 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFabien Cardinaux
LLM meets Vision-Language Models for Zero-Shot One-Class Classification
Apr 02, 2024
We consider the problem of zero-shot one-class visual classification. In this setting, only the label of the target class is available, and the goal is to discriminate between positive and negative query samples without requiring any validation example from the target task. We propose a two-step solution that first queries large language models for visually confusing objects and then relies on vision-language pre-trained models (e.g., CLIP) to perform classification. By adapting large-scale vision benchmarks, we demonstrate the ability of the proposed method to outperform adapted off-the-shelf alternatives in this setting. Namely, we propose a realistic benchmark where negative query samples are drawn from the same original dataset as positive ones, including a granularity-controlled version of iNaturalist, where negative samples are at a fixed distance in the taxonomy tree from the positive ones. Our work shows that it is possible to discriminate between a single category and other semantically related ones using only its label
A Novel Benchmark for Few-Shot Semantic Segmentation in the Era of Foundation Models
Jan 20, 2024In recent years, the rapid evolution of computer vision has seen the emergence of various vision foundation models, each tailored to specific data types and tasks. While large language models often share a common pretext task, the diversity in vision foundation models arises from their varying training objectives. In this study, we delve into the quest for identifying the most effective vision foundation models for few-shot semantic segmentation, a critical task in computer vision. Specifically, we conduct a comprehensive comparative analysis of four prominent foundation models: DINO V2, Segment Anything, CLIP, Masked AutoEncoders, and a straightforward ResNet50 pre-trained on the COCO dataset. Our investigation focuses on their adaptability to new semantic segmentation tasks, leveraging only a limited number of segmented images. Our experimental findings reveal that DINO V2 consistently outperforms the other considered foundation models across a diverse range of datasets and adaptation methods. This outcome underscores DINO V2's superior capability to adapt to semantic segmentation tasks compared to its counterparts. Furthermore, our observations indicate that various adapter methods exhibit similar performance, emphasizing the paramount importance of selecting a robust feature extractor over the intricacies of the adaptation technique itself. This insight sheds light on the critical role of feature extraction in the context of few-shot semantic segmentation. This research not only contributes valuable insights into the comparative performance of vision foundation models in the realm of few-shot semantic segmentation but also highlights the significance of a robust feature extractor in this domain.
Inferring Latent Class Statistics from Text for Robust Visual Few-Shot Learning
Nov 24, 2023In the realm of few-shot learning, foundation models like CLIP have proven effective but exhibit limitations in cross-domain robustness especially in few-shot settings. Recent works add text as an extra modality to enhance the performance of these models. Most of these approaches treat text as an auxiliary modality without fully exploring its potential to elucidate the underlying class visual features distribution. In this paper, we present a novel approach that leverages text-derived statistics to predict the mean and covariance of the visual feature distribution for each class. This predictive framework enriches the latent space, yielding more robust and generalizable few-shot learning models. We demonstrate the efficacy of incorporating both mean and covariance statistics in improving few-shot classification performance across various datasets. Our method shows that we can use text to predict the mean and covariance of the distribution offering promising improvements in few-shot learning scenarios.
DBsurf: A Discrepancy Based Method for Discrete Stochastic Gradient Estimation
Sep 07, 2023Computing gradients of an expectation with respect to the distributional parameters of a discrete distribution is a problem arising in many fields of science and engineering. Typically, this problem is tackled using Reinforce, which frames the problem of gradient estimation as a Monte Carlo simulation. Unfortunately, the Reinforce estimator is especially sensitive to discrepancies between the true probability distribution and the drawn samples, a common issue in low sampling regimes that results in inaccurate gradient estimates. In this paper, we introduce DBsurf, a reinforce-based estimator for discrete distributions that uses a novel sampling procedure to reduce the discrepancy between the samples and the actual distribution. To assess the performance of our estimator, we subject it to a diverse set of tasks. Among existing estimators, DBsurf attains the lowest variance in a least squares problem commonly used in the literature for benchmarking. Furthermore, DBsurf achieves the best results for training variational auto-encoders (VAE) across different datasets and sampling setups. Finally, we apply DBsurf to build a simple and efficient Neural Architecture Search (NAS) algorithm with state-of-the-art performance.
Towards Robust FastSpeech 2 by Modelling Residual Multimodality
Jun 02, 2023


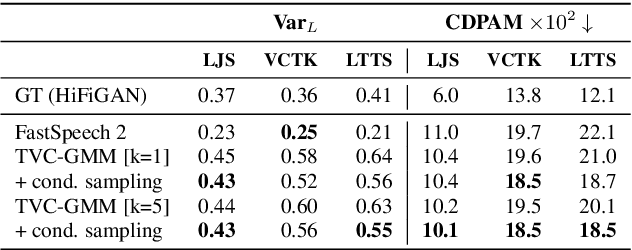
State-of-the-art non-autoregressive text-to-speech (TTS) models based on FastSpeech 2 can efficiently synthesise high-fidelity and natural speech. For expressive speech datasets however, we observe characteristic audio distortions. We demonstrate that such artefacts are introduced to the vocoder reconstruction by over-smooth mel-spectrogram predictions, which are induced by the choice of mean-squared-error (MSE) loss for training the mel-spectrogram decoder. With MSE loss FastSpeech 2 is limited to learn conditional averages of the training distribution, which might not lie close to a natural sample if the distribution still appears multimodal after all conditioning signals. To alleviate this problem, we introduce TVC-GMM, a mixture model of Trivariate-Chain Gaussian distributions, to model the residual multimodality. TVC-GMM reduces spectrogram smoothness and improves perceptual audio quality in particular for expressive datasets as shown by both objective and subjective evaluation.
Improving Self-Supervised Learning for Audio Representations by Feature Diversity and Decorrelation
Mar 07, 2023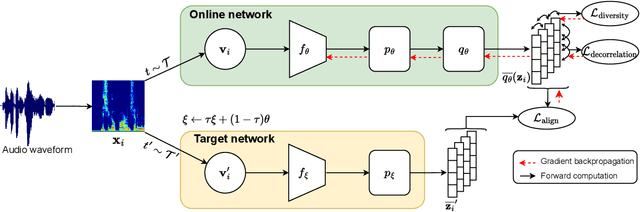

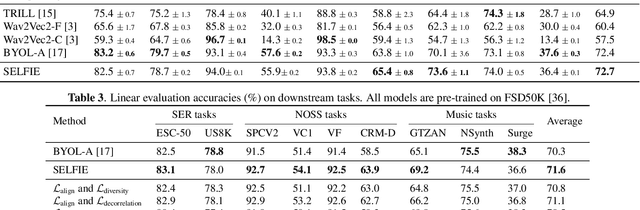
Self-supervised learning (SSL) has recently shown remarkable results in closing the gap between supervised and unsupervised learning. The idea is to learn robust features that are invariant to distortions of the input data. Despite its success, this idea can suffer from a collapsing issue where the network produces a constant representation. To this end, we introduce SELFIE, a novel Self-supervised Learning approach for audio representation via Feature Diversity and Decorrelation. SELFIE avoids the collapsing issue by ensuring that the representation (i) maintains a high diversity among embeddings and (ii) decorrelates the dependencies between dimensions. SELFIE is pre-trained on the large-scale AudioSet dataset and its embeddings are validated on nine audio downstream tasks, including speech, music, and sound event recognition. Experimental results show that SELFIE outperforms existing SSL methods in several tasks.
A Statistical Model for Predicting Generalization in Few-Shot Classification
Dec 13, 2022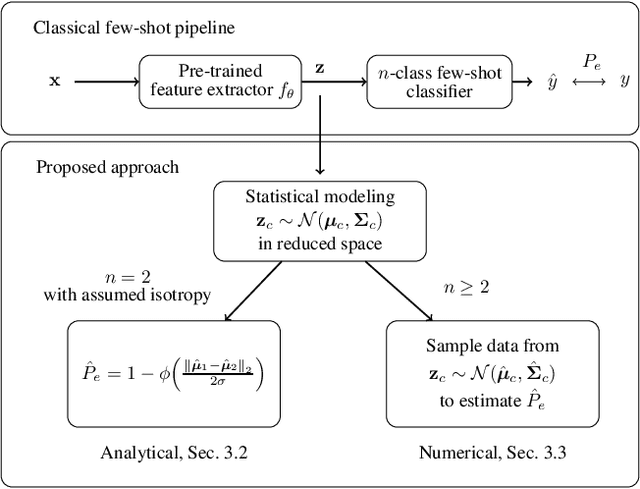
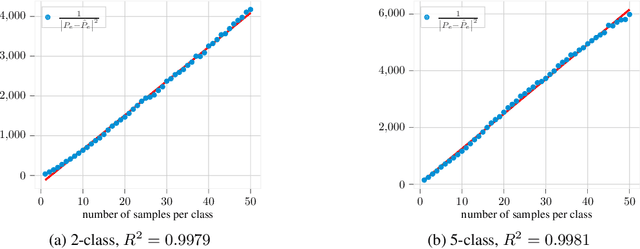


The estimation of the generalization error of classifiers often relies on a validation set. Such a set is hardly available in few-shot learning scenarios, a highly disregarded shortcoming in the field. In these scenarios, it is common to rely on features extracted from pre-trained neural networks combined with distance-based classifiers such as nearest class mean. In this work, we introduce a Gaussian model of the feature distribution. By estimating the parameters of this model, we are able to predict the generalization error on new classification tasks with few samples. We observe that accurate distance estimates between class-conditional densities are the key to accurate estimates of the generalization performance. Therefore, we propose an unbiased estimator for these distances and integrate it in our numerical analysis. We show that our approach outperforms alternatives such as the leave-one-out cross-validation strategy in few-shot settings.
A Low Memory Footprint Quantized Neural Network for Depth Completion of Very Sparse Time-of-Flight Depth Maps
May 25, 2022
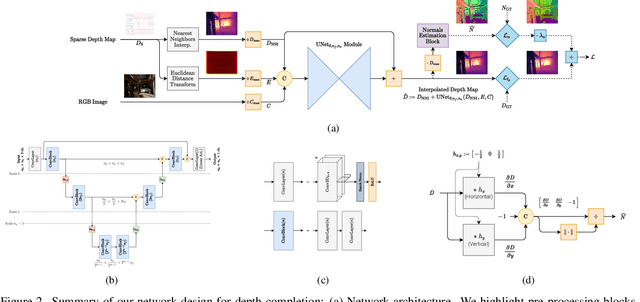

Sparse active illumination enables precise time-of-flight depth sensing as it maximizes signal-to-noise ratio for low power budgets. However, depth completion is required to produce dense depth maps for 3D perception. We address this task with realistic illumination and sensor resolution constraints by simulating ToF datasets for indoor 3D perception with challenging sparsity levels. We propose a quantized convolutional encoder-decoder network for this task. Our model achieves optimal depth map quality by means of input pre-processing and carefully tuned training with a geometry-preserving loss function. We also achieve low memory footprint for weights and activations by means of mixed precision quantization-at-training techniques. The resulting quantized models are comparable to the state of the art in terms of quality, but they require very low GPU times and achieve up to 14-fold memory size reduction for the weights w.r.t. their floating point counterpart with minimal impact on quality metrics.
Differentiable Duration Modeling for End-to-End Text-to-Speech
Mar 21, 2022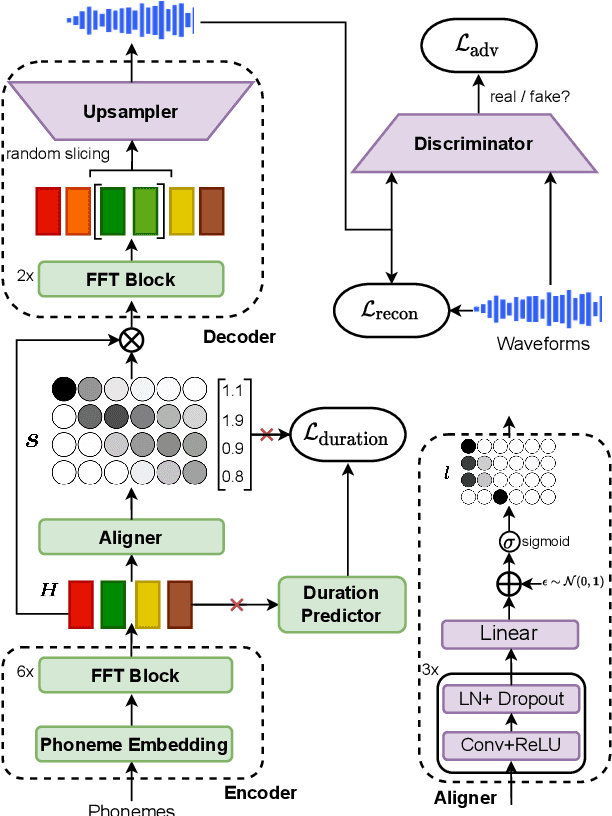
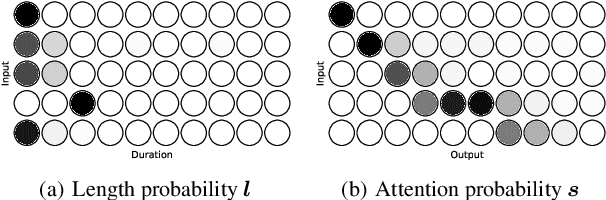
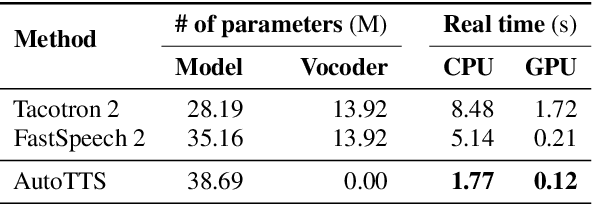
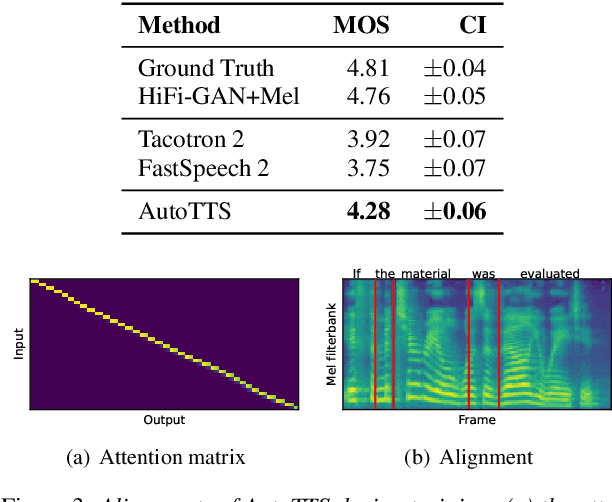
Parallel text-to-speech (TTS) models have recently enabled fast and highly-natural speech synthesis. However, such models typically require external alignment models, which are not necessarily optimized for the decoder as they are not jointly trained. In this paper, we propose a differentiable duration method for learning monotonic alignments between input and output sequences. Our method is based on a soft-duration mechanism that optimizes a stochastic process in expectation. Using this differentiable duration method, a direct text to waveform TTS model is introduced to produce raw audio as output instead of performing neural vocoding. Our model learns to perform high-fidelity speech synthesis through a combination of adversarial training and matching the total ground-truth duration. Experimental results show that our model obtains competitive results while enjoying a much simpler training pipeline. Audio samples are available online.
NVC-Net: End-to-End Adversarial Voice Conversion
Jun 02, 2021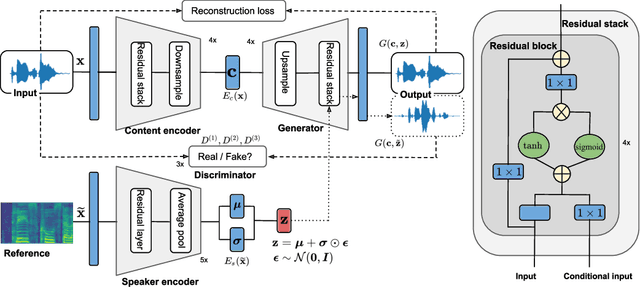

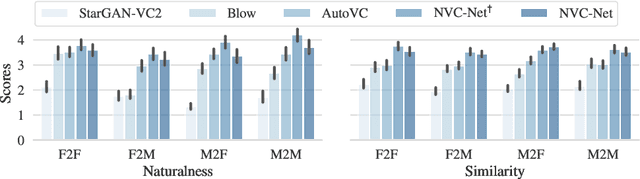

Voice conversion has gained increasing popularity in many applications of speech synthesis. The idea is to change the voice identity from one speaker into another while keeping the linguistic content unchanged. Many voice conversion approaches rely on the use of a vocoder to reconstruct the speech from acoustic features, and as a consequence, the speech quality heavily depends on such a vocoder. In this paper, we propose NVC-Net, an end-to-end adversarial network, which performs voice conversion directly on the raw audio waveform of arbitrary length. By disentangling the speaker identity from the speech content, NVC-Net is able to perform non-parallel traditional many-to-many voice conversion as well as zero-shot voice conversion from a short utterance of an unseen target speaker. Importantly, NVC-Net is non-autoregressive and fully convolutional, achieving fast inference. Our model is capable of producing samples at a rate of more than 3600 kHz on an NVIDIA V100 GPU, being orders of magnitude faster than state-of-the-art methods under the same hardware configurations. Objective and subjective evaluations on non-parallel many-to-many voice conversion tasks show that NVC-Net obtains competitive results with significantly fewer parameters.