 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFalong Shen
Meta Networks for Neural Style Transfer
Sep 13, 2017
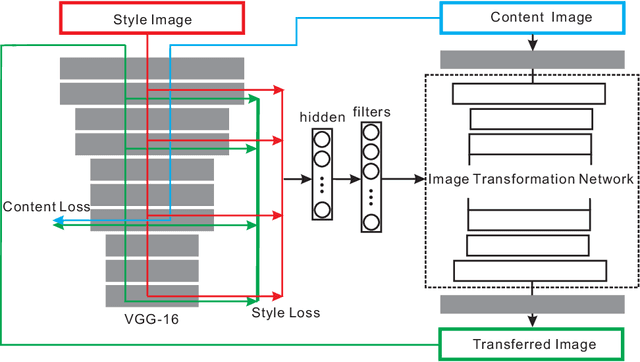
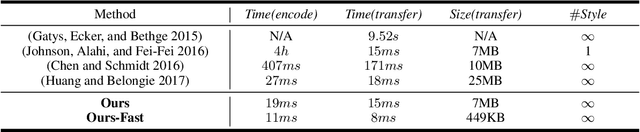

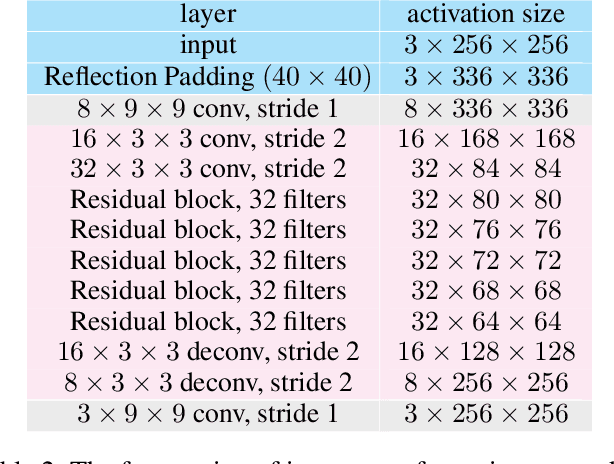
In this paper we propose a new method to get the specified network parameters through one time feed-forward propagation of the meta networks and explore the application to neural style transfer. Recent works on style transfer typically need to train image transformation networks for every new style, and the style is encoded in the network parameters by enormous iterations of stochastic gradient descent. To tackle these issues, we build a meta network which takes in the style image and produces a corresponding image transformations network directly. Compared with optimization-based methods for every style, our meta networks can handle an arbitrary new style within $19ms$ seconds on one modern GPU card. The fast image transformation network generated by our meta network is only 449KB, which is capable of real-time executing on a mobile device. We also investigate the manifold of the style transfer networks by operating the hidden features from meta networks. Experiments have well validated the effectiveness of our method. Code and trained models has been released https://github.com/FalongShen/styletransfer.
Weighted Residuals for Very Deep Networks
May 28, 2016


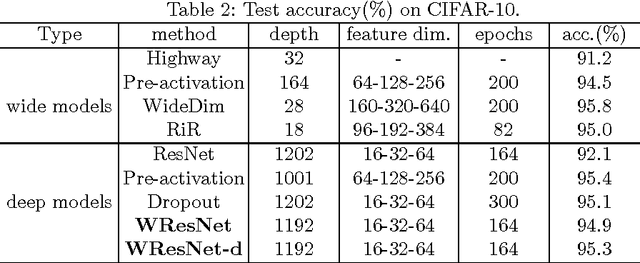
Deep residual networks have recently shown appealing performance on many challenging computer vision tasks. However, the original residual structure still has some defects making it difficult to converge on very deep networks. In this paper, we introduce a weighted residual network to address the incompatibility between \texttt{ReLU} and element-wise addition and the deep network initialization problem. The weighted residual network is able to learn to combine residuals from different layers effectively and efficiently. The proposed models enjoy a consistent improvement over accuracy and convergence with increasing depths from 100+ layers to 1000+ layers. Besides, the weighted residual networks have little more computation and GPU memory burden than the original residual networks. The networks are optimized by projected stochastic gradient descent. Experiments on CIFAR-10 have shown that our algorithm has a \emph{faster convergence speed} than the original residual networks and reaches a \emph{high accuracy} at 95.3\% with a 1192-layer model.
Fast Semantic Image Segmentation with High Order Context and Guided Filtering
May 13, 2016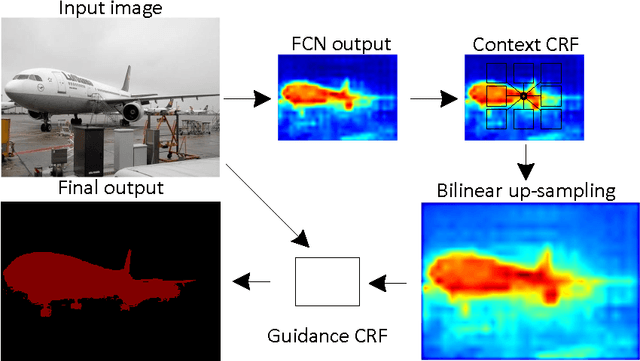
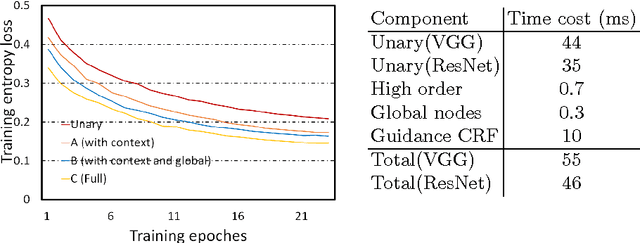
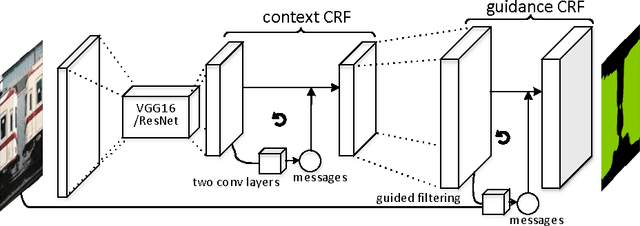
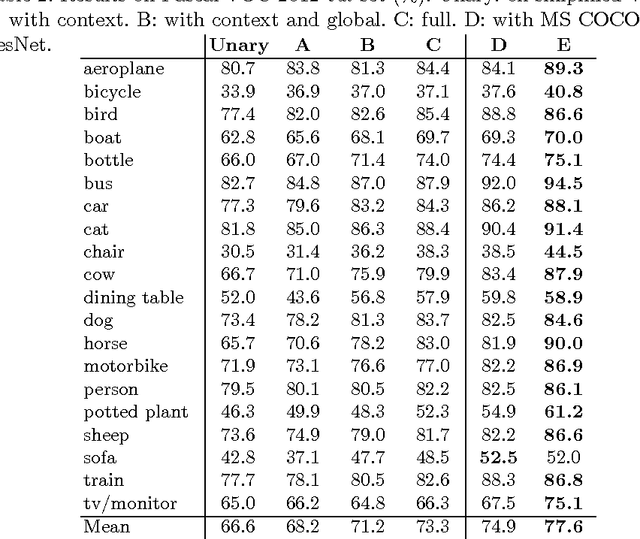
This paper describes a fast and accurate semantic image segmentation approach that encodes not only the discriminative features from deep neural networks, but also the high-order context compatibility among adjacent objects as well as low level image features. We formulate the underlying problem as the conditional random field that embeds local feature extraction, clique potential construction, and guided filtering within the same framework, and provide an efficient coarse-to-fine solver. At the coarse level, we combine local feature representation and context interaction using a deep convolutional network, and directly learn the interaction from high order cliques with a message passing routine, avoiding time-consuming explicit graph inference for joint probability distribution. At the fine level, we introduce a guided filtering interpretation for the mean field algorithm, and achieve accurate object boundaries with 100+ faster than classic learning methods. The two parts are connected and jointly trained in an end-to-end fashion. Experimental results on Pascal VOC 2012 dataset have shown that the proposed algorithm outperforms the state-of-the-art, and that it achieves the rank 1 performance at the time of submission, both of which prove the effectiveness of this unified framework for semantic image segmentation.