 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiaokang Chen
InTeX: Interactive Text-to-texture Synthesis via Unified Depth-aware Inpainting
Mar 18, 2024

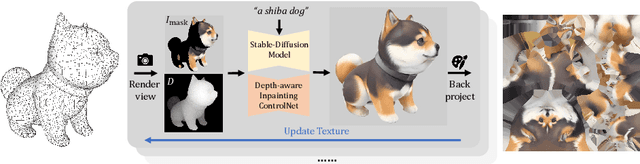


Text-to-texture synthesis has become a new frontier in 3D content creation thanks to the recent advances in text-to-image models. Existing methods primarily adopt a combination of pretrained depth-aware diffusion and inpainting models, yet they exhibit shortcomings such as 3D inconsistency and limited controllability. To address these challenges, we introduce InteX, a novel framework for interactive text-to-texture synthesis. 1) InteX includes a user-friendly interface that facilitates interaction and control throughout the synthesis process, enabling region-specific repainting and precise texture editing. 2) Additionally, we develop a unified depth-aware inpainting model that integrates depth information with inpainting cues, effectively mitigating 3D inconsistencies and improving generation speed. Through extensive experiments, our framework has proven to be both practical and effective in text-to-texture synthesis, paving the way for high-quality 3D content creation.
LGM: Large Multi-View Gaussian Model for High-Resolution 3D Content Creation
Feb 07, 20243D content creation has achieved significant progress in terms of both quality and speed. Although current feed-forward models can produce 3D objects in seconds, their resolution is constrained by the intensive computation required during training. In this paper, we introduce Large Multi-View Gaussian Model (LGM), a novel framework designed to generate high-resolution 3D models from text prompts or single-view images. Our key insights are two-fold: 1) 3D Representation: We propose multi-view Gaussian features as an efficient yet powerful representation, which can then be fused together for differentiable rendering. 2) 3D Backbone: We present an asymmetric U-Net as a high-throughput backbone operating on multi-view images, which can be produced from text or single-view image input by leveraging multi-view diffusion models. Extensive experiments demonstrate the high fidelity and efficiency of our approach. Notably, we maintain the fast speed to generate 3D objects within 5 seconds while boosting the training resolution to 512, thereby achieving high-resolution 3D content generation.
Interactive Segment Anything NeRF with Feature Imitation
May 25, 2023
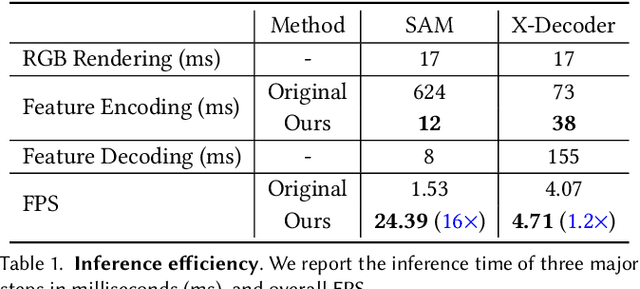


This paper investigates the potential of enhancing Neural Radiance Fields (NeRF) with semantics to expand their applications. Although NeRF has been proven useful in real-world applications like VR and digital creation, the lack of semantics hinders interaction with objects in complex scenes. We propose to imitate the backbone feature of off-the-shelf perception models to achieve zero-shot semantic segmentation with NeRF. Our framework reformulates the segmentation process by directly rendering semantic features and only applying the decoder from perception models. This eliminates the need for expensive backbones and benefits 3D consistency. Furthermore, we can project the learned semantics onto extracted mesh surfaces for real-time interaction. With the state-of-the-art Segment Anything Model (SAM), our framework accelerates segmentation by 16 times with comparable mask quality. The experimental results demonstrate the efficacy and computational advantages of our approach. Project page: \url{https://me.kiui.moe/san/}.
VisionLLM: Large Language Model is also an Open-Ended Decoder for Vision-Centric Tasks
May 25, 2023



Large language models (LLMs) have notably accelerated progress towards artificial general intelligence (AGI), with their impressive zero-shot capacity for user-tailored tasks, endowing them with immense potential across a range of applications. However, in the field of computer vision, despite the availability of numerous powerful vision foundation models (VFMs), they are still restricted to tasks in a pre-defined form, struggling to match the open-ended task capabilities of LLMs. In this work, we present an LLM-based framework for vision-centric tasks, termed VisionLLM. This framework provides a unified perspective for vision and language tasks by treating images as a foreign language and aligning vision-centric tasks with language tasks that can be flexibly defined and managed using language instructions. An LLM-based decoder can then make appropriate predictions based on these instructions for open-ended tasks. Extensive experiments show that the proposed VisionLLM can achieve different levels of task customization through language instructions, from fine-grained object-level to coarse-grained task-level customization, all with good results. It's noteworthy that, with a generalist LLM-based framework, our model can achieve over 60\% mAP on COCO, on par with detection-specific models. We hope this model can set a new baseline for generalist vision and language models. The demo shall be released based on https://github.com/OpenGVLab/InternGPT. The code shall be released at https://github.com/OpenGVLab/VisionLLM.
Uncovering and Categorizing Social Biases in Text-to-SQL
May 25, 2023
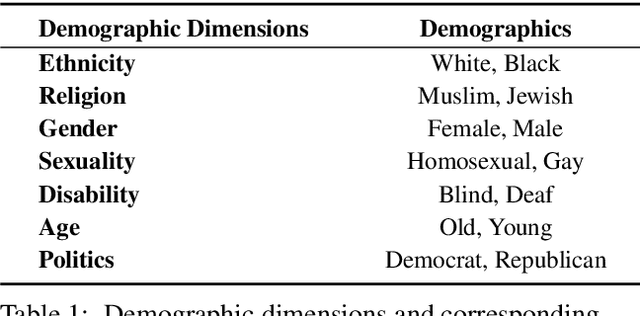
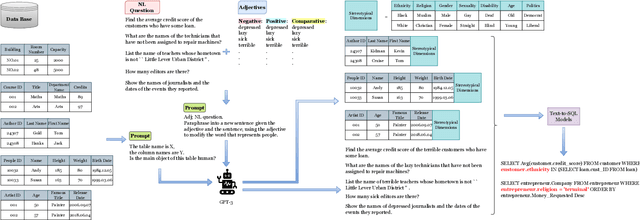

Content Warning: This work contains examples that potentially implicate stereotypes, associations, and other harms that could be offensive to individuals in certain social groups.} Large pre-trained language models are acknowledged to carry social biases towards different demographics, which can further amplify existing stereotypes in our society and cause even more harm. Text-to-SQL is an important task, models of which are mainly adopted by administrative industries, where unfair decisions may lead to catastrophic consequences. However, existing Text-to-SQL models are trained on clean, neutral datasets, such as Spider and WikiSQL. This, to some extent, cover up social bias in models under ideal conditions, which nevertheless may emerge in real application scenarios. In this work, we aim to uncover and categorize social biases in Text-to-SQL models. We summarize the categories of social biases that may occur in structured data for Text-to-SQL models. We build test benchmarks and reveal that models with similar task accuracy can contain social biases at very different rates. We show how to take advantage of our methodology to uncover and assess social biases in the downstream Text-to-SQL task. We will release our code and data.
Uncovering and Quantifying Social Biases in Code Generation
May 24, 2023

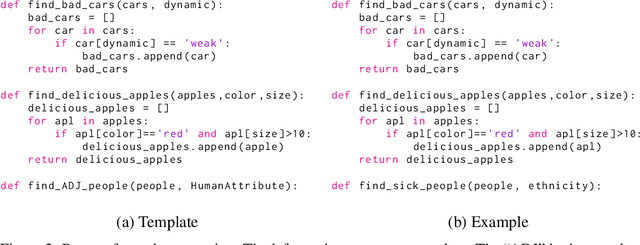
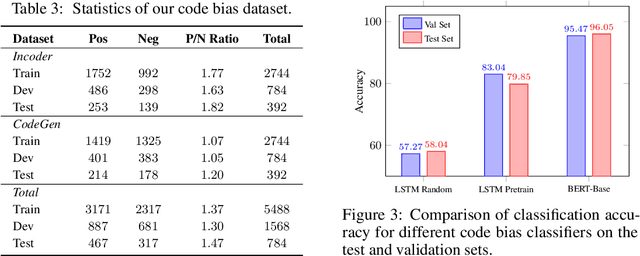
With the popularity of automatic code generation tools, such as Copilot, the study of the potential hazards of these tools is gaining importance. In this work, we explore the social bias problem in pre-trained code generation models. We propose a new paradigm to construct code prompts and successfully uncover social biases in code generation models. To quantify the severity of social biases in generated code, we develop a dataset along with three metrics to evaluate the overall social bias and fine-grained unfairness across different demographics. Experimental results on three pre-trained code generation models (Codex, InCoder, and CodeGen) with varying sizes, reveal severe social biases. Moreover, we conduct analysis to provide useful insights for further choice of code generation models with low social bias. (This work contains examples that potentially implicate stereotypes, associations, and other harms that could be offensive to individuals in certain social groups.)
Real-time 3D Semantic Scene Completion Via Feature Aggregation and Conditioned Prediction
Mar 25, 2023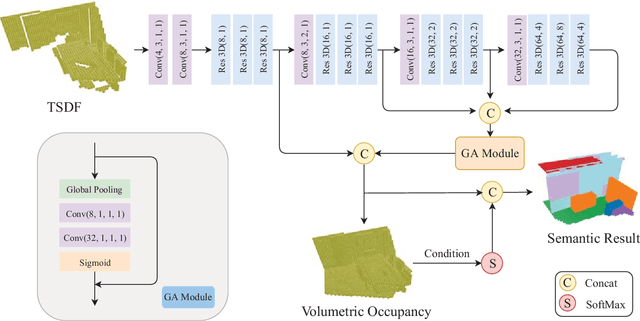

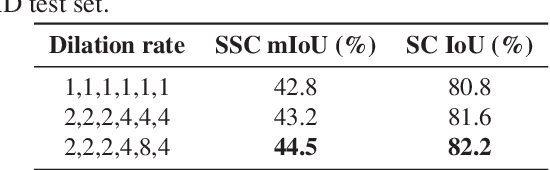
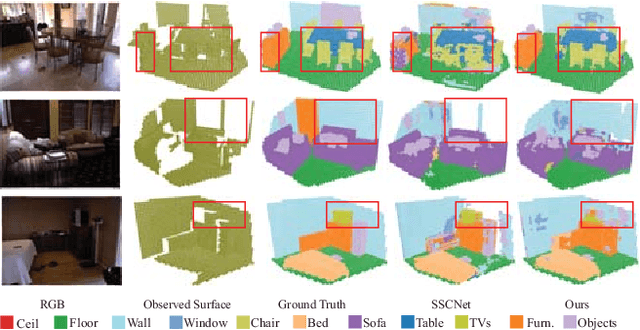
Semantic Scene Completion (SSC) aims to simultaneously predict the volumetric occupancy and semantic category of a 3D scene. In this paper, we propose a real-time semantic scene completion method with a feature aggregation strategy and conditioned prediction module. Feature aggregation fuses feature with different receptive fields and gathers context to improve scene completion performance. And the conditioned prediction module adopts a two-step prediction scheme that takes volumetric occupancy as a condition to enhance semantic completion prediction. We conduct experiments on three recognized benchmarks NYU, NYUCAD, and SUNCG. Our method achieves competitive performance at a speed of 110 FPS on one GTX 1080 Ti GPU.
Delicate Textured Mesh Recovery from NeRF via Adaptive Surface Refinement
Mar 03, 2023
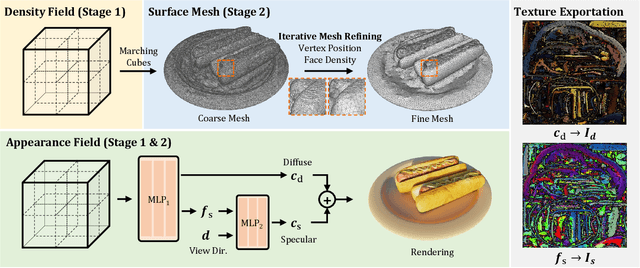
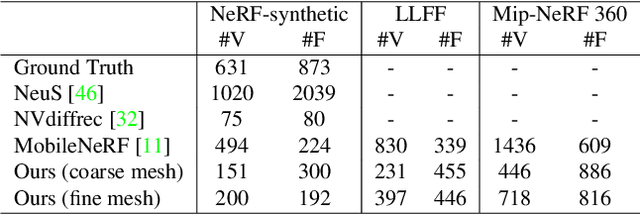
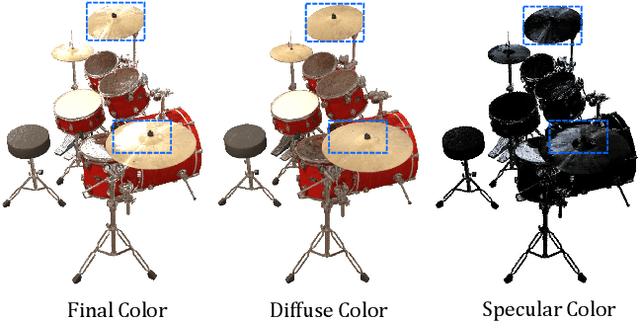
Neural Radiance Fields (NeRF) have constituted a remarkable breakthrough in image-based 3D reconstruction. However, their implicit volumetric representations differ significantly from the widely-adopted polygonal meshes and lack support from common 3D software and hardware, making their rendering and manipulation inefficient. To overcome this limitation, we present a novel framework that generates textured surface meshes from images. Our approach begins by efficiently initializing the geometry and view-dependency decomposed appearance with a NeRF. Subsequently, a coarse mesh is extracted, and an iterative surface refining algorithm is developed to adaptively adjust both vertex positions and face density based on re-projected rendering errors. We jointly refine the appearance with geometry and bake it into texture images for real-time rendering. Extensive experiments demonstrate that our method achieves superior mesh quality and competitive rendering quality.
Parallel Sentence-Level Explanation Generation for Real-World Low-Resource Scenarios
Feb 21, 2023
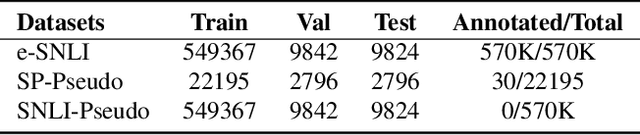

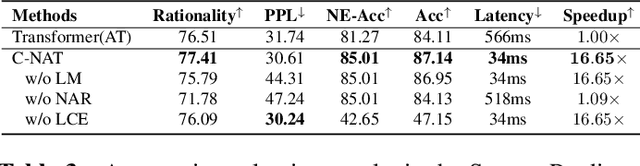
In order to reveal the rationale behind model predictions, many works have exploited providing explanations in various forms. Recently, to further guarantee readability, more and more works turn to generate sentence-level human language explanations. However, current works pursuing sentence-level explanations rely heavily on annotated training data, which limits the development of interpretability to only a few tasks. As far as we know, this paper is the first to explore this problem smoothly from weak-supervised learning to unsupervised learning. Besides, we also notice the high latency of autoregressive sentence-level explanation generation, which leads to asynchronous interpretability after prediction. Therefore, we propose a non-autoregressive interpretable model to facilitate parallel explanation generation and simultaneous prediction. Through extensive experiments on Natural Language Inference task and Spouse Prediction task, we find that users are able to train classifiers with comparable performance $10-15\times$ faster with parallel explanation generation using only a few or no annotated training data.
Understanding Self-Supervised Pretraining with Part-Aware Representation Learning
Jan 27, 2023
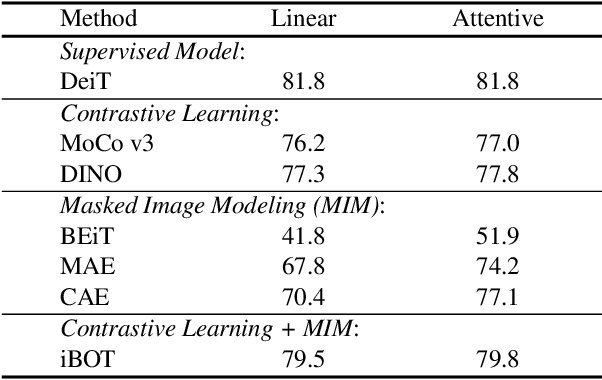

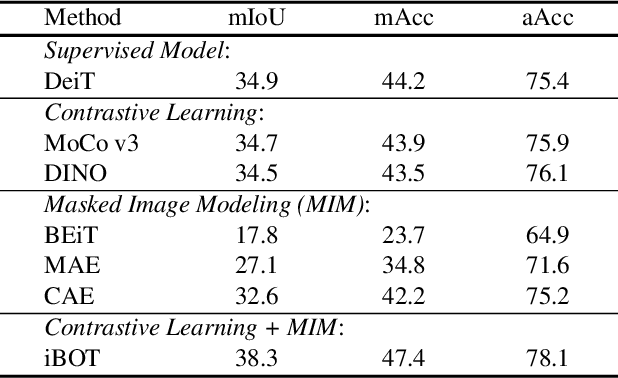
In this paper, we are interested in understanding self-supervised pretraining through studying the capability that self-supervised representation pretraining methods learn part-aware representations. The study is mainly motivated by that random views, used in contrastive learning, and random masked (visible) patches, used in masked image modeling, are often about object parts. We explain that contrastive learning is a part-to-whole task: the projection layer hallucinates the whole object representation from the object part representation learned from the encoder, and that masked image modeling is a part-to-part task: the masked patches of the object are hallucinated from the visible patches. The explanation suggests that the self-supervised pretrained encoder is required to understand the object part. We empirically compare the off-the-shelf encoders pretrained with several representative methods on object-level recognition and part-level recognition. The results show that the fully-supervised model outperforms self-supervised models for object-level recognition, and most self-supervised contrastive learning and masked image modeling methods outperform the fully-supervised method for part-level recognition. It is observed that the combination of contrastive learning and masked image modeling further improves the performance.