 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSilvio Lattanzi
A Scalable Algorithm for Individually Fair K-means Clustering
Feb 09, 2024
We present a scalable algorithm for the individually fair ($p$, $k$)-clustering problem introduced by Jung et al. and Mahabadi et al. Given $n$ points $P$ in a metric space, let $\delta(x)$ for $x\in P$ be the radius of the smallest ball around $x$ containing at least $n / k$ points. A clustering is then called individually fair if it has centers within distance $\delta(x)$ of $x$ for each $x\in P$. While good approximation algorithms are known for this problem no efficient practical algorithms with good theoretical guarantees have been presented. We design the first fast local-search algorithm that runs in ~$O(nk^2)$ time and obtains a bicriteria $(O(1), 6)$ approximation. Then we show empirically that not only is our algorithm much faster than prior work, but it also produces lower-cost solutions.
A quasi-polynomial time algorithm for Multi-Dimensional Scaling via LP hierarchies
Nov 29, 2023Multi-dimensional Scaling (MDS) is a family of methods for embedding pair-wise dissimilarities between $n$ objects into low-dimensional space. MDS is widely used as a data visualization tool in the social and biological sciences, statistics, and machine learning. We study the Kamada-Kawai formulation of MDS: given a set of non-negative dissimilarities $\{d_{i,j}\}_{i , j \in [n]}$ over $n$ points, the goal is to find an embedding $\{x_1,\dots,x_n\} \subset \mathbb{R}^k$ that minimizes \[ \text{OPT} = \min_{x} \mathbb{E}_{i,j \in [n]} \left[ \left(1-\frac{\|x_i - x_j\|}{d_{i,j}}\right)^2 \right] \] Despite its popularity, our theoretical understanding of MDS is extremely limited. Recently, Demaine, Hesterberg, Koehler, Lynch, and Urschel (arXiv:2109.11505) gave the first approximation algorithm with provable guarantees for Kamada-Kawai, which achieves an embedding with cost $\text{OPT} +\epsilon$ in $n^2 \cdot 2^{\tilde{\mathcal{O}}(k \Delta^4 / \epsilon^2)}$ time, where $\Delta$ is the aspect ratio of the input dissimilarities. In this work, we give the first approximation algorithm for MDS with quasi-polynomial dependency on $\Delta$: for target dimension $k$, we achieve a solution with cost $\mathcal{O}(\text{OPT}^{ \hspace{0.04in}1/k } \cdot \log(\Delta/\epsilon) )+ \epsilon$ in time $n^{ \mathcal{O}(1)} \cdot 2^{\tilde{\mathcal{O}}( k^2 (\log(\Delta)/\epsilon)^{k/2 + 1} ) }$. Our approach is based on a novel analysis of a conditioning-based rounding scheme for the Sherali-Adams LP Hierarchy. Crucially, our analysis exploits the geometry of low-dimensional Euclidean space, allowing us to avoid an exponential dependence on the aspect ratio $\Delta$. We believe our geometry-aware treatment of the Sherali-Adams Hierarchy is an important step towards developing general-purpose techniques for efficient metric optimization algorithms.
Multi-Swap $k$-Means++
Sep 28, 2023The $k$-means++ algorithm of Arthur and Vassilvitskii (SODA 2007) is often the practitioners' choice algorithm for optimizing the popular $k$-means clustering objective and is known to give an $O(\log k)$-approximation in expectation. To obtain higher quality solutions, Lattanzi and Sohler (ICML 2019) proposed augmenting $k$-means++ with $O(k \log \log k)$ local search steps obtained through the $k$-means++ sampling distribution to yield a $c$-approximation to the $k$-means clustering problem, where $c$ is a large absolute constant. Here we generalize and extend their local search algorithm by considering larger and more sophisticated local search neighborhoods hence allowing to swap multiple centers at the same time. Our algorithm achieves a $9 + \varepsilon$ approximation ratio, which is the best possible for local search. Importantly we show that our approach yields substantial practical improvements, we show significant quality improvements over the approach of Lattanzi and Sohler (ICML 2019) on several datasets.
Fully Dynamic Submodular Maximization over Matroids
May 31, 2023Maximizing monotone submodular functions under a matroid constraint is a classic algorithmic problem with multiple applications in data mining and machine learning. We study this classic problem in the fully dynamic setting, where elements can be both inserted and deleted in real-time. Our main result is a randomized algorithm that maintains an efficient data structure with an $\tilde{O}(k^2)$ amortized update time (in the number of additions and deletions) and yields a $4$-approximate solution, where $k$ is the rank of the matroid.
On Classification Thresholds for Graph Attention with Edge Features
Oct 18, 2022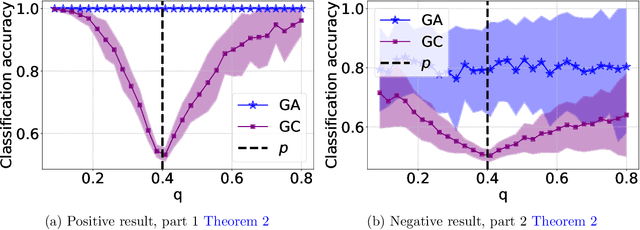
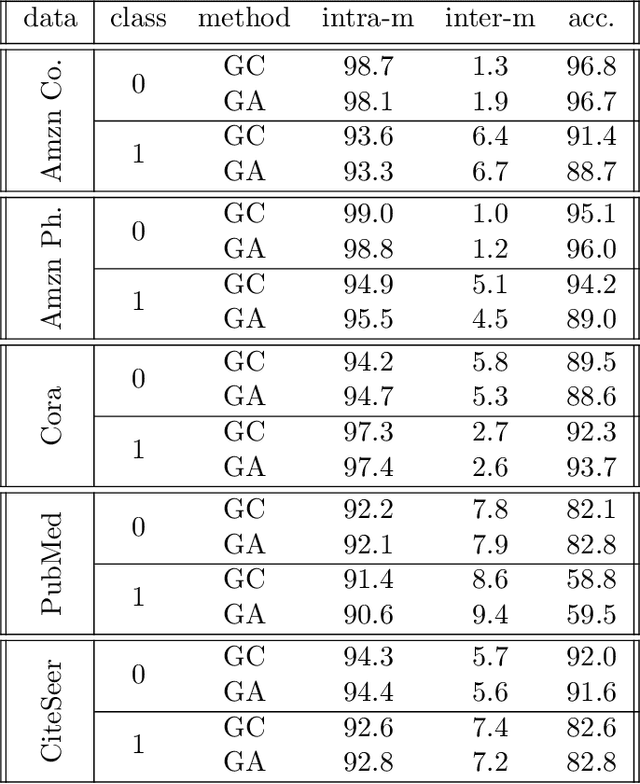
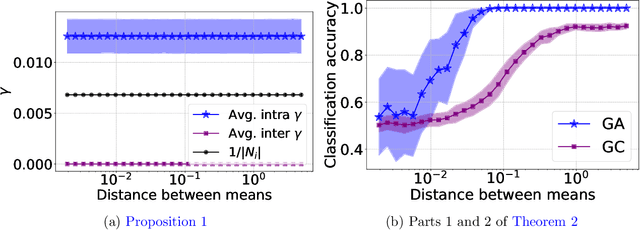
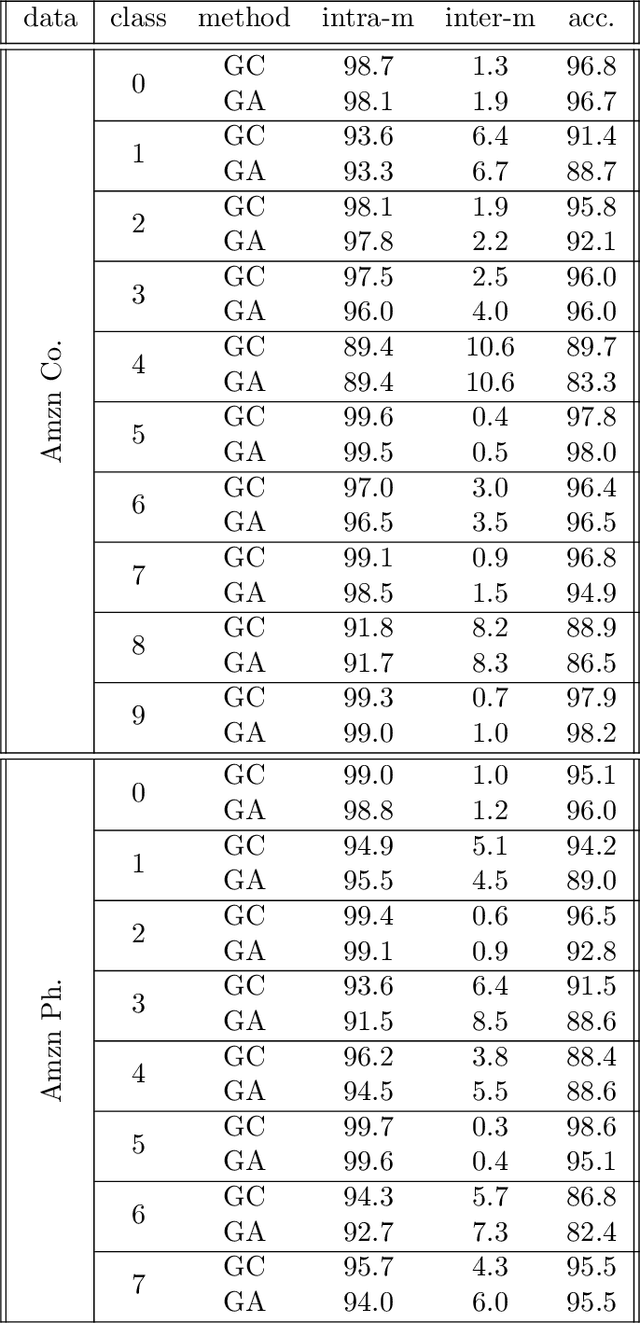
The recent years we have seen the rise of graph neural networks for prediction tasks on graphs. One of the dominant architectures is graph attention due to its ability to make predictions using weighted edge features and not only node features. In this paper we analyze, theoretically and empirically, graph attention networks and their ability of correctly labelling nodes in a classic classification task. More specifically, we study the performance of graph attention on the classic contextual stochastic block model (CSBM). In CSBM the nodes and edge features are obtained from a mixture of Gaussians and the edges from a stochastic block model. We consider a general graph attention mechanism that takes random edge features as input to determine the attention coefficients. We study two cases, in the first one, when the edge features are noisy, we prove that the majority of the attention coefficients are up to a constant uniform. This allows us to prove that graph attention with edge features is not better than simple graph convolution for achieving perfect node classification. Second, we prove that when the edge features are clean graph attention can distinguish intra- from inter-edges and this makes graph attention better than classic graph convolution.
Active Learning of Classifiers with Label and Seed Queries
Sep 08, 2022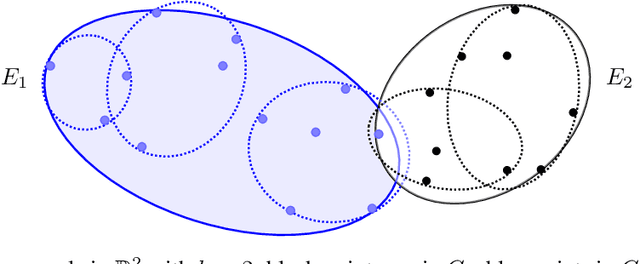
We study exact active learning of binary and multiclass classifiers with margin. Given an $n$-point set $X \subset \mathbb{R}^m$, we want to learn any unknown classifier on $X$ whose classes have finite strong convex hull margin, a new notion extending the SVM margin. In the standard active learning setting, where only label queries are allowed, learning a classifier with strong convex hull margin $\gamma$ requires in the worst case $\Omega\big(1+\frac{1}{\gamma}\big)^{(m-1)/2}$ queries. On the other hand, using the more powerful seed queries (a variant of equivalence queries), the target classifier could be learned in $O(m \log n)$ queries via Littlestone's Halving algorithm; however, Halving is computationally inefficient. In this work we show that, by carefully combining the two types of queries, a binary classifier can be learned in time $\operatorname{poly}(n+m)$ using only $O(m^2 \log n)$ label queries and $O\big(m \log \frac{m}{\gamma}\big)$ seed queries; the result extends to $k$-class classifiers at the price of a $k!k^2$ multiplicative overhead. Similar results hold when the input points have bounded bit complexity, or when only one class has strong convex hull margin against the rest. We complement the upper bounds by showing that in the worst case any algorithm needs $\Omega\big(k m \log \frac{1}{\gamma}\big)$ seed and label queries to learn a $k$-class classifier with strong convex hull margin $\gamma$.
Deletion Robust Non-Monotone Submodular Maximization over Matroids
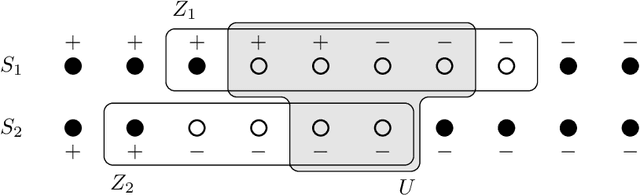
Aug 16, 2022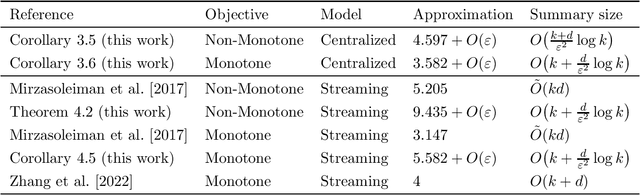
Maximizing a submodular function is a fundamental task in machine learning and in this paper we study the deletion robust version of the problem under the classic matroids constraint. Here the goal is to extract a small size summary of the dataset that contains a high value independent set even after an adversary deleted some elements. We present constant-factor approximation algorithms, whose space complexity depends on the rank $k$ of the matroid and the number $d$ of deleted elements. In the centralized setting we present a $(4.597+O(\varepsilon))$-approximation algorithm with summary size $O( \frac{k+d}{\varepsilon^2}\log \frac{k}{\varepsilon})$ that is improved to a $(3.582+O(\varepsilon))$-approximation with $O(k + \frac{d}{\varepsilon^2}\log \frac{k}{\varepsilon})$ summary size when the objective is monotone. In the streaming setting we provide a $(9.435 + O(\varepsilon))$-approximation algorithm with summary size and memory $O(k + \frac{d}{\varepsilon^2}\log \frac{k}{\varepsilon})$; the approximation factor is then improved to $(5.582+O(\varepsilon))$ in the monotone case.
TF-GNN: Graph Neural Networks in TensorFlow
Jul 07, 2022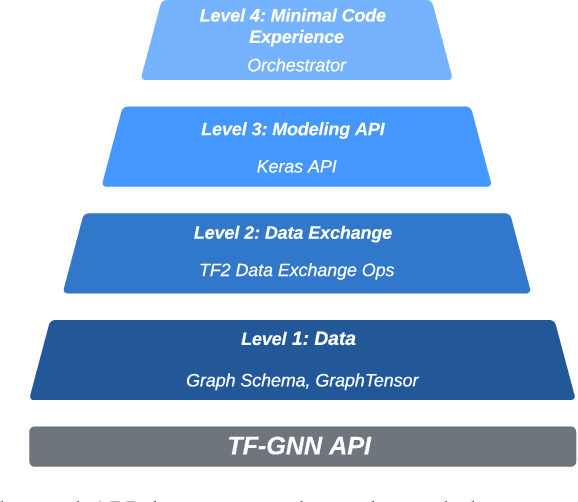
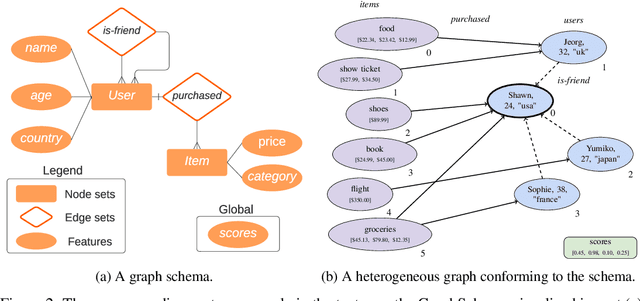
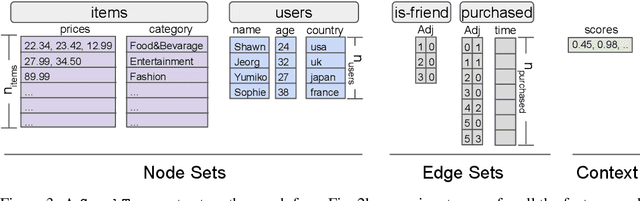
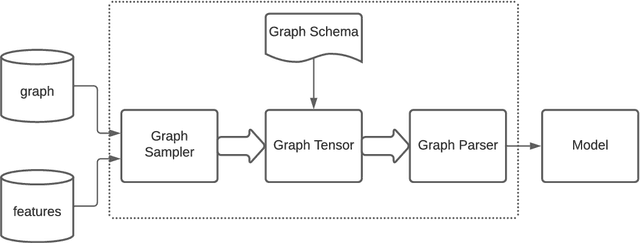
TensorFlow GNN (TF-GNN) is a scalable library for Graph Neural Networks in TensorFlow. It is designed from the bottom up to support the kinds of rich heterogeneous graph data that occurs in today's information ecosystems. Many production models at Google use TF-GNN and it has been recently released as an open source project. In this paper, we describe the TF-GNN data model, its Keras modeling API, and relevant capabilities such as graph sampling, distributed training, and accelerator support.
Scalable Differentially Private Clustering via Hierarchically Separated Trees
Jun 17, 2022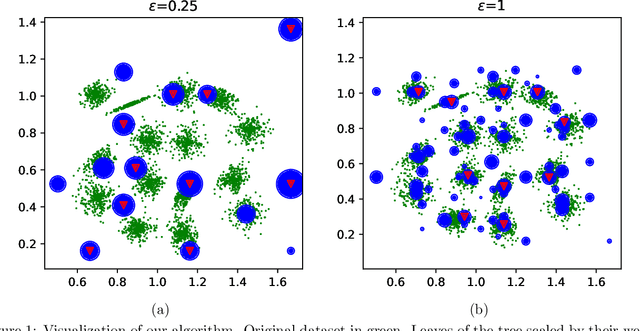
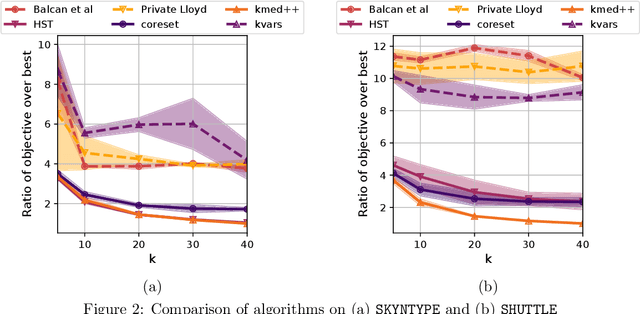
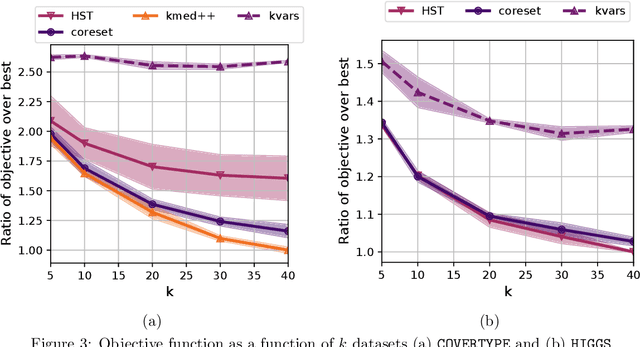
We study the private $k$-median and $k$-means clustering problem in $d$ dimensional Euclidean space. By leveraging tree embeddings, we give an efficient and easy to implement algorithm, that is empirically competitive with state of the art non private methods. We prove that our method computes a solution with cost at most $O(d^{3/2}\log n)\cdot OPT + O(k d^2 \log^2 n / \epsilon^2)$, where $\epsilon$ is the privacy guarantee. (The dimension term, $d$, can be replaced with $O(\log k)$ using standard dimension reduction techniques.) Although the worst-case guarantee is worse than that of state of the art private clustering methods, the algorithm we propose is practical, runs in near-linear, $\tilde{O}(nkd)$, time and scales to tens of millions of points. We also show that our method is amenable to parallelization in large-scale distributed computing environments. In particular we show that our private algorithms can be implemented in logarithmic number of MPC rounds in the sublinear memory regime. Finally, we complement our theoretical analysis with an empirical evaluation demonstrating the algorithm's efficiency and accuracy in comparison to other privacy clustering baselines.
Near-Optimal Correlation Clustering with Privacy
Mar 02, 2022Correlation clustering is a central problem in unsupervised learning, with applications spanning community detection, duplicate detection, automated labelling and many more. In the correlation clustering problem one receives as input a set of nodes and for each node a list of co-clustering preferences, and the goal is to output a clustering that minimizes the disagreement with the specified nodes' preferences. In this paper, we introduce a simple and computationally efficient algorithm for the correlation clustering problem with provable privacy guarantees. Our approximation guarantees are stronger than those shown in prior work and are optimal up to logarithmic factors.