 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGang Zeng
InTeX: Interactive Text-to-texture Synthesis via Unified Depth-aware Inpainting
Mar 18, 2024

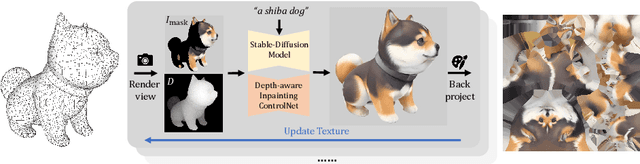


Text-to-texture synthesis has become a new frontier in 3D content creation thanks to the recent advances in text-to-image models. Existing methods primarily adopt a combination of pretrained depth-aware diffusion and inpainting models, yet they exhibit shortcomings such as 3D inconsistency and limited controllability. To address these challenges, we introduce InteX, a novel framework for interactive text-to-texture synthesis. 1) InteX includes a user-friendly interface that facilitates interaction and control throughout the synthesis process, enabling region-specific repainting and precise texture editing. 2) Additionally, we develop a unified depth-aware inpainting model that integrates depth information with inpainting cues, effectively mitigating 3D inconsistencies and improving generation speed. Through extensive experiments, our framework has proven to be both practical and effective in text-to-texture synthesis, paving the way for high-quality 3D content creation.
LGM: Large Multi-View Gaussian Model for High-Resolution 3D Content Creation
Feb 07, 20243D content creation has achieved significant progress in terms of both quality and speed. Although current feed-forward models can produce 3D objects in seconds, their resolution is constrained by the intensive computation required during training. In this paper, we introduce Large Multi-View Gaussian Model (LGM), a novel framework designed to generate high-resolution 3D models from text prompts or single-view images. Our key insights are two-fold: 1) 3D Representation: We propose multi-view Gaussian features as an efficient yet powerful representation, which can then be fused together for differentiable rendering. 2) 3D Backbone: We present an asymmetric U-Net as a high-throughput backbone operating on multi-view images, which can be produced from text or single-view image input by leveraging multi-view diffusion models. Extensive experiments demonstrate the high fidelity and efficiency of our approach. Notably, we maintain the fast speed to generate 3D objects within 5 seconds while boosting the training resolution to 512, thereby achieving high-resolution 3D content generation.
DreamGaussian4D: Generative 4D Gaussian Splatting
Dec 29, 2023Remarkable progress has been made in 4D content generation recently. However, existing methods suffer from long optimization time, lack of motion controllability, and a low level of detail. In this paper, we introduce DreamGaussian4D, an efficient 4D generation framework that builds on 4D Gaussian Splatting representation. Our key insight is that the explicit modeling of spatial transformations in Gaussian Splatting makes it more suitable for the 4D generation setting compared with implicit representations. DreamGaussian4D reduces the optimization time from several hours to just a few minutes, allows flexible control of the generated 3D motion, and produces animated meshes that can be efficiently rendered in 3D engines.
HumanGaussian: Text-Driven 3D Human Generation with Gaussian Splatting
Nov 28, 2023Realistic 3D human generation from text prompts is a desirable yet challenging task. Existing methods optimize 3D representations like mesh or neural fields via score distillation sampling (SDS), which suffers from inadequate fine details or excessive training time. In this paper, we propose an efficient yet effective framework, HumanGaussian, that generates high-quality 3D humans with fine-grained geometry and realistic appearance. Our key insight is that 3D Gaussian Splatting is an efficient renderer with periodic Gaussian shrinkage or growing, where such adaptive density control can be naturally guided by intrinsic human structures. Specifically, 1) we first propose a Structure-Aware SDS that simultaneously optimizes human appearance and geometry. The multi-modal score function from both RGB and depth space is leveraged to distill the Gaussian densification and pruning process. 2) Moreover, we devise an Annealed Negative Prompt Guidance by decomposing SDS into a noisier generative score and a cleaner classifier score, which well addresses the over-saturation issue. The floating artifacts are further eliminated based on Gaussian size in a prune-only phase to enhance generation smoothness. Extensive experiments demonstrate the superior efficiency and competitive quality of our framework, rendering vivid 3D humans under diverse scenarios. Project Page: https://alvinliu0.github.io/projects/HumanGaussian
DreamGaussian: Generative Gaussian Splatting for Efficient 3D Content Creation
Sep 28, 2023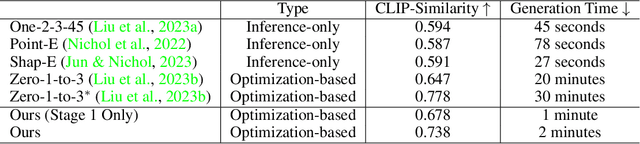
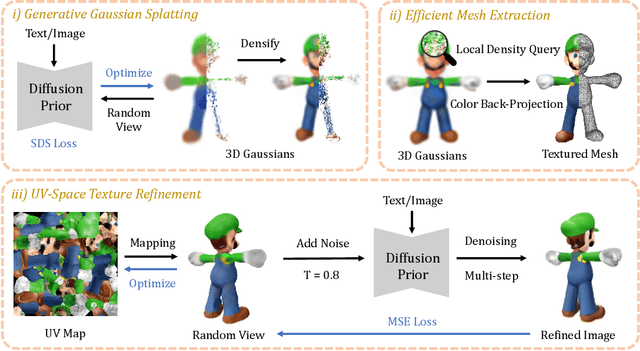


Recent advances in 3D content creation mostly leverage optimization-based 3D generation via score distillation sampling (SDS). Though promising results have been exhibited, these methods often suffer from slow per-sample optimization, limiting their practical usage. In this paper, we propose DreamGaussian, a novel 3D content generation framework that achieves both efficiency and quality simultaneously. Our key insight is to design a generative 3D Gaussian Splatting model with companioned mesh extraction and texture refinement in UV space. In contrast to the occupancy pruning used in Neural Radiance Fields, we demonstrate that the progressive densification of 3D Gaussians converges significantly faster for 3D generative tasks. To further enhance the texture quality and facilitate downstream applications, we introduce an efficient algorithm to convert 3D Gaussians into textured meshes and apply a fine-tuning stage to refine the details. Extensive experiments demonstrate the superior efficiency and competitive generation quality of our proposed approach. Notably, DreamGaussian produces high-quality textured meshes in just 2 minutes from a single-view image, achieving approximately 10 times acceleration compared to existing methods.
Interactive Segment Anything NeRF with Feature Imitation
May 25, 2023
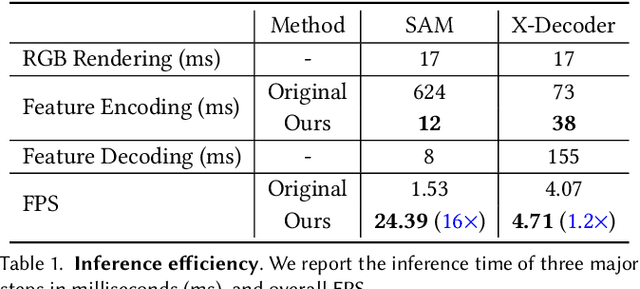


This paper investigates the potential of enhancing Neural Radiance Fields (NeRF) with semantics to expand their applications. Although NeRF has been proven useful in real-world applications like VR and digital creation, the lack of semantics hinders interaction with objects in complex scenes. We propose to imitate the backbone feature of off-the-shelf perception models to achieve zero-shot semantic segmentation with NeRF. Our framework reformulates the segmentation process by directly rendering semantic features and only applying the decoder from perception models. This eliminates the need for expensive backbones and benefits 3D consistency. Furthermore, we can project the learned semantics onto extracted mesh surfaces for real-time interaction. With the state-of-the-art Segment Anything Model (SAM), our framework accelerates segmentation by 16 times with comparable mask quality. The experimental results demonstrate the efficacy and computational advantages of our approach. Project page: \url{https://me.kiui.moe/san/}.
VisionLLM: Large Language Model is also an Open-Ended Decoder for Vision-Centric Tasks
May 25, 2023



Large language models (LLMs) have notably accelerated progress towards artificial general intelligence (AGI), with their impressive zero-shot capacity for user-tailored tasks, endowing them with immense potential across a range of applications. However, in the field of computer vision, despite the availability of numerous powerful vision foundation models (VFMs), they are still restricted to tasks in a pre-defined form, struggling to match the open-ended task capabilities of LLMs. In this work, we present an LLM-based framework for vision-centric tasks, termed VisionLLM. This framework provides a unified perspective for vision and language tasks by treating images as a foreign language and aligning vision-centric tasks with language tasks that can be flexibly defined and managed using language instructions. An LLM-based decoder can then make appropriate predictions based on these instructions for open-ended tasks. Extensive experiments show that the proposed VisionLLM can achieve different levels of task customization through language instructions, from fine-grained object-level to coarse-grained task-level customization, all with good results. It's noteworthy that, with a generalist LLM-based framework, our model can achieve over 60\% mAP on COCO, on par with detection-specific models. We hope this model can set a new baseline for generalist vision and language models. The demo shall be released based on https://github.com/OpenGVLab/InternGPT. The code shall be released at https://github.com/OpenGVLab/VisionLLM.
Real-time 3D Semantic Scene Completion Via Feature Aggregation and Conditioned Prediction
Mar 25, 2023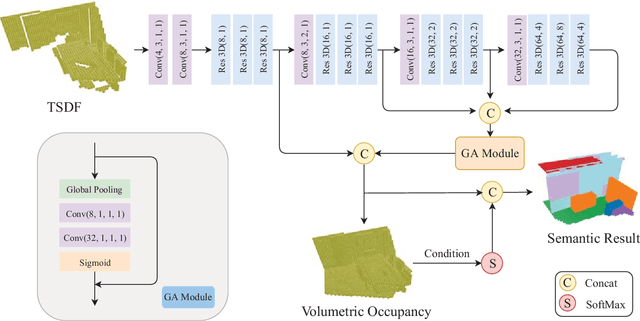

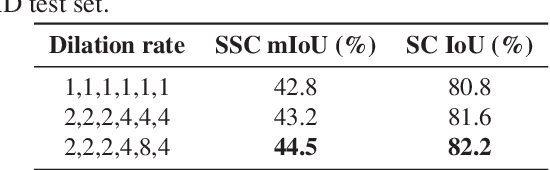
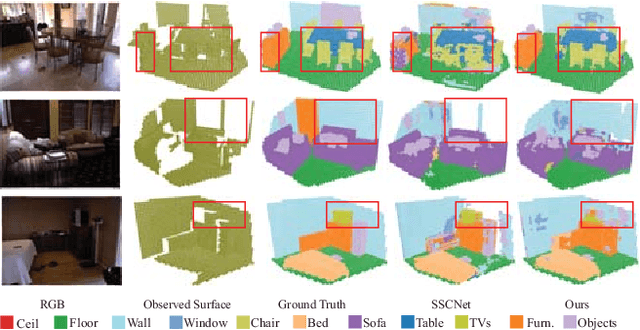
Semantic Scene Completion (SSC) aims to simultaneously predict the volumetric occupancy and semantic category of a 3D scene. In this paper, we propose a real-time semantic scene completion method with a feature aggregation strategy and conditioned prediction module. Feature aggregation fuses feature with different receptive fields and gathers context to improve scene completion performance. And the conditioned prediction module adopts a two-step prediction scheme that takes volumetric occupancy as a condition to enhance semantic completion prediction. We conduct experiments on three recognized benchmarks NYU, NYUCAD, and SUNCG. Our method achieves competitive performance at a speed of 110 FPS on one GTX 1080 Ti GPU.
Delicate Textured Mesh Recovery from NeRF via Adaptive Surface Refinement
Mar 03, 2023
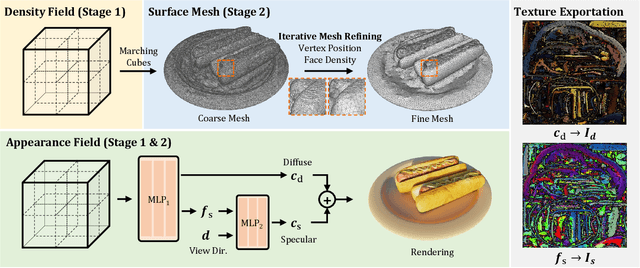
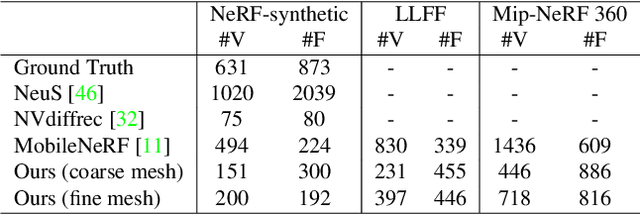
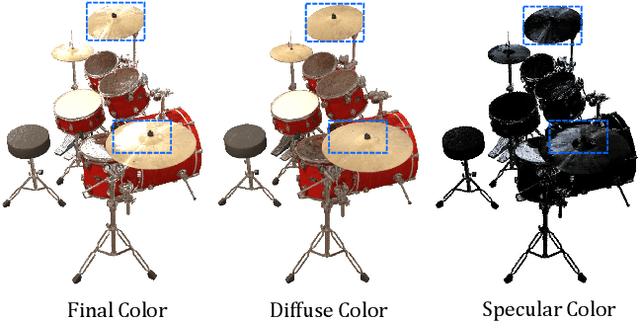
Neural Radiance Fields (NeRF) have constituted a remarkable breakthrough in image-based 3D reconstruction. However, their implicit volumetric representations differ significantly from the widely-adopted polygonal meshes and lack support from common 3D software and hardware, making their rendering and manipulation inefficient. To overcome this limitation, we present a novel framework that generates textured surface meshes from images. Our approach begins by efficiently initializing the geometry and view-dependency decomposed appearance with a NeRF. Subsequently, a coarse mesh is extracted, and an iterative surface refining algorithm is developed to adaptively adjust both vertex positions and face density based on re-projected rendering errors. We jointly refine the appearance with geometry and bake it into texture images for real-time rendering. Extensive experiments demonstrate that our method achieves superior mesh quality and competitive rendering quality.
Graph Signal Sampling for Inductive One-Bit Matrix Completion: a Closed-form Solution
Feb 08, 2023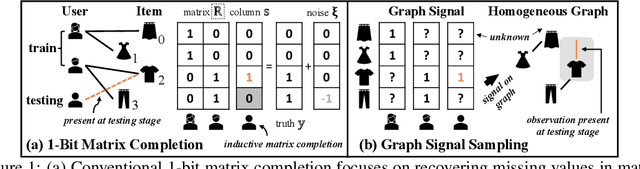


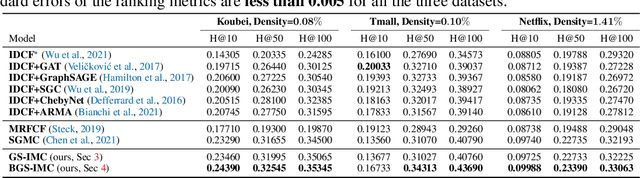
Inductive one-bit matrix completion is motivated by modern applications such as recommender systems, where new users would appear at test stage with the ratings consisting of only ones and no zeros. We propose a unified graph signal sampling framework which enjoys the benefits of graph signal analysis and processing. The key idea is to transform each user's ratings on the items to a function (signal) on the vertices of an item-item graph, then learn structural graph properties to recover the function from its values on certain vertices -- the problem of graph signal sampling. We propose a class of regularization functionals that takes into account discrete random label noise in the graph vertex domain, then develop the GS-IMC approach which biases the reconstruction towards functions that vary little between adjacent vertices for noise reduction. Theoretical result shows that accurate reconstructions can be achieved under mild conditions. For the online setting, we develop a Bayesian extension, i.e., BGS-IMC which considers continuous random Gaussian noise in the graph Fourier domain and builds upon a prediction-correction update algorithm to obtain the unbiased and minimum-variance reconstruction. Both GS-IMC and BGS-IMC have closed-form solutions and thus are highly scalable in large data. Experiments show that our methods achieve state-of-the-art performance on public benchmarks.