 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStefan Wermter
Inverse Kinematics for Neuro-Robotic Grasping with Humanoid Embodied Agents
Apr 12, 2024
This paper introduces a novel zero-shot motion planning method that allows users to quickly design smooth robot motions in Cartesian space. A B\'ezier curve-based Cartesian plan is transformed into a joint space trajectory by our neuro-inspired inverse kinematics (IK) method CycleIK, for which we enable platform independence by scaling it to arbitrary robot designs. The motion planner is evaluated on the physical hardware of the two humanoid robots NICO and NICOL in a human-in-the-loop grasping scenario. Our method is deployed with an embodied agent that is a large language model (LLM) at its core. We generalize the embodied agent, that was introduced for NICOL, to also be embodied by NICO. The agent can execute a discrete set of physical actions and allows the user to verbally instruct various different robots. We contribute a grasping primitive to its action space that allows for precise manipulation of household objects. The new CycleIK method is compared to popular numerical IK solvers and state-of-the-art neural IK methods in simulation and is shown to be competitive with or outperform all evaluated methods when the algorithm runtime is very short. The grasping primitive is evaluated on both NICOL and NICO robots with a reported grasp success of 72% to 82% for each robot, respectively.
Comparing Apples to Oranges: LLM-powered Multimodal Intention Prediction in an Object Categorization Task
Apr 12, 2024Intention-based Human-Robot Interaction (HRI) systems allow robots to perceive and interpret user actions to proactively interact with humans and adapt to their behavior. Therefore, intention prediction is pivotal in creating a natural interactive collaboration between humans and robots. In this paper, we examine the use of Large Language Models (LLMs) for inferring human intention during a collaborative object categorization task with a physical robot. We introduce a hierarchical approach for interpreting user non-verbal cues, like hand gestures, body poses, and facial expressions and combining them with environment states and user verbal cues captured using an existing Automatic Speech Recognition (ASR) system. Our evaluation demonstrates the potential of LLMs to interpret non-verbal cues and to combine them with their context-understanding capabilities and real-world knowledge to support intention prediction during human-robot interaction.
Diffusing in Someone Else's Shoes: Robotic Perspective Taking with Diffusion
Apr 11, 2024Humanoid robots can benefit from their similarity to the human shape by learning from humans. When humans teach other humans how to perform actions, they often demonstrate the actions and the learning human can try to imitate the demonstration. Being able to mentally transfer from a demonstration seen from a third-person perspective to how it should look from a first-person perspective is fundamental for this ability in humans. As this is a challenging task, it is often simplified for robots by creating a demonstration in the first-person perspective. Creating these demonstrations requires more effort but allows for an easier imitation. We introduce a novel diffusion model aimed at enabling the robot to directly learn from the third-person demonstrations. Our model is capable of learning and generating the first-person perspective from the third-person perspective by translating the size and rotations of objects and the environment between two perspectives. This allows us to utilise the benefits of easy-to-produce third-person demonstrations and easy-to-imitate first-person demonstrations. The model can either represent the first-person perspective in an RGB image or calculate the joint values. Our approach significantly outperforms other image-to-image models in this task.
Large Language Models for Orchestrating Bimanual Robots
Apr 02, 2024Although there has been rapid progress in endowing robots with the ability to solve complex manipulation tasks, generating control policies for bimanual robots to solve tasks involving two hands is still challenging because of the difficulties in effective temporal and spatial coordination. With emergent abilities in terms of step-by-step reasoning and in-context learning, Large Language Models (LLMs) have taken control of a variety of robotic tasks. However, the nature of language communication via a single sequence of discrete symbols makes LLM-based coordination in continuous space a particular challenge for bimanual tasks. To tackle this challenge for the first time by an LLM, we present LAnguage-model-based Bimanual ORchestration (LABOR), an agent utilizing an LLM to analyze task configurations and devise coordination control policies for addressing long-horizon bimanual tasks. In the simulated environment, the LABOR agent is evaluated through several everyday tasks on the NICOL humanoid robot. Reported success rates indicate that overall coordination efficiency is close to optimal performance, while the analysis of failure causes, classified into spatial and temporal coordination and skill selection, shows that these vary over tasks. The project website can be found at http://labor-agent.github.io
Human Impression of Humanoid Robots Mirroring Social Cues
Jan 22, 2024Mirroring non-verbal social cues such as affect or movement can enhance human-human and human-robot interactions in the real world. The robotic platforms and control methods also impact people's perception of human-robot interaction. However, limited studies have compared robot imitation across different platforms and control methods. Our research addresses this gap by conducting two experiments comparing people's perception of affective mirroring between the iCub and Pepper robots and movement mirroring between vision-based iCub control and Inertial Measurement Unit (IMU)-based iCub control. We discovered that the iCub robot was perceived as more humanlike than the Pepper robot when mirroring affect. A vision-based controlled iCub outperformed the IMU-based controlled one in the movement mirroring task. Our findings suggest that different robotic platforms impact people's perception of robots' mirroring during HRI. The control method also contributes to the robot's mirroring performance. Our work sheds light on the design and application of different humanoid robots in the real world.
Robotic Imitation of Human Actions
Jan 16, 2024Imitation can allow us to quickly gain an understanding of a new task. Through a demonstration, we can gain direct knowledge about which actions need to be performed and which goals they have. In this paper, we introduce a new approach to imitation learning that tackles the challenges of a robot imitating a human, such as the change in perspective and body schema. Our approach can use a single human demonstration to abstract information about the demonstrated task, and use that information to generalise and replicate it. We facilitate this ability by a new integration of two state-of-the-art methods: a diffusion action segmentation model to abstract temporal information from the demonstration and an open vocabulary object detector for spatial information. Furthermore, we refine the abstracted information and use symbolic reasoning to create an action plan utilising inverse kinematics, to allow the robot to imitate the demonstrated action.
Causal State Distillation for Explainable Reinforcement Learning
Dec 30, 2023Reinforcement learning (RL) is a powerful technique for training intelligent agents, but understanding why these agents make specific decisions can be quite challenging. This lack of transparency in RL models has been a long-standing problem, making it difficult for users to grasp the reasons behind an agent's behaviour. Various approaches have been explored to address this problem, with one promising avenue being reward decomposition (RD). RD is appealing as it sidesteps some of the concerns associated with other methods that attempt to rationalize an agent's behaviour in a post-hoc manner. RD works by exposing various facets of the rewards that contribute to the agent's objectives during training. However, RD alone has limitations as it primarily offers insights based on sub-rewards and does not delve into the intricate cause-and-effect relationships that occur within an RL agent's neural model. In this paper, we present an extension of RD that goes beyond sub-rewards to provide more informative explanations. Our approach is centred on a causal learning framework that leverages information-theoretic measures for explanation objectives that encourage three crucial properties of causal factors: \emph{causal sufficiency}, \emph{sparseness}, and \emph{orthogonality}. These properties help us distill the cause-and-effect relationships between the agent's states and actions or rewards, allowing for a deeper understanding of its decision-making processes. Our framework is designed to generate local explanations and can be applied to a wide range of RL tasks with multiple reward channels. Through a series of experiments, we demonstrate that our approach offers more meaningful and insightful explanations for the agent's action selections.
Read Between the Layers: Leveraging Intra-Layer Representations for Rehearsal-Free Continual Learning with Pre-Trained Models
Dec 13, 2023We address the Continual Learning (CL) problem, where a model has to learn a sequence of tasks from non-stationary distributions while preserving prior knowledge as it encounters new experiences. With the advancement of foundation models, CL research has shifted focus from the initial learning-from-scratch paradigm to the use of generic features from large-scale pre-training. However, existing approaches to CL with pre-trained models only focus on separating the class-specific features from the final representation layer and neglect the power of intermediate representations that capture low- and mid-level features naturally more invariant to domain shifts. In this work, we propose LayUP, a new class-prototype-based approach to continual learning that leverages second-order feature statistics from multiple intermediate layers of a pre-trained network. Our method is conceptually simple, does not require any replay buffer, and works out of the box with any foundation model. LayUP improves over the state-of-the-art on four of the seven class-incremental learning settings at a considerably reduced memory and computational footprint compared with the next best baseline. Our results demonstrate that fully exhausting the representational capacities of pre-trained models in CL goes far beyond their final embeddings.
Accelerating Reinforcement Learning of Robotic Manipulations via Feedback from Large Language Models
Nov 04, 2023Reinforcement Learning (RL) plays an important role in the robotic manipulation domain since it allows self-learning from trial-and-error interactions with the environment. Still, sample efficiency and reward specification seriously limit its potential. One possible solution involves learning from expert guidance. However, obtaining a human expert is impractical due to the high cost of supervising an RL agent, and developing an automatic supervisor is a challenging endeavor. Large Language Models (LLMs) demonstrate remarkable abilities to provide human-like feedback on user inputs in natural language. Nevertheless, they are not designed to directly control low-level robotic motions, as their pretraining is based on vast internet data rather than specific robotics data. In this paper, we introduce the Lafite-RL (Language agent feedback interactive Reinforcement Learning) framework, which enables RL agents to learn robotic tasks efficiently by taking advantage of LLMs' timely feedback. Our experiments conducted on RLBench tasks illustrate that, with simple prompt design in natural language, the Lafite-RL agent exhibits improved learning capabilities when guided by an LLM. It outperforms the baseline in terms of both learning efficiency and success rate, underscoring the efficacy of the rewards provided by an LLM.
Visually Grounded Continual Language Learning with Selective Specialization
Oct 24, 2023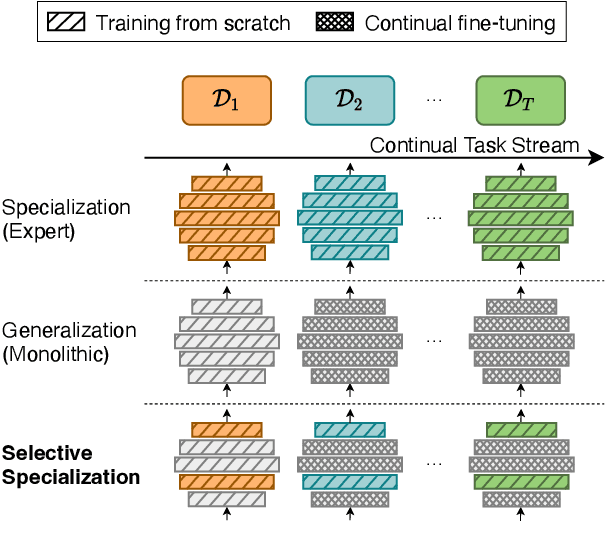
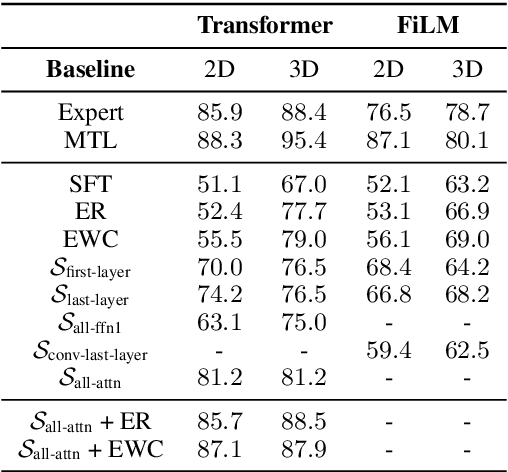
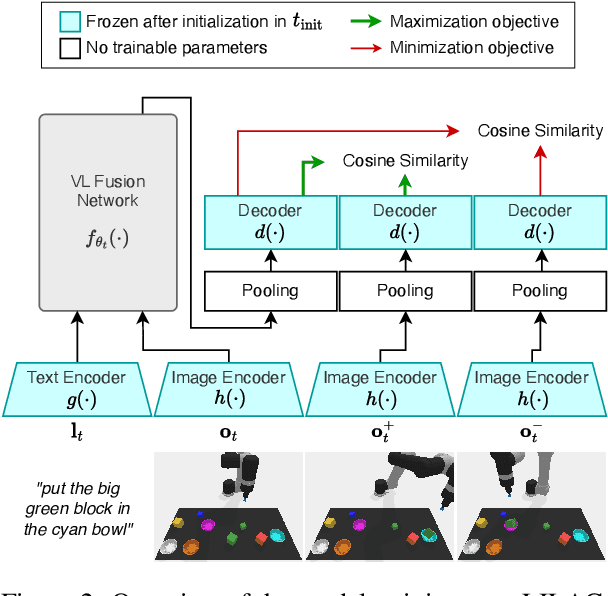
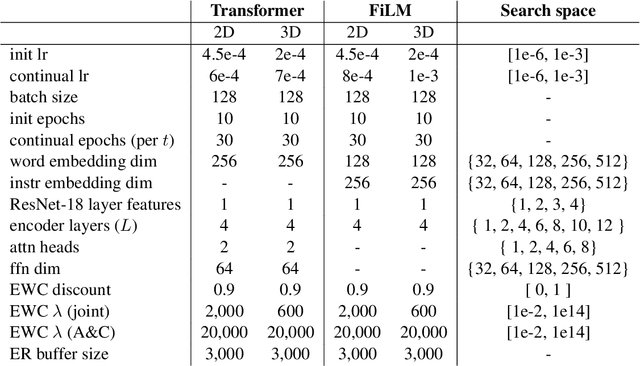
A desirable trait of an artificial agent acting in the visual world is to continually learn a sequence of language-informed tasks while striking a balance between sufficiently specializing in each task and building a generalized knowledge for transfer. Selective specialization, i.e., a careful selection of model components to specialize in each task, is a strategy to provide control over this trade-off. However, the design of selection strategies requires insights on the role of each model component in learning rather specialized or generalizable representations, which poses a gap in current research. Thus, our aim with this work is to provide an extensive analysis of selection strategies for visually grounded continual language learning. Due to the lack of suitable benchmarks for this purpose, we introduce two novel diagnostic datasets that provide enough control and flexibility for a thorough model analysis. We assess various heuristics for module specialization strategies as well as quantifiable measures for two different types of model architectures. Finally, we design conceptually simple approaches based on our analysis that outperform common continual learning baselines. Our results demonstrate the need for further efforts towards better aligning continual learning algorithms with the learning behaviors of individual model parts.