 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederico Fusco
No-Regret Learning in Bilateral Trade via Global Budget Balance
Oct 18, 2023




Bilateral trade revolves around the challenge of facilitating transactions between two strategic agents -- a seller and a buyer -- both of whom have a private valuations for the item. We study the online version of the problem, in which at each time step a new seller and buyer arrive. The learner's task is to set a price for each agent, without any knowledge about their valuations. The sequence of sellers and buyers is chosen by an oblivious adversary. In this setting, known negative results rule out the possibility of designing algorithms with sublinear regret when the learner has to guarantee budget balance for each iteration. In this paper, we introduce the notion of global budget balance, which requires the agent to be budget balance only over the entire time horizon. By requiring global budget balance, we provide the first no-regret algorithms for bilateral trade with adversarial inputs under various feedback models. First, we show that in the full-feedback model the learner can guarantee $\tilde{O}(\sqrt{T})$ regret against the best fixed prices in hindsight, which is order-wise optimal. Then, in the case of partial feedback models, we provide an algorithm guaranteeing a $\tilde{O}(T^{3/4})$ regret upper bound with one-bit feedback, which we complement with a nearly-matching lower bound. Finally, we investigate how these results vary when measuring regret using an alternative benchmark.
The Role of Transparency in Repeated First-Price Auctions with Unknown Valuations
Jul 14, 2023



We study the problem of regret minimization for a single bidder in a sequence of first-price auctions where the bidder knows the item's value only if the auction is won. Our main contribution is a complete characterization, up to logarithmic factors, of the minimax regret in terms of the auction's transparency, which regulates the amount of information on competing bids disclosed by the auctioneer at the end of each auction. Our results hold under different assumptions (stochastic, adversarial, and their smoothed variants) on the environment generating the bidder's valuations and competing bids. These minimax rates reveal how the interplay between transparency and the nature of the environment affects how fast one can learn to bid optimally in first-price auctions.
Bandits with Replenishable Knapsacks: the Best of both Worlds
Jun 14, 2023The bandits with knapsack (BwK) framework models online decision-making problems in which an agent makes a sequence of decisions subject to resource consumption constraints. The traditional model assumes that each action consumes a non-negative amount of resources and the process ends when the initial budgets are fully depleted. We study a natural generalization of the BwK framework which allows non-monotonic resource utilization, i.e., resources can be replenished by a positive amount. We propose a best-of-both-worlds primal-dual template that can handle any online learning problem with replenishment for which a suitable primal regret minimizer exists. In particular, we provide the first positive results for the case of adversarial inputs by showing that our framework guarantees a constant competitive ratio $\alpha$ when $B=\Omega(T)$ or when the possible per-round replenishment is a positive constant. Moreover, under a stochastic input model, our algorithm yields an instance-independent $\tilde{O}(T^{1/2})$ regret bound which complements existing instance-dependent bounds for the same setting. Finally, we provide applications of our framework to some economic problems of practical relevance.
Fully Dynamic Submodular Maximization over Matroids
May 31, 2023Maximizing monotone submodular functions under a matroid constraint is a classic algorithmic problem with multiple applications in data mining and machine learning. We study this classic problem in the fully dynamic setting, where elements can be both inserted and deleted in real-time. Our main result is a randomized algorithm that maintains an efficient data structure with an $\tilde{O}(k^2)$ amortized update time (in the number of additions and deletions) and yields a $4$-approximate solution, where $k$ is the rank of the matroid.
Fairness in Streaming Submodular Maximization over a Matroid Constraint
May 24, 2023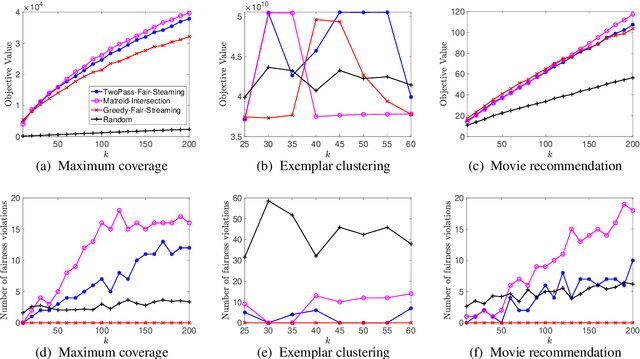
Streaming submodular maximization is a natural model for the task of selecting a representative subset from a large-scale dataset. If datapoints have sensitive attributes such as gender or race, it becomes important to enforce fairness to avoid bias and discrimination. This has spurred significant interest in developing fair machine learning algorithms. Recently, such algorithms have been developed for monotone submodular maximization under a cardinality constraint. In this paper, we study the natural generalization of this problem to a matroid constraint. We give streaming algorithms as well as impossibility results that provide trade-offs between efficiency, quality and fairness. We validate our findings empirically on a range of well-known real-world applications: exemplar-based clustering, movie recommendation, and maximum coverage in social networks.
Repeated Bilateral Trade Against a Smoothed Adversary
Feb 21, 2023



We study repeated bilateral trade where an adaptive $\sigma$-smooth adversary generates the valuations of sellers and buyers. We provide a complete characterization of the regret regimes for fixed-price mechanisms under different feedback models in the two cases where the learner can post either the same or different prices to buyers and sellers. We begin by showing that the minimax regret after $T$ rounds is of order $\sqrt{T}$ in the full-feedback scenario. Under partial feedback, any algorithm that has to post the same price to buyers and sellers suffers worst-case linear regret. However, when the learner can post two different prices at each round, we design an algorithm enjoying regret of order $T^{3/4}$ ignoring log factors. We prove that this rate is optimal by presenting a surprising $T^{3/4}$ lower bound, which is the main technical contribution of the paper.
An $α$-regret analysis of Adversarial Bilateral Trade
Oct 13, 2022



We study sequential bilateral trade where sellers and buyers valuations are completely arbitrary (i.e., determined by an adversary). Sellers and buyers are strategic agents with private valuations for the good and the goal is to design a mechanism that maximizes efficiency (or gain from trade) while being incentive compatible, individually rational and budget balanced. In this paper we consider gain from trade which is harder to approximate than social welfare. We consider a variety of feedback scenarios and distinguish the cases where the mechanism posts one price and when it can post different prices for buyer and seller. We show several surprising results about the separation between the different scenarios. In particular we show that (a) it is impossible to achieve sublinear $\alpha$-regret for any $\alpha<2$, (b) but with full feedback sublinear $2$-regret is achievable (c) with a single price and partial feedback one cannot get sublinear $\alpha$ regret for any constant $\alpha$ (d) nevertheless, posting two prices even with one-bit feedback achieves sublinear $2$-regret, and (e) there is a provable separation in the $2$-regret bounds between full and partial feedback.
Learning on the Edge: Online Learning with Stochastic Feedback Graphs
Oct 09, 2022The framework of feedback graphs is a generalization of sequential decision-making with bandit or full information feedback. In this work, we study an extension where the directed feedback graph is stochastic, following a distribution similar to the classical Erd\H{o}s-R\'enyi model. Specifically, in each round every edge in the graph is either realized or not with a distinct probability for each edge. We prove nearly optimal regret bounds of order $\min\bigl\{\min_{\varepsilon} \sqrt{(\alpha_\varepsilon/\varepsilon) T},\, \min_{\varepsilon} (\delta_\varepsilon/\varepsilon)^{1/3} T^{2/3}\bigr\}$ (ignoring logarithmic factors), where $\alpha_{\varepsilon}$ and $\delta_{\varepsilon}$ are graph-theoretic quantities measured on the support of the stochastic feedback graph $\mathcal{G}$ with edge probabilities thresholded at $\varepsilon$. Our result, which holds without any preliminary knowledge about $\mathcal{G}$, requires the learner to observe only the realized out-neighborhood of the chosen action. When the learner is allowed to observe the realization of the entire graph (but only the losses in the out-neighborhood of the chosen action), we derive a more efficient algorithm featuring a dependence on weighted versions of the independence and weak domination numbers that exhibits improved bounds for some special cases.
Deletion Robust Non-Monotone Submodular Maximization over Matroids
Aug 16, 2022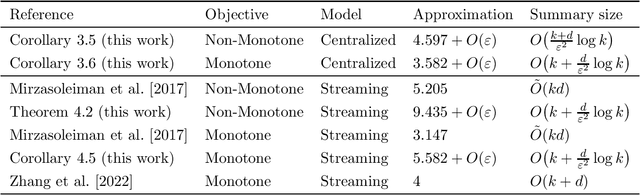
Maximizing a submodular function is a fundamental task in machine learning and in this paper we study the deletion robust version of the problem under the classic matroids constraint. Here the goal is to extract a small size summary of the dataset that contains a high value independent set even after an adversary deleted some elements. We present constant-factor approximation algorithms, whose space complexity depends on the rank $k$ of the matroid and the number $d$ of deleted elements. In the centralized setting we present a $(4.597+O(\varepsilon))$-approximation algorithm with summary size $O( \frac{k+d}{\varepsilon^2}\log \frac{k}{\varepsilon})$ that is improved to a $(3.582+O(\varepsilon))$-approximation with $O(k + \frac{d}{\varepsilon^2}\log \frac{k}{\varepsilon})$ summary size when the objective is monotone. In the streaming setting we provide a $(9.435 + O(\varepsilon))$-approximation algorithm with summary size and memory $O(k + \frac{d}{\varepsilon^2}\log \frac{k}{\varepsilon})$; the approximation factor is then improved to $(5.582+O(\varepsilon))$ in the monotone case.
Deletion Robust Submodular Maximization over Matroids
Jan 31, 2022



Maximizing a monotone submodular function is a fundamental task in machine learning. In this paper, we study the deletion robust version of the problem under the classic matroids constraint. Here the goal is to extract a small size summary of the dataset that contains a high value independent set even after an adversary deleted some elements. We present constant-factor approximation algorithms, whose space complexity depends on the rank $k$ of the matroid and the number $d$ of deleted elements. In the centralized setting we present a $(3.582+O(\varepsilon))$-approximation algorithm with summary size $O(k + \frac{d \log k}{\varepsilon^2})$. In the streaming setting we provide a $(5.582+O(\varepsilon))$-approximation algorithm with summary size and memory $O(k + \frac{d \log k}{\varepsilon^2})$. We complement our theoretical results with an in-depth experimental analysis showing the effectiveness of our algorithms on real-world datasets.