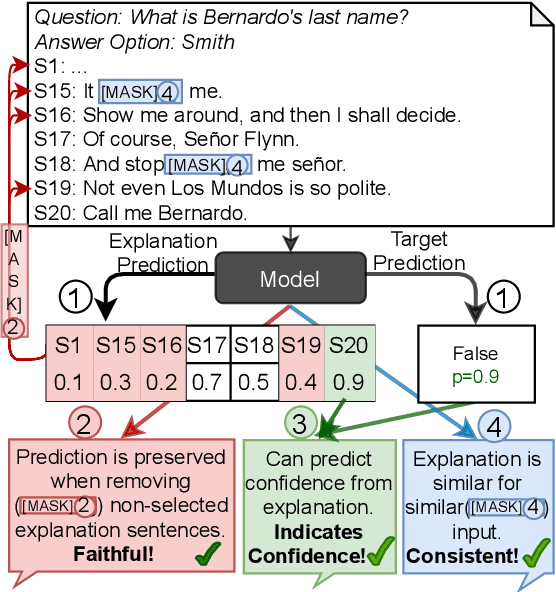
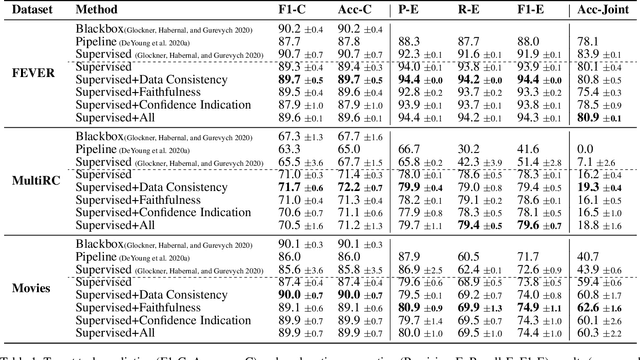
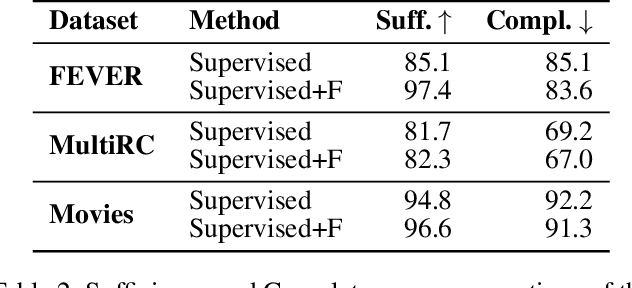

Explanations shed light on a machine learning model's rationales and can aid in identifying deficiencies in its reasoning process. Explanation generation models are typically trained in a supervised way given human explanations. When such annotations are not available, explanations are often selected as those portions of the input that maximise a downstream task's performance, which corresponds to optimising an explanation's Faithfulness to a given model. Faithfulness is one of several so-called diagnostic properties, which prior work has identified as useful for gauging the quality of an explanation without requiring annotations. Other diagnostic properties are Data Consistency, which measures how similar explanations are for similar input instances, and Confidence Indication, which shows whether the explanation reflects the confidence of the model. In this work, we show how to directly optimise for these diagnostic properties when training a model to generate sentence-level explanations, which markedly improves explanation quality, agreement with human rationales, and downstream task performance on three complex reasoning tasks.
A Diagnostic Study of Explainability Techniques for Text Classification
Sep 25, 2020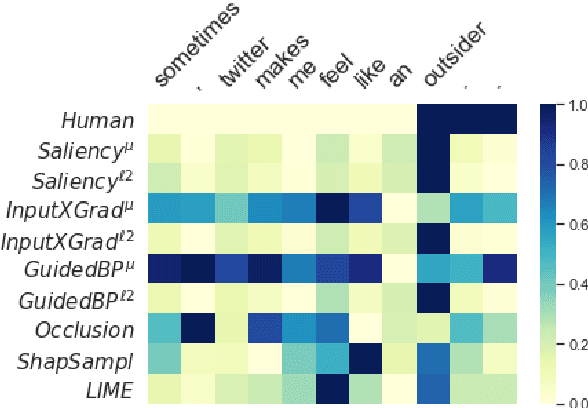
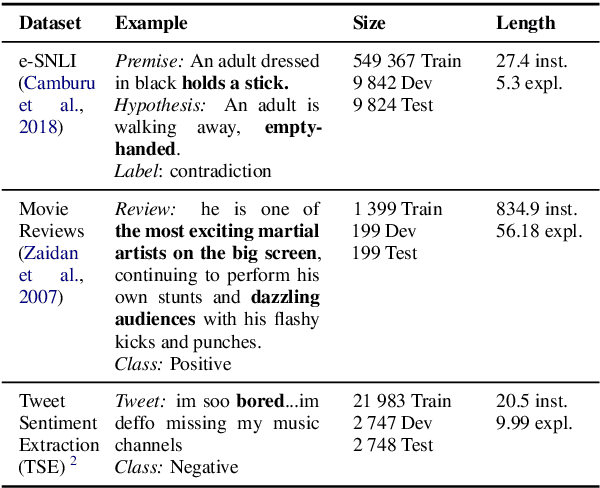
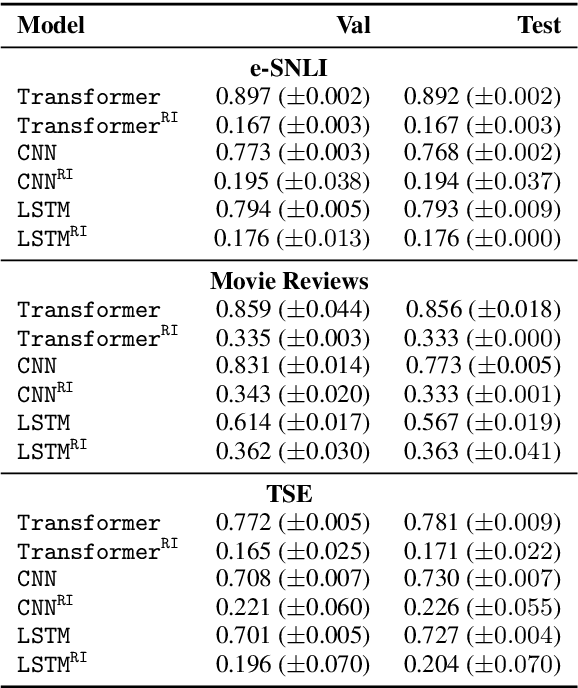

Recent developments in machine learning have introduced models that approach human performance at the cost of increased architectural complexity. Efforts to make the rationales behind the models' predictions transparent have inspired an abundance of new explainability techniques. Provided with an already trained model, they compute saliency scores for the words of an input instance. However, there exists no definitive guide on (i) how to choose such a technique given a particular application task and model architecture, and (ii) the benefits and drawbacks of using each such technique. In this paper, we develop a comprehensive list of diagnostic properties for evaluating existing explainability techniques. We then employ the proposed list to compare a set of diverse explainability techniques on downstream text classification tasks and neural network architectures. We also compare the saliency scores assigned by the explainability techniques with human annotations of salient input regions to find relations between a model's performance and the agreement of its rationales with human ones. Overall, we find that the gradient-based explanations perform best across tasks and model architectures, and we present further insights into the properties of the reviewed explainability techniques.