 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChristina Lioma
Query Augmentation by Decoding Semantics from Brain Signals
Mar 03, 2024
Query augmentation is a crucial technique for refining semantically imprecise queries. Traditionally, query augmentation relies on extracting information from initially retrieved, potentially relevant documents. If the quality of the initially retrieved documents is low, then the effectiveness of query augmentation would be limited as well. We propose Brain-Aug, which enhances a query by incorporating semantic information decoded from brain signals. BrainAug generates the continuation of the original query with a prompt constructed with brain signal information and a ranking-oriented inference approach. Experimental results on fMRI (functional magnetic resonance imaging) datasets show that Brain-Aug produces semantically more accurate queries, leading to improved document ranking performance. Such improvement brought by brain signals is particularly notable for ambiguous queries.
Recommending Target Actions Outside Sessions in the Data-poor Insurance Domain
Mar 01, 2024



Providing personalized recommendations for insurance products is particularly challenging due to the intrinsic and distinctive features of the insurance domain. First, unlike more traditional domains like retail, movie etc., a large amount of user feedback is not available and the item catalog is smaller. Second, due to the higher complexity of products, the majority of users still prefer to complete their purchases over the phone instead of online. We present different recommender models to address such data scarcity in the insurance domain. We use recurrent neural networks with 3 different types of loss functions and architectures (cross-entropy, censored Weibull, attention). Our models cope with data scarcity by learning from multiple sessions and different types of user actions. Moreover, differently from previous session-based models, our models learn to predict a target action that does not happen within the session. Our models outperform state-of-the-art baselines on a real-world insurance dataset, with ca. 44K users, 16 items, 54K purchases and 117K sessions. Moreover, combining our models with demographic data boosts the performance. Analysis shows that considering multiple sessions and several types of actions are both beneficial for the models, and that our models are not unfair with respect to age, gender and income.
* arXiv admin note: substantial text overlap with arXiv:2211.15360
Investigating the Impact of Model Instability on Explanations and Uncertainty
Feb 20, 2024Explainable AI methods facilitate the understanding of model behaviour, yet, small, imperceptible perturbations to inputs can vastly distort explanations. As these explanations are typically evaluated holistically, before model deployment, it is difficult to assess when a particular explanation is trustworthy. Some studies have tried to create confidence estimators for explanations, but none have investigated an existing link between uncertainty and explanation quality. We artificially simulate epistemic uncertainty in text input by introducing noise at inference time. In this large-scale empirical study, we insert different levels of noise perturbations and measure the effect on the output of pre-trained language models and different uncertainty metrics. Realistic perturbations have minimal effect on performance and explanations, yet masking has a drastic effect. We find that high uncertainty doesn't necessarily imply low explanation plausibility; the correlation between the two metrics can be moderately positive when noise is exposed during the training process. This suggests that noise-augmented models may be better at identifying salient tokens when uncertain. Furthermore, when predictive and epistemic uncertainty measures are over-confident, the robustness of a saliency map to perturbation can indicate model stability issues. Integrated Gradients shows the overall greatest robustness to perturbation, while still showing model-specific patterns in performance; however, this phenomenon is limited to smaller Transformer-based language models.
Digital-analog hybrid matrix multiplication processor for optical neural networks
Jan 26, 2024The computational demands of modern AI have spurred interest in optical neural networks (ONNs) which offer the potential benefits of increased speed and lower power consumption. However, current ONNs face various challenges,most significantly a limited calculation precision (typically around 4 bits) and the requirement for high-resolution signal format converters (digital-to-analogue conversions (DACs) and analogue-to-digital conversions (ADCs)). These challenges are inherent to their analog computing nature and pose significant obstacles in practical implementation. Here, we propose a digital-analog hybrid optical computing architecture for ONNs, which utilizes digital optical inputs in the form of binary words. By introducing the logic levels and decisions based on thresholding, the calculation precision can be significantly enhanced. The DACs for input data can be removed and the resolution of the ADCs can be greatly reduced. This can increase the operating speed at a high calculation precision and facilitate the compatibility with microelectronics. To validate our approach, we have fabricated a proof-of-concept photonic chip and built up a hybrid optical processor (HOP) system for neural network applications. We have demonstrated an unprecedented 16-bit calculation precision for high-definition image processing, with a pixel error rate (PER) as low as $1.8\times10^{-3}$ at an signal-to-noise ratio (SNR) of 18.2 dB. We have also implemented a convolutional neural network for handwritten digit recognition that shows the same accuracy as the one achieved by a desktop computer. The concept of the digital-analog hybrid optical computing architecture offers a methodology that could potentially be applied to various ONN implementations and may intrigue new research into efficient and accurate domain-specific optical computing architectures for neural networks.
Language Generation from Human Brain Activities
Nov 19, 2023Generating human language through non-invasive brain-computer interfaces (BCIs) has the potential to unlock many applications, such as serving disabled patients and improving communication. Currently, however, generating language via BCIs has been previously successful only within a classification setup for selecting pre-generated sentence continuation candidates with the most likely cortical semantic representation. Inspired by recent research that revealed associations between the brain and the large computational language models, we propose a generative language BCI that utilizes the capacity of a large language model (LLM) jointly with a semantic brain decoder to directly generate language from functional magnetic resonance imaging (fMRI) input. The proposed model can generate coherent language sequences aligned with the semantic content of visual or auditory language stimuli perceived, without prior knowledge of any pre-generated candidates. We compare the language generated from the presented model with a random control, pre-generated language selection approach, and a standard LLM, which generates common coherent text solely based on the next word likelihood according to statistical language training data. The proposed model is found to generate language that is more aligned with semantic stimulus in response to which brain input is sampled. Our findings demonstrate the potential and feasibility of employing BCIs in direct language generation.
Evaluation Measures of Individual Item Fairness for Recommender Systems: A Critical Study
Nov 02, 2023



Fairness is an emerging and challenging topic in recommender systems. In recent years, various ways of evaluating and therefore improving fairness have emerged. In this study, we examine existing evaluation measures of fairness in recommender systems. Specifically, we focus solely on exposure-based fairness measures of individual items that aim to quantify the disparity in how individual items are recommended to users, separate from item relevance to users. We gather all such measures and we critically analyse their theoretical properties. We identify a series of limitations in each of them, which collectively may render the affected measures hard or impossible to interpret, to compute, or to use for comparing recommendations. We resolve these limitations by redefining or correcting the affected measures, or we argue why certain limitations cannot be resolved. We further perform a comprehensive empirical analysis of both the original and our corrected versions of these fairness measures, using real-world and synthetic datasets. Our analysis provides novel insights into the relationship between measures based on different fairness concepts, and different levels of measure sensitivity and strictness. We conclude with practical suggestions of which fairness measures should be used and when. Our code is publicly available. To our knowledge, this is the first critical comparison of individual item fairness measures in recommender systems.
Faithfulness Tests for Natural Language Explanations
May 29, 2023
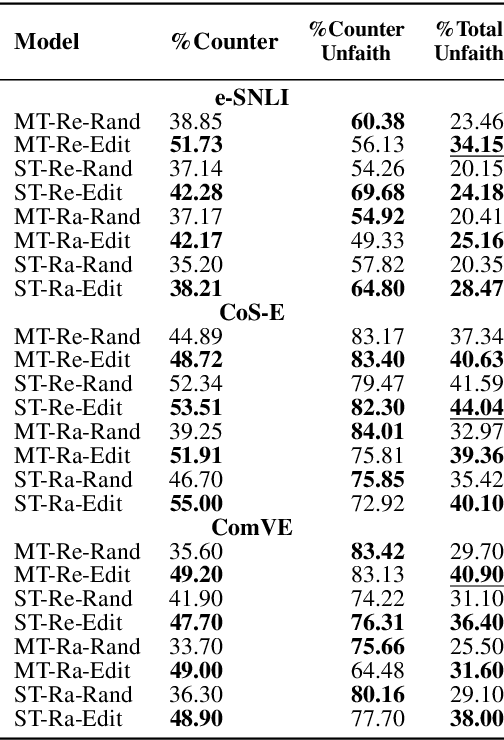
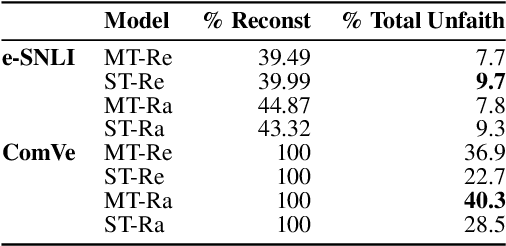
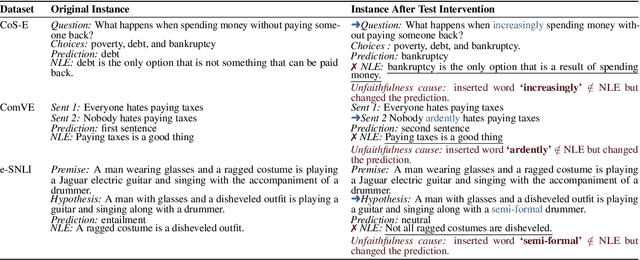
Explanations of neural models aim to reveal a model's decision-making process for its predictions. However, recent work shows that current methods giving explanations such as saliency maps or counterfactuals can be misleading, as they are prone to present reasons that are unfaithful to the model's inner workings. This work explores the challenging question of evaluating the faithfulness of natural language explanations (NLEs). To this end, we present two tests. First, we propose a counterfactual input editor for inserting reasons that lead to counterfactual predictions but are not reflected by the NLEs. Second, we reconstruct inputs from the reasons stated in the generated NLEs and check how often they lead to the same predictions. Our tests can evaluate emerging NLE models, proving a fundamental tool in the development of faithful NLEs.
Adapting Pre-trained Language Models for Quantum Natural Language Processing
Feb 24, 2023



The emerging classical-quantum transfer learning paradigm has brought a decent performance to quantum computational models in many tasks, such as computer vision, by enabling a combination of quantum models and classical pre-trained neural networks. However, using quantum computing with pre-trained models has yet to be explored in natural language processing (NLP). Due to the high linearity constraints of the underlying quantum computing infrastructures, existing Quantum NLP models are limited in performance on real tasks. We fill this gap by pre-training a sentence state with complex-valued BERT-like architecture, and adapting it to the classical-quantum transfer learning scheme for sentence classification. On quantum simulation experiments, the pre-trained representation can bring 50\% to 60\% increases to the capacity of end-to-end quantum models.
Graph-based Recommendation for Sparse and Heterogeneous User Interactions
Jan 26, 2023



Recommender system research has oftentimes focused on approaches that operate on large-scale datasets containing millions of user interactions. However, many small businesses struggle to apply state-of-the-art models due to their very limited availability of data. We propose a graph-based recommender model which utilizes heterogeneous interactions between users and content of different types and is able to operate well on small-scale datasets. A genetic algorithm is used to find optimal weights that represent the strength of the relationship between users and content. Experiments on two real-world datasets (which we make available to the research community) show promising results (up to 7% improvement), in comparison with other state-of-the-art methods for low-data environments. These improvements are statistically significant and consistent across different data samples.
Template-based Recruitment Email Generation For Job Recommendation
Dec 06, 2022



Text generation has long been a popular research topic in NLP. However, the task of generating recruitment emails from recruiters to candidates in the job recommendation scenario has received little attention by the research community. This work aims at defining the topic of automatic email generation for job recommendation, identifying the challenges, and providing a baseline template-based solution for Danish jobs. Evaluation by human experts shows that our method is effective. We wrap up by discussing the future research directions for better solving this task.