 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStefan Uhlich
The Sound Demixing Challenge 2023 $\unicode{x2013}$ Cinematic Demixing Track
Aug 14, 2023
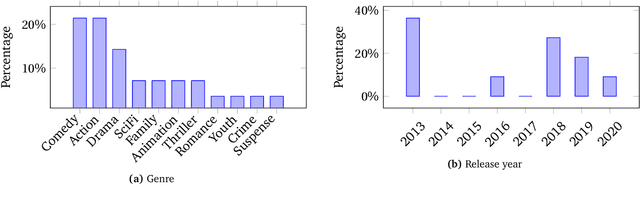
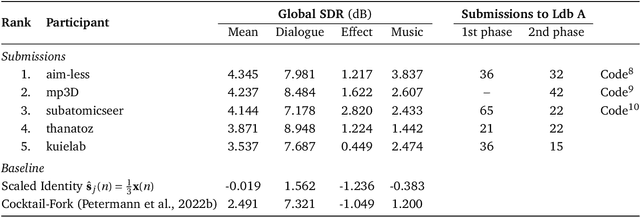
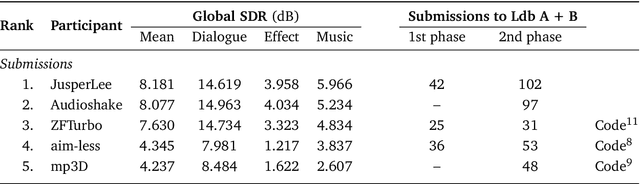
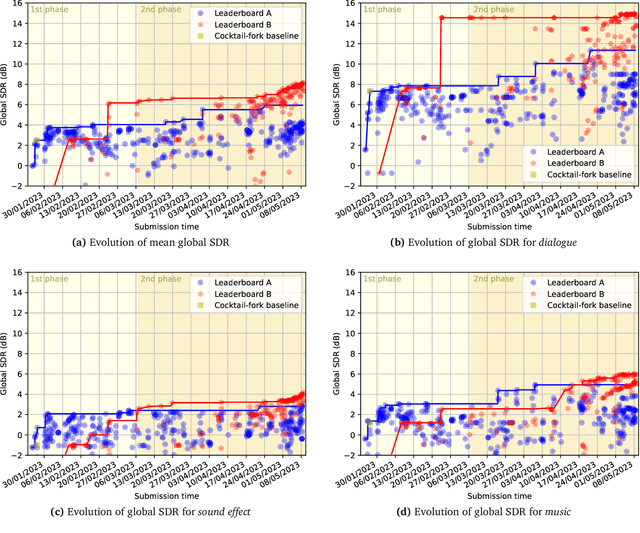
This paper summarizes the cinematic demixing (CDX) track of the Sound Demixing Challenge 2023 (SDX'23). We provide a comprehensive summary of the challenge setup, detailing the structure of the competition and the datasets used. Especially, we detail CDXDB23, a new hidden dataset constructed from real movies that was used to rank the submissions. The paper also offers insights into the most successful approaches employed by participants. Compared to the cocktail-fork baseline, the best-performing system trained exclusively on the simulated Divide and Remaster (DnR) dataset achieved an improvement of 1.8dB in SDR whereas the top performing system on the open leaderboard, where any data could be used for training, saw a significant improvement of 5.7dB.
The Sound Demixing Challenge 2023 $\unicode{x2013}$ Music Demixing Track
Aug 14, 2023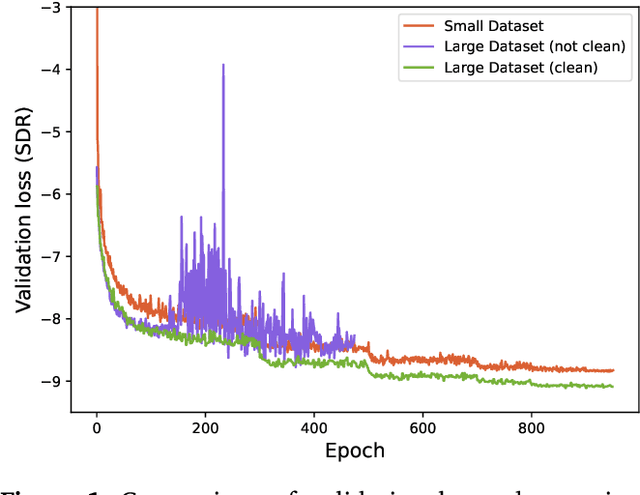
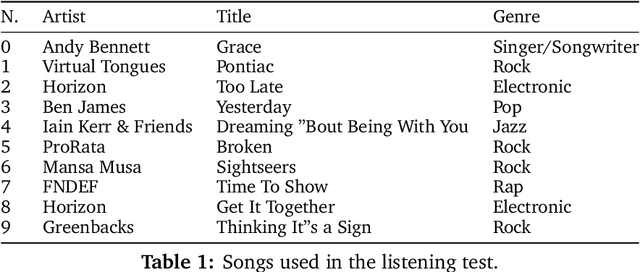
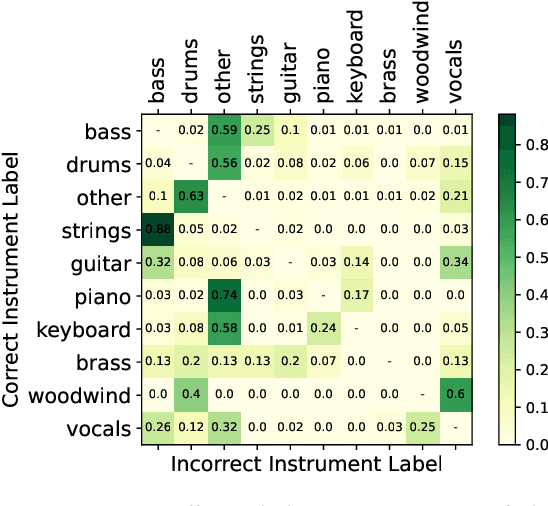

This paper summarizes the music demixing (MDX) track of the Sound Demixing Challenge (SDX'23). We provide a summary of the challenge setup and introduce the task of robust music source separation (MSS), i.e., training MSS models in the presence of errors in the training data. We propose a formalization of the errors that can occur in the design of a training dataset for MSS systems and introduce two new datasets that simulate such errors: SDXDB23_LabelNoise and SDXDB23_Bleeding1. We describe the methods that achieved the highest scores in the competition. Moreover, we present a direct comparison with the previous edition of the challenge (the Music Demixing Challenge 2021): the best performing system under the standard MSS formulation achieved an improvement of over 1.6dB in signal-to-distortion ratio over the winner of the previous competition, when evaluated on MDXDB21. Besides relying on the signal-to-distortion ratio as objective metric, we also performed a listening test with renowned producers/musicians to study the perceptual quality of the systems and report here the results. Finally, we provide our insights into the organization of the competition and our prospects for future editions.
The Whole Is Greater than the Sum of Its Parts: Improving DNN-based Music Source Separation
May 13, 2023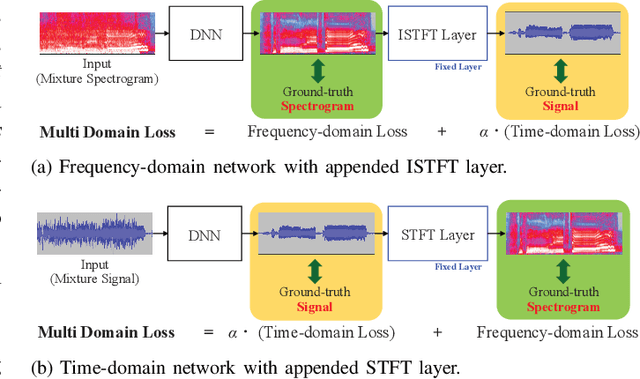

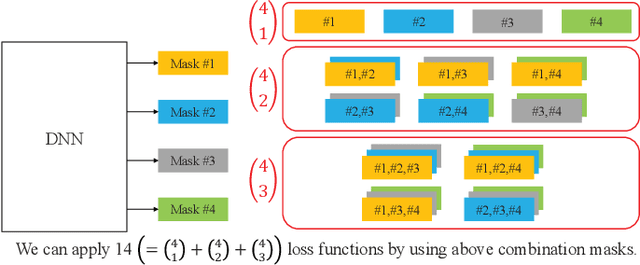
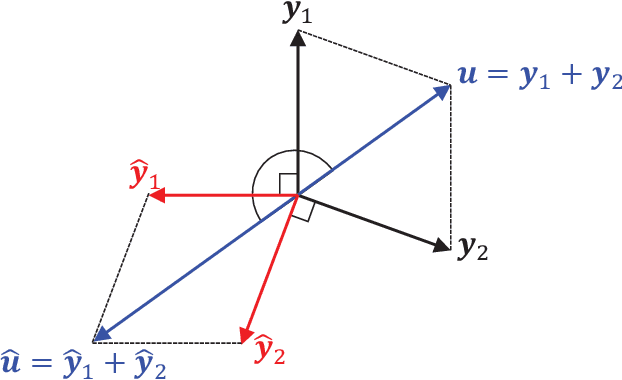
This paper presents the crossing scheme (X-scheme) for improving the performance of deep neural network (DNN)-based music source separation (MSS) without increasing calculation cost. It consists of three components: (i) multi-domain loss (MDL), (ii) bridging operation, which couples the individual instrument networks, and (iii) combination loss (CL). MDL enables the taking advantage of the frequency- and time-domain representations of audio signals. We modify the target network, i.e., the network architecture of the original DNN-based MSS, by adding bridging paths for each output instrument to share their information. MDL is then applied to the combinations of the output sources as well as each independent source, hence we called it CL. MDL and CL can easily be applied to many DNN-based separation methods as they are merely loss functions that are only used during training and do not affect the inference step. Bridging operation does not increase the number of learnable parameters in the network. Experimental results showed that the validity of Open-Unmix (UMX) and densely connected dilated DenseNet (D3Net) extended with our X-scheme, respectively called X-UMX and X-D3Net, by comparing them with their original versions. We also verified the effectiveness of X-scheme in a large-scale data regime, showing its generality with respect to data size. X-UMX Large (X-UMXL), which was trained on large-scale internal data and used in our experiments, is newly available at https://github.com/asteroid-team/asteroid/tree/master/egs/musdb18/X-UMX.
Improving Self-Supervised Learning for Audio Representations by Feature Diversity and Decorrelation
Mar 07, 2023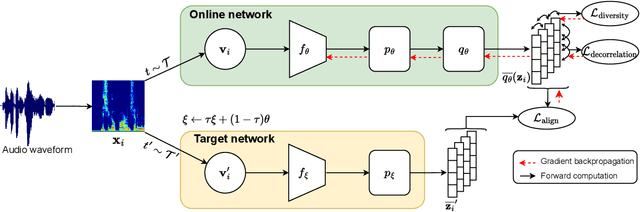

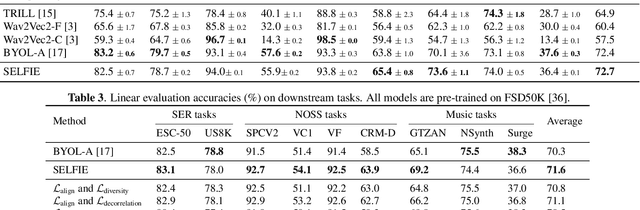
Self-supervised learning (SSL) has recently shown remarkable results in closing the gap between supervised and unsupervised learning. The idea is to learn robust features that are invariant to distortions of the input data. Despite its success, this idea can suffer from a collapsing issue where the network produces a constant representation. To this end, we introduce SELFIE, a novel Self-supervised Learning approach for audio representation via Feature Diversity and Decorrelation. SELFIE avoids the collapsing issue by ensuring that the representation (i) maintains a high diversity among embeddings and (ii) decorrelates the dependencies between dimensions. SELFIE is pre-trained on the large-scale AudioSet dataset and its embeddings are validated on nine audio downstream tasks, including speech, music, and sound event recognition. Experimental results show that SELFIE outperforms existing SSL methods in several tasks.
A Statistical Model for Predicting Generalization in Few-Shot Classification
Dec 13, 2022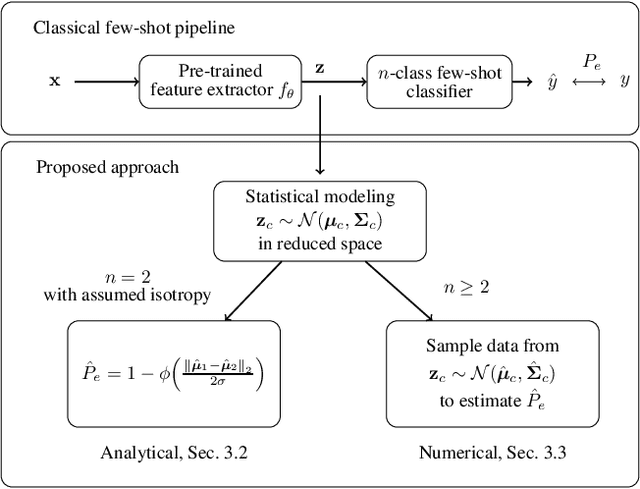
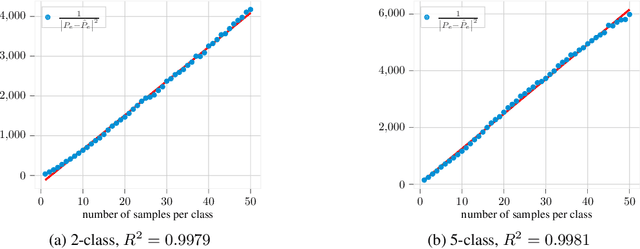


The estimation of the generalization error of classifiers often relies on a validation set. Such a set is hardly available in few-shot learning scenarios, a highly disregarded shortcoming in the field. In these scenarios, it is common to rely on features extracted from pre-trained neural networks combined with distance-based classifiers such as nearest class mean. In this work, we introduce a Gaussian model of the feature distribution. By estimating the parameters of this model, we are able to predict the generalization error on new classification tasks with few samples. We observe that accurate distance estimates between class-conditional densities are the key to accurate estimates of the generalization performance. Therefore, we propose an unbiased estimator for these distances and integrate it in our numerical analysis. We show that our approach outperforms alternatives such as the leave-one-out cross-validation strategy in few-shot settings.
Music Mixing Style Transfer: A Contrastive Learning Approach to Disentangle Audio Effects
Nov 04, 2022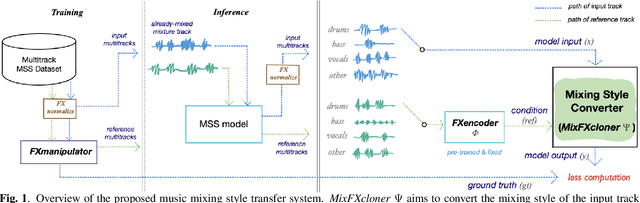
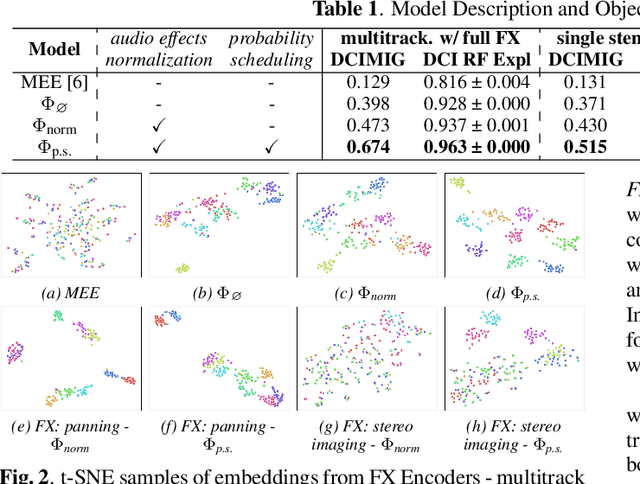

We propose an end-to-end music mixing style transfer system that converts the mixing style of an input multitrack to that of a reference song. This is achieved with an encoder pre-trained with a contrastive objective to extract only audio effects related information from a reference music recording. All our models are trained in a self-supervised manner from an already-processed wet multitrack dataset with an effective data preprocessing method that alleviates the data scarcity of obtaining unprocessed dry data. We analyze the proposed encoder for the disentanglement capability of audio effects and also validate its performance for mixing style transfer through both objective and subjective evaluations. From the results, we show the proposed system not only converts the mixing style of multitrack audio close to a reference but is also robust with mixture-wise style transfer upon using a music source separation model.
Automatic music mixing with deep learning and out-of-domain data
Aug 29, 2022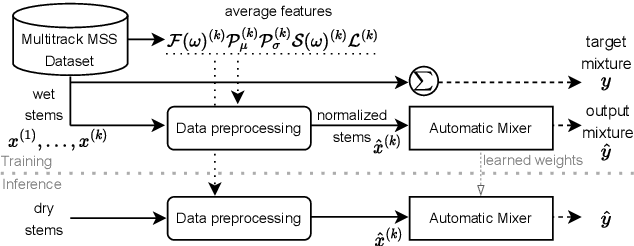
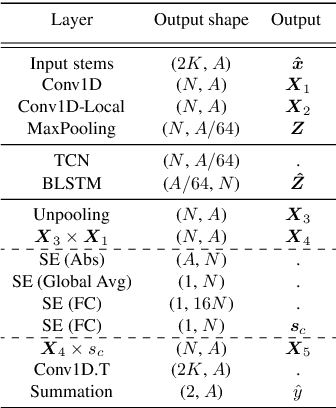

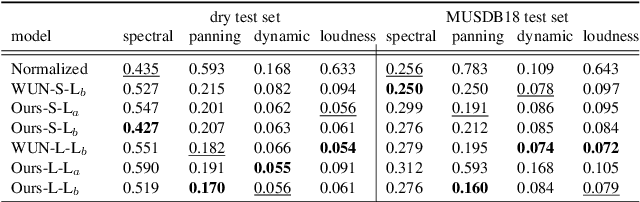
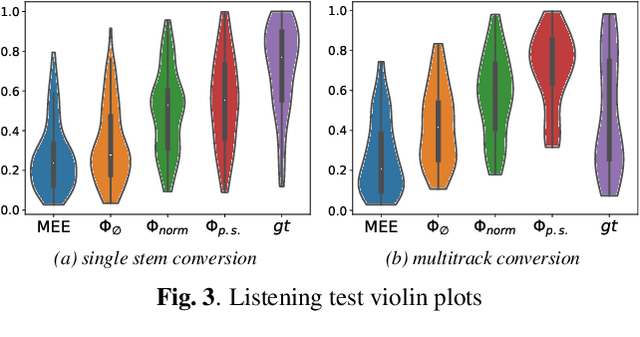
Music mixing traditionally involves recording instruments in the form of clean, individual tracks and blending them into a final mixture using audio effects and expert knowledge (e.g., a mixing engineer). The automation of music production tasks has become an emerging field in recent years, where rule-based methods and machine learning approaches have been explored. Nevertheless, the lack of dry or clean instrument recordings limits the performance of such models, which is still far from professional human-made mixes. We explore whether we can use out-of-domain data such as wet or processed multitrack music recordings and repurpose it to train supervised deep learning models that can bridge the current gap in automatic mixing quality. To achieve this we propose a novel data preprocessing method that allows the models to perform automatic music mixing. We also redesigned a listening test method for evaluating music mixing systems. We validate our results through such subjective tests using highly experienced mixing engineers as participants.
Differentiable Duration Modeling for End-to-End Text-to-Speech
Mar 21, 2022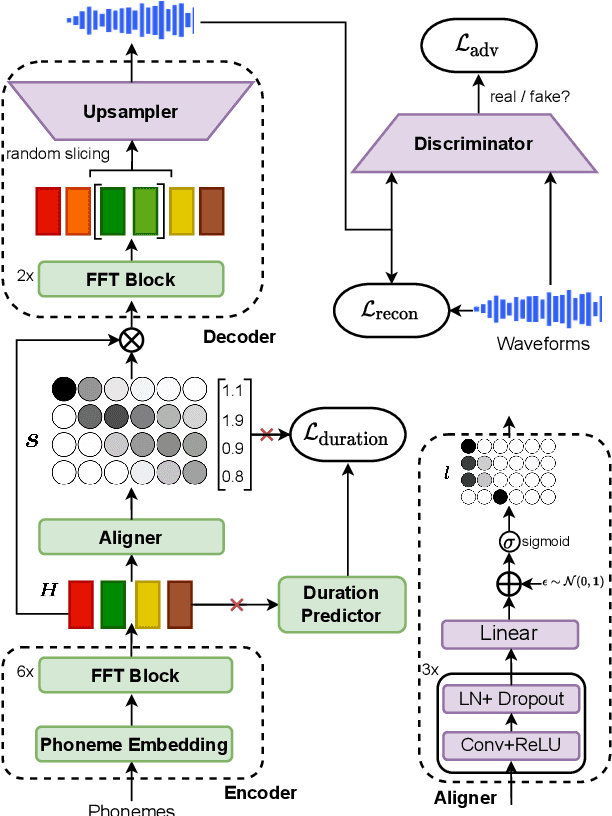
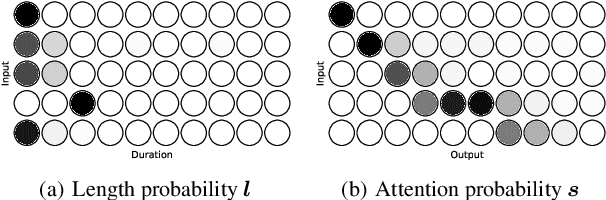
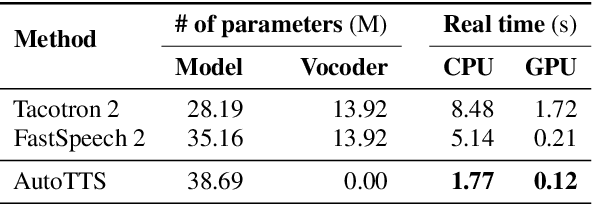
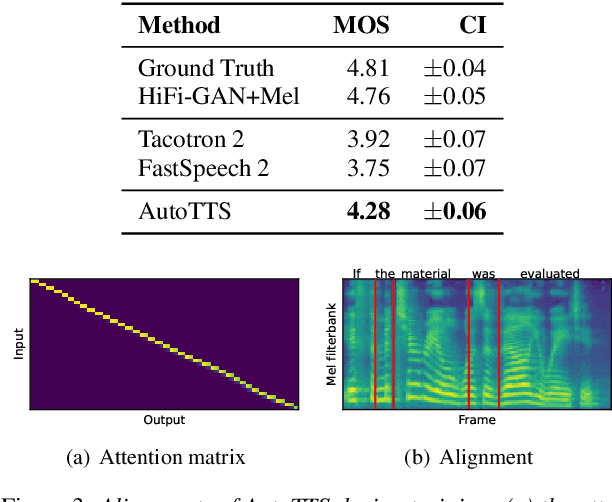
Parallel text-to-speech (TTS) models have recently enabled fast and highly-natural speech synthesis. However, such models typically require external alignment models, which are not necessarily optimized for the decoder as they are not jointly trained. In this paper, we propose a differentiable duration method for learning monotonic alignments between input and output sequences. Our method is based on a soft-duration mechanism that optimizes a stochastic process in expectation. Using this differentiable duration method, a direct text to waveform TTS model is introduced to produce raw audio as output instead of performing neural vocoding. Our model learns to perform high-fidelity speech synthesis through a combination of adversarial training and matching the total ground-truth duration. Experimental results show that our model obtains competitive results while enjoying a much simpler training pipeline. Audio samples are available online.
Removing Distortion Effects in Music Using Deep Neural Networks
Feb 03, 2022
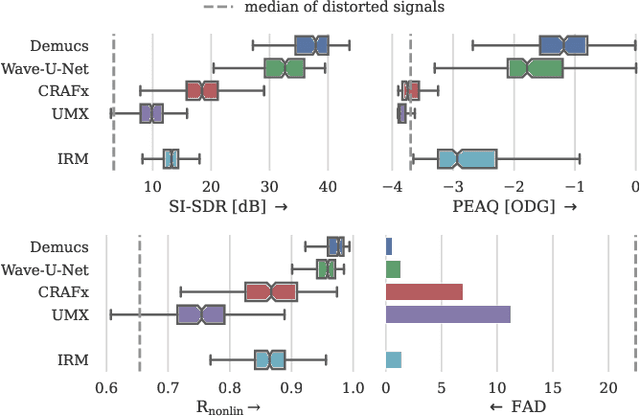
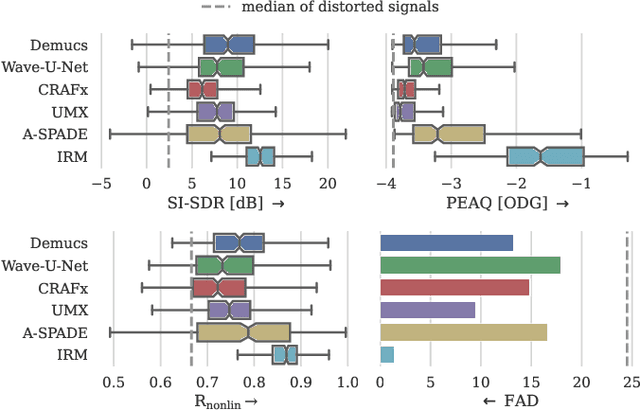
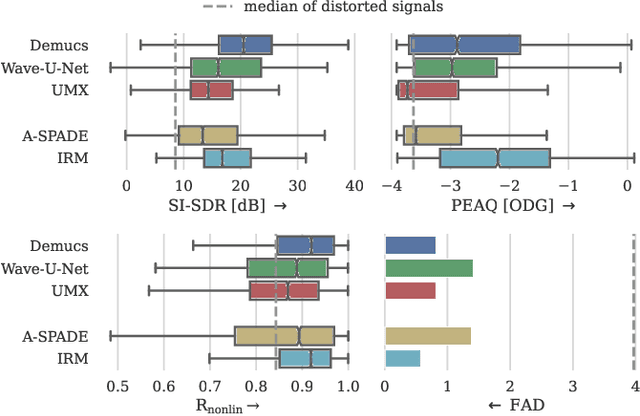
Audio effects are an essential element in the context of music production, and therefore, modeling analog audio effects has been extensively researched for decades using system-identification methods, circuit simulation, and recently, deep learning. However, only few works tackled the reconstruction of signals that were processed using an audio effect unit. Given the recent advances in music source separation and automatic mixing, the removal of audio effects could facilitate an automatic remixing system. This paper focuses on removing distortion and clipping applied to guitar tracks for music production while presenting a comparative investigation of different deep neural network (DNN) architectures on this task. We achieve exceptionally good results in distortion removal using DNNs for effects that superimpose the clean signal to the distorted signal, while the task is more challenging if the clean signal is not superimposed. Nevertheless, in the latter case, the neural models under evaluation surpass one state-of-the-art declipping system in terms of source-to-distortion ratio, leading to better quality and faster inference.
Music Source Separation with Deep Equilibrium Models
Oct 13, 2021
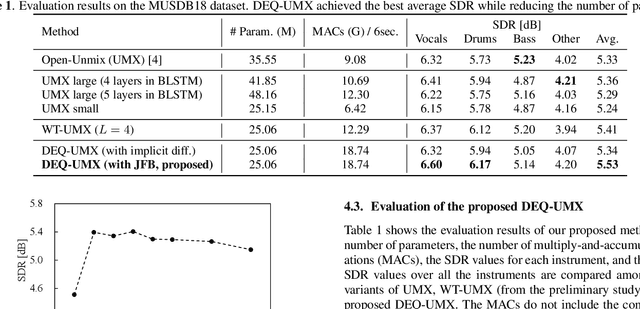

While deep neural network-based music source separation (MSS) is very effective and achieves high performance, its model size is often a problem for practical deployment. Deep implicit architectures such as deep equilibrium models (DEQ) were recently proposed, which can achieve higher performance than their explicit counterparts with limited depth while keeping the number of parameters small. This makes DEQ also attractive for MSS, especially as it was originally applied to sequential modeling tasks in natural language processing and thus should in principle be also suited for MSS. However, an investigation of a good architecture and training scheme for MSS with DEQ is needed as the characteristics of acoustic signals are different from those of natural language data. Hence, in this paper we propose an architecture and training scheme for MSS with DEQ. Starting with the architecture of Open-Unmix (UMX), we replace its sequence model with DEQ. We refer to our proposed method as DEQ-based UMX (DEQ-UMX). Experimental results show that DEQ-UMX performs better than the original UMX while reducing its number of parameters by 30%.