 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFares Abawi
Unified Dynamic Scanpath Predictors Outperform Individually Trained Neural Models
May 07, 2024
Previous research on scanpath prediction has mainly focused on group models, disregarding the fact that the scanpaths and attentional behaviors of individuals are diverse. The disregard of these differences is especially detrimental to social human-robot interaction, whereby robots commonly emulate human gaze based on heuristics or predefined patterns. However, human gaze patterns are heterogeneous and varying behaviors can significantly affect the outcomes of such human-robot interactions. To fill this gap, we developed a deep learning-based social cue integration model for saliency prediction to instead predict scanpaths in videos. Our model learned scanpaths by recursively integrating fixation history and social cues through a gating mechanism and sequential attention. We evaluated our approach on gaze datasets of dynamic social scenes, observed under the free-viewing condition. The introduction of fixation history into our models makes it possible to train a single unified model rather than the resource-intensive approach of training individual models for each set of scanpaths. We observed that the late neural integration approach surpasses early fusion when training models on a large dataset, in comparison to a smaller dataset with a similar distribution. Results also indicate that a single unified model, trained on all the observers' scanpaths, performs on par or better than individually trained models. We hypothesize that this outcome is a result of the group saliency representations instilling universal attention in the model, while the supervisory signal and fixation history guide it to learn personalized attentional behaviors, providing the unified model a benefit over individual models due to its implicit representation of universal attention.
Human Impression of Humanoid Robots Mirroring Social Cues
Jan 22, 2024Mirroring non-verbal social cues such as affect or movement can enhance human-human and human-robot interactions in the real world. The robotic platforms and control methods also impact people's perception of human-robot interaction. However, limited studies have compared robot imitation across different platforms and control methods. Our research addresses this gap by conducting two experiments comparing people's perception of affective mirroring between the iCub and Pepper robots and movement mirroring between vision-based iCub control and Inertial Measurement Unit (IMU)-based iCub control. We discovered that the iCub robot was perceived as more humanlike than the Pepper robot when mirroring affect. A vision-based controlled iCub outperformed the IMU-based controlled one in the movement mirroring task. Our findings suggest that different robotic platforms impact people's perception of robots' mirroring during HRI. The control method also contributes to the robot's mirroring performance. Our work sheds light on the design and application of different humanoid robots in the real world.
The Robot in the Room: Influence of Robot Facial Expressions and Gaze on Human-Human-Robot Collaboration
Mar 24, 2023
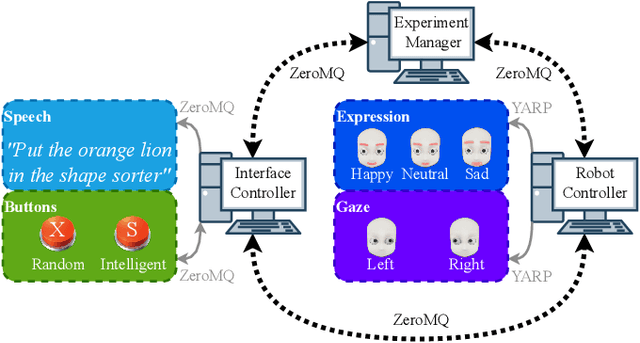
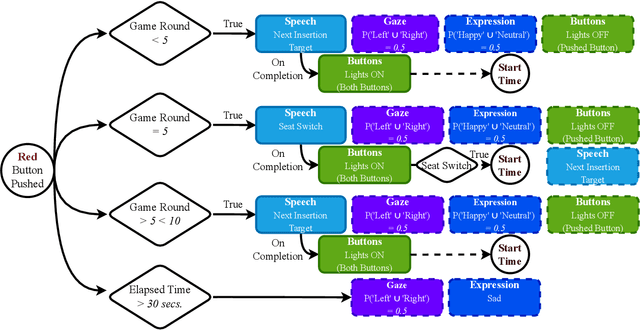
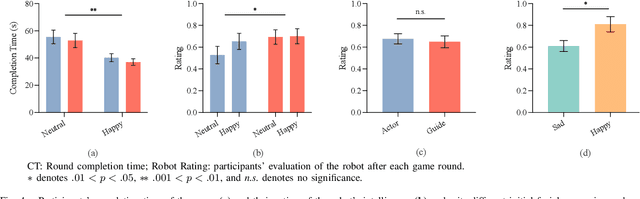
Robot facial expressions and gaze are important factors for enhancing human-robot interaction (HRI), but their effects on human collaboration and perception are not well understood, for instance, in collaborative game scenarios. In this study, we designed a collaborative triadic HRI game scenario, where two participants worked together to insert objects into a shape sorter. One participant assumed the role of a guide. The guide instructed the other participant, who played the role of an actor, by placing occluded objects into the sorter. A humanoid robot issued instructions, observed the interaction, and displayed social cues to elicit changes in the two participants' behavior. We measured human collaboration as a function of task completion time and the participants' perceptions of the robot by rating its behavior as intelligent or random. Participants also evaluated the robot by filling out the Godspeed questionnaire. We found that human collaboration was higher when the robot displayed a happy facial expression at the beginning of the game compared to a neutral facial expression. We also found that participants perceived the robot as more intelligent when it displayed a positive facial expression at the end of the game. The robot's behavior was also perceived as intelligent when directing its gaze toward the guide at the beginning of the interaction, not the actor. These findings provide insights into how robot facial expressions and gaze influence human behavior and perception in collaboration.
Wrapyfi: A Wrapper for Message-Oriented and Robotics Middleware
Feb 22, 2023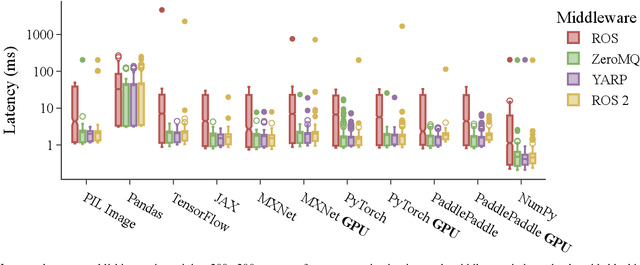
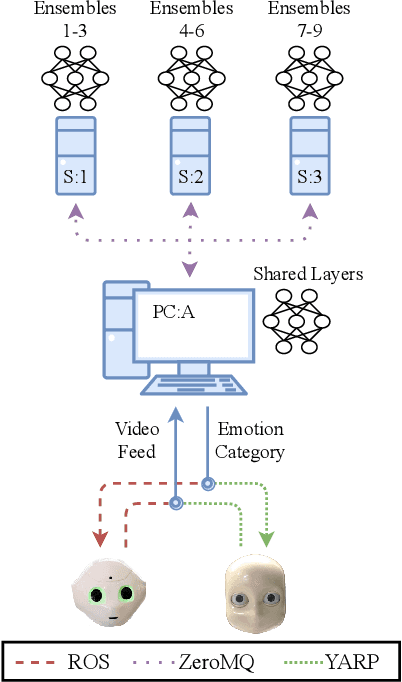

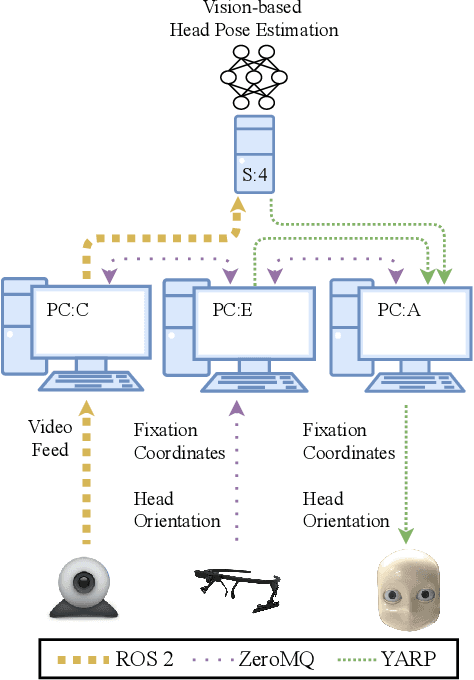
Message-oriented and robotics middleware play an important role in facilitating robot control, abstracting complex functionality and unifying communication patterns across networks of sensors and devices. However, the use of multiple middleware frameworks presents a challenge in integrating different robots within a single system. To address this challenge, we present Wrapyfi, a Python wrapper supporting multiple message-oriented and robotics middleware, including ZeroMQ, YARP, ROS, and ROS 2. Wrapyfi also provides plugins for exchanging deep learning framework data, without additional encoding or preprocessing steps. Using Wrapyfi eases the development of scripts that run on multiple machines, thereby enabling cross-platform communication and workload distribution. We evaluated Wrapyfi in practical settings by conducting two user studies, using multiple sensors transmitting readings to deep learning models, and using robots such as the iCub and Pepper via different middleware. The results demonstrated Wrapyfi's usability in practice allowing for multi-middleware exchanges, and controlled process distribution in a real-world setting. More importantly, we showcase Wrapify's most prominent features by bridging interactions between sensors, deep learning models, and robotic platforms.
Judging by the Look: The Impact of Robot Gaze Strategies on Human Cooperation
Aug 25, 2022
Human eye gaze plays an important role in delivering information, communicating intent, and understanding others' mental states. Previous research shows that a robot's gaze can also affect humans' decision-making and strategy during an interaction. However, limited studies have trained humanoid robots on gaze-based data in human-robot interaction scenarios. Considering gaze impacts the naturalness of social exchanges and alters the decision process of an observer, it should be regarded as a crucial component in human-robot interaction. To investigate the impact of robot gaze on humans, we propose an embodied neural model for performing human-like gaze shifts. This is achieved by extending a social attention model and training it on eye-tracking data, collected by watching humans playing a game. We will compare human behavioral performances in the presence of a robot adopting different gaze strategies in a human-human cooperation game.
GASP: Gated Attention For Saliency Prediction
Jun 09, 2022



Saliency prediction refers to the computational task of modeling overt attention. Social cues greatly influence our attention, consequently altering our eye movements and behavior. To emphasize the efficacy of such features, we present a neural model for integrating social cues and weighting their influences. Our model consists of two stages. During the first stage, we detect two social cues by following gaze, estimating gaze direction, and recognizing affect. These features are then transformed into spatiotemporal maps through image processing operations. The transformed representations are propagated to the second stage (GASP) where we explore various techniques of late fusion for integrating social cues and introduce two sub-networks for directing attention to relevant stimuli. Our experiments indicate that fusion approaches achieve better results for static integration methods, whereas non-fusion approaches for which the influence of each modality is unknown, result in better outcomes when coupled with recurrent models for dynamic saliency prediction. We show that gaze direction and affective representations contribute a prediction to ground-truth correspondence improvement of at least 5% compared to dynamic saliency models without social cues. Furthermore, affective representations improve GASP, supporting the necessity of considering affect-biased attention in predicting saliency.
* International Joint Conference on Artificial Intelligence (IJCAI-21)
A trained humanoid robot can perform human-like crossmodal social attention conflict resolution
Nov 02, 2021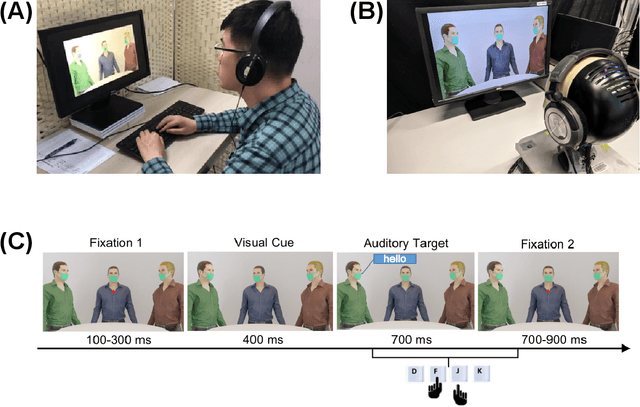
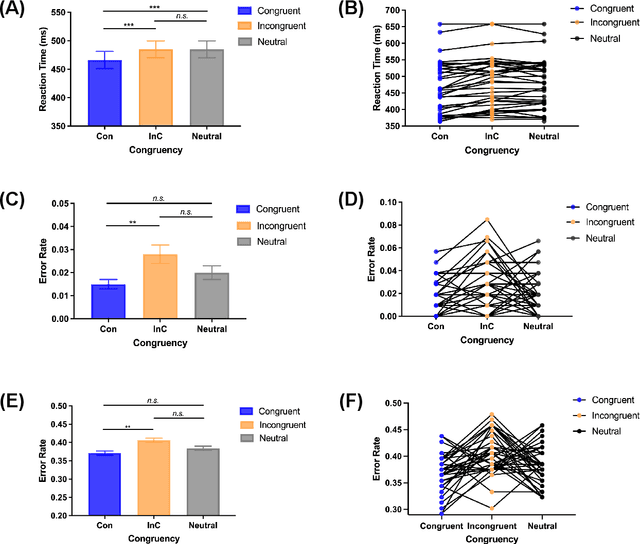

Due to the COVID-19 pandemic, robots could be seen as potential resources in tasks like helping people work remotely, sustaining social distancing, and improving mental or physical health. To enhance human-robot interaction, it is essential for robots to become more socialised, via processing multiple social cues in a complex real-world environment. Our study adopted a neurorobotic paradigm of gaze-triggered audio-visual crossmodal integration to make an iCub robot express human-like social attention responses. At first, a behavioural experiment was conducted on 37 human participants. To improve ecological validity, a round-table meeting scenario with three masked animated avatars was designed with the middle one capable of performing gaze shift, and the other two capable of generating sound. The gaze direction and the sound location are either congruent or incongruent. Masks were used to cover all facial visual cues other than the avatars' eyes. We observed that the avatar's gaze could trigger crossmodal social attention with better human performance in the audio-visual congruent condition than in the incongruent condition. Then, our computational model, GASP, was trained to implement social cue detection, audio-visual saliency prediction, and selective attention. After finishing the model training, the iCub robot was exposed to similar laboratory conditions as human participants, demonstrating that it can replicate similar attention responses as humans regarding the congruency and incongruency performance, while overall the human performance was still superior. Therefore, this interdisciplinary work provides new insights on mechanisms of crossmodal social attention and how it can be modelled in robots in a complex environment.
DRILL: Dynamic Representations for Imbalanced Lifelong Learning
May 18, 2021



Continual or lifelong learning has been a long-standing challenge in machine learning to date, especially in natural language processing (NLP). Although state-of-the-art language models such as BERT have ushered in a new era in this field due to their outstanding performance in multitask learning scenarios, they suffer from forgetting when being exposed to a continuous stream of data with shifting data distributions. In this paper, we introduce DRILL, a novel continual learning architecture for open-domain text classification. DRILL leverages a biologically inspired self-organizing neural architecture to selectively gate latent language representations from BERT in a task-incremental manner. We demonstrate in our experiments that DRILL outperforms current methods in a realistic scenario of imbalanced, non-stationary data without prior knowledge about task boundaries. To the best of our knowledge, DRILL is the first of its kind to use a self-organizing neural architecture for open-domain lifelong learning in NLP.
Enhancing a Neurocognitive Shared Visuomotor Model for Object Identification, Localization, and Grasping With Learning From Auxiliary Tasks
Sep 26, 2020



We present a follow-up study on our unified visuomotor neural model for the robotic tasks of identifying, localizing, and grasping a target object in a scene with multiple objects. Our Retinanet-based model enables end-to-end training of visuomotor abilities in a biologically inspired developmental approach. In our initial implementation, a neural model was able to grasp selected objects from a planar surface. We embodied the model on the NICO humanoid robot. In this follow-up study, we expand the task and the model to reaching for objects in a three-dimensional space with a novel dataset based on augmented reality and a simulation environment. We evaluate the influence of training with auxiliary tasks, i.e., if learning of the primary visuomotor task is supported by learning to classify and locate different objects. We show that the proposed visuomotor model can learn to reach for objects in a three-dimensional space. We analyze the results for biologically-plausible biases based on object locations or properties. We show that the primary visuomotor task can be successfully trained simultaneously with one of the two auxiliary tasks. This is enabled by a complex neurocognitive model with shared and task-specific components, similar to models found in biological systems.